 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Combined Detection and Classification of TEM Defects via Mask-Conditioned Latent Diffusion Augmentation
Jun 01, 2026Analyzing microstructural defects in transmission electron microscopy (TEM) images, particularly in irradiated metal alloys, is often limited by the availability of high-quality, labeled data. To address this, we introduce a generative data augmentation approach using a mask-conditioned latent diffusion model (LDM) for synthesizing realistic TEM images with controllable, automatically labeled multi-class defect masks. Without requiring manual annotations for generation, our method enables the creation of synthetic image-mask pairs by sampling distributions learned from experimental masks. These generated data were used to augment small experimental datasets of varying sizes (10, 50, and 100 labeled experimental images) to train a Mask Regional Convolutional Neural Network (R-CNN) model for defect detection and classification. Our results show that generative augmentation yields small overall model performance improvements, with up to a 0.02 gain in the harmonic mean of detection and classification F1 scores. However, we also find that the relative contributions to detection and classification improvement depend on the specific train/test data split. These findings highlight the potential of targeted generative models to enhance deep learning performance in data-scarce microscopy-based image quantification tasks.
Leveraging Vision Capabilities of Multimodal LLMs for Automated Data Extraction from Plots
Mar 16, 2025



Automated data extraction from research texts has been steadily improving, with the emergence of large language models (LLMs) accelerating progress even further. Extracting data from plots in research papers, however, has been such a complex task that it has predominantly been confined to manual data extraction. We show that current multimodal large language models, with proper instructions and engineered workflows, are capable of accurately extracting data from plots. This capability is inherent to the pretrained models and can be achieved with a chain-of-thought sequence of zero-shot engineered prompts we call PlotExtract, without the need to fine-tune. We demonstrate PlotExtract here and assess its performance on synthetic and published plots. We consider only plots with two axes in this analysis. For plots identified as extractable, PlotExtract finds points with over 90% precision (and around 90% recall) and errors in x and y position of around 5% or lower. These results prove that multimodal LLMs are a viable path for high-throughput data extraction for plots and in many circumstances can replace the current manual methods of data extraction.
Beyond designer's knowledge: Generating materials design hypotheses via large language models
Sep 10, 2024


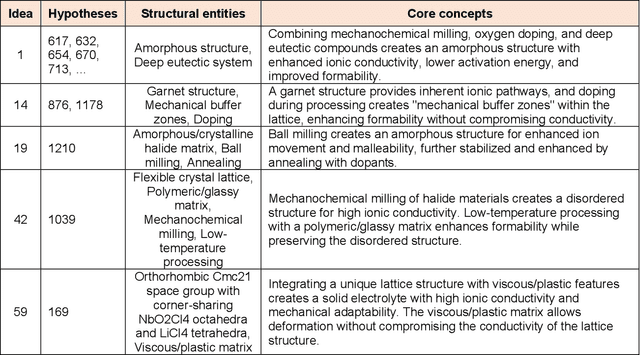
Materials design often relies on human-generated hypotheses, a process inherently limited by cognitive constraints such as knowledge gaps and limited ability to integrate and extract knowledge implications, particularly when multidisciplinary expertise is required. This work demonstrates that large language models (LLMs), coupled with prompt engineering, can effectively generate non-trivial materials hypotheses by integrating scientific principles from diverse sources without explicit design guidance by human experts. These include design ideas for high-entropy alloys with superior cryogenic properties and halide solid electrolytes with enhanced ionic conductivity and formability. These design ideas have been experimentally validated in high-impact publications in 2023 not available in the LLM training data, demonstrating the LLM's ability to generate highly valuable and realizable innovative ideas not established in the literature. Our approach primarily leverages materials system charts encoding processing-structure-property relationships, enabling more effective data integration by condensing key information from numerous papers, and evaluation and categorization of numerous hypotheses for human cognition, both through the LLM. This LLM-driven approach opens the door to new avenues of artificial intelligence-driven materials discovery by accelerating design, democratizing innovation, and expanding capabilities beyond the designer's direct knowledge.
Regression with Large Language Models for Materials and Molecular Property Prediction
Sep 09, 2024



We demonstrate the ability of large language models (LLMs) to perform material and molecular property regression tasks, a significant deviation from the conventional LLM use case. We benchmark the Large Language Model Meta AI (LLaMA) 3 on several molecular properties in the QM9 dataset and 24 materials properties. Only composition-based input strings are used as the model input and we fine tune on only the generative loss. We broadly find that LLaMA 3, when fine-tuned using the SMILES representation of molecules, provides useful regression results which can rival standard materials property prediction models like random forest or fully connected neural networks on the QM9 dataset. Not surprisingly, LLaMA 3 errors are 5-10x higher than those of the state-of-the-art models that were trained using far more granular representation of molecules (e.g., atom types and their coordinates) for the same task. Interestingly, LLaMA 3 provides improved predictions compared to GPT-3.5 and GPT-4o. This work highlights the versatility of LLMs, suggesting that LLM-like generative models can potentially transcend their traditional applications to tackle complex physical phenomena, thus paving the way for future research and applications in chemistry, materials science and other scientific domains.
Extracting Accurate Materials Data from Research Papers with Conversational Language Models and Prompt Engineering -- Example of ChatGPT
Mar 07, 2023There has been a growing effort to replace hand extraction of data from research papers with automated data extraction based on natural language processing (NLP), language models (LMs), and recently, large language models (LLMs). Although these methods enable efficient extraction of data from large sets of research papers, they require a significant amount of up-front effort, expertise, and coding. In this work we propose the ChatExtract method that can fully automate very accurate data extraction with essentially no initial effort or background using an advanced conversational LLM (or AI). ChatExtract consists of a set of engineered prompts applied to a conversational LLM that both identify sentences with data, extract data, and assure its correctness through a series of follow-up questions. These follow-up questions address a critical challenge associated with LLMs - their tendency to provide factually inaccurate responses. ChatExtract can be applied with any conversational LLMs and yields very high quality data extraction. In tests on materials data we find precision and recall both over 90% from the best conversational LLMs, likely rivaling or exceeding human accuracy in many cases. We demonstrate that the exceptional performance is enabled by the information retention in a conversational model combined with purposeful redundancy and introducing uncertainty through follow-up prompts. These results suggest that approaches similar to ChatExtract, due to their simplicity, transferability and accuracy are likely to replace other methods of data extraction in the near future.
Flexible, Model-Agnostic Method for Materials Data Extraction from Text Using General Purpose Language Models
Feb 09, 2023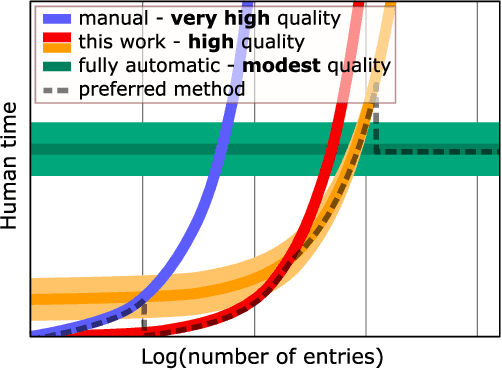
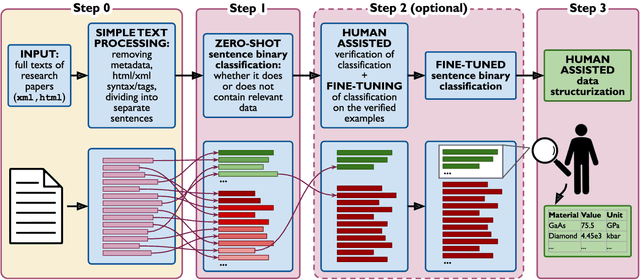
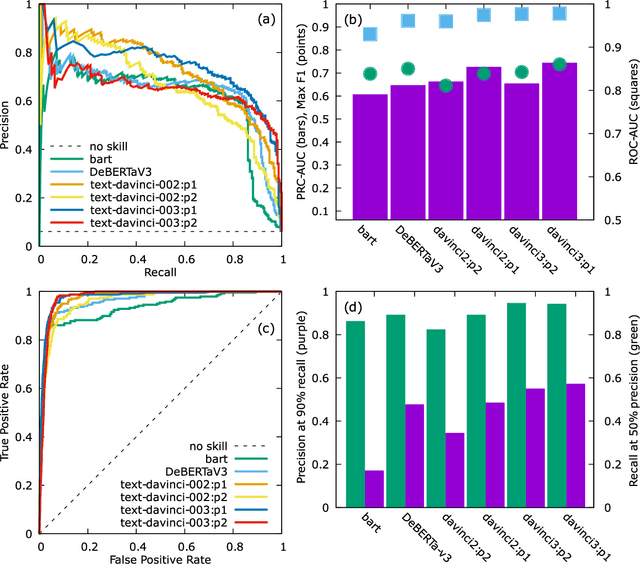
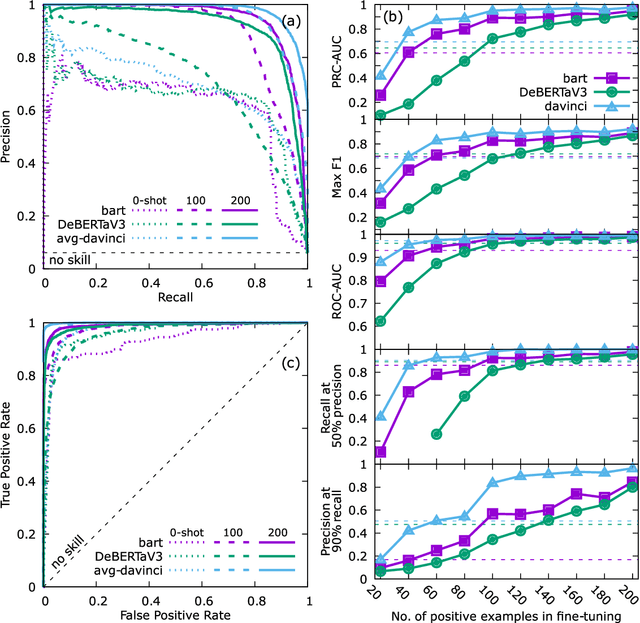
Accurate and comprehensive material databases extracted from research papers are critical for materials science and engineering but require significant human effort to develop. In this paper we present a simple method of extracting materials data from full texts of research papers suitable for quickly developing modest-sized databases. The method requires minimal to no coding, prior knowledge about the extracted property, or model training, and provides high recall and almost perfect precision in the resultant database. The method is fully automated except for one human-assisted step, which typically requires just a few hours of human labor. The method builds on top of natural language processing and large general language models but can work with almost any such model. The language models GPT-3/3.5, bart and DeBERTaV3 are evaluated here for comparison. We provide a detailed detailed analysis of the methods performance in extracting bulk modulus data, obtaining up to 90% precision at 96% recall, depending on the amount of human effort involved. We then demonstrate the methods broader effectiveness by developing a database of critical cooling rates for metallic glasses.