 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAXAL-NET: Finetuned Edge ASR Across 19 African Languages
Jun 01, 2026We evaluate whether compact domain-specialized ASR models can outperform massively multilingual foundation models for conversational African speech across 19 languages in the WAXAL corpus. Fine-tuned edge models achieve a macro-averaged WER of $38.0\%$ compared to $64.9\%$ for the best zero-shot baseline, a $26.9$ percentage-point reduction using models $3-40\times$ smaller. Results confirm that domain specialization dominates scale for spontaneous African speech. Cross-domain evaluation shows that fine-tuned models recover usable performance on out-of-distribution (OOD) speech, while zero-shot models regain an advantage when the test domain matches their pretraining distribution. A distributed native-speaker audit across all surveyed languages produces a linguistically-grounded error taxonomy, showing that CTC and autoregressive architectures behave differently across language families. We further show that WER alone misrepresents performance for syllabary-script languages where CER/WER ratios reveal substantially higher character-level accuracy than headline WER suggests. Finally, to contribute to future African ASR research, we release all model weights, fine-tuning and evaluation scripts, and a cleaned WAXAL subset covering all $19$ languages.
Mining Large Language Models for Low-Resource Language Data: Comparing Elicitation Strategies for Hausa and Fongbe
Apr 14, 2026Large language models (LLMs) are trained on data contributed by low-resource language communities, yet the linguistic knowledge encoded in these models remains accessible only through commercial APIs. This paper investigates whether strategic prompting can extract usable text data from LLMs for two West African languages: Hausa (Afroasiatic, approximately 80 million speakers) and Fongbe (Niger-Congo, approximately 2 million speakers). We systematically compare six elicitation task types across two commercial LLMs (GPT-4o Mini and Gemini 2.5 Flash). GPT-4o Mini extracts 6-41 times more usable target-language words per API call than Gemini. Optimal strategies differ by language: Hausa benefits from functional text and dialogue, while Fongbe requires constrained generation prompts. We release all generated corpora and code.
When Does Data Augmentation Help? Evaluating LLM and Back-Translation Methods for Hausa and Fongbe NLP
Apr 14, 2026Data scarcity limits NLP development for low-resource African languages. We evaluate two data augmentation methods -- LLM-based generation (Gemini 2.5 Flash) and back-translation (NLLB-200) -- for Hausa and Fongbe, two West African languages that differ substantially in LLM generation quality. We assess augmentation on named entity recognition (NER) and part-of-speech (POS) tagging using MasakhaNER 2.0 and MasakhaPOS benchmarks. Our results reveal that augmentation effectiveness depends on task type rather than language or LLM quality alone. For NER, neither method improves over baseline for either language; LLM augmentation reduces Hausa NER by 0.24% F1 and Fongbe NER by 1.81% F1. For POS tagging, LLM augmentation improves Fongbe by 0.33% accuracy, while back-translation improves Hausa by 0.17%; back-translation reduces Fongbe POS by 0.35% and has negligible effect on Hausa POS. The same LLM-generated synthetic data produces opposite effects across tasks for Fongbe -- hurting NER while helping POS -- suggesting task structure governs augmentation outcomes more than synthetic data quality. These findings challenge the assumption that LLM generation quality predicts augmentation success, and provide actionable guidance: data augmentation should be treated as a task-specific intervention rather than a universally beneficial preprocessing step.
Budget-Xfer: Budget-Constrained Source Language Selection for Cross-Lingual Transfer to African Languages
Mar 29, 2026Cross-lingual transfer learning enables NLP for low-resource languages by leveraging labeled data from higher-resource sources, yet existing comparisons of source language selection strategies do not control for total training data, confounding language selection effects with data quantity effects. We introduce Budget-Xfer, a framework that formulates multi-source cross-lingual transfer as a budget-constrained resource allocation problem. Given a fixed annotation budget B, our framework jointly optimizes which source languages to include and how much data to allocate from each. We evaluate four allocation strategies across named entity recognition and sentiment analysis for three African target languages (Hausa, Yoruba, Swahili) using two multilingual models, conducting 288 experiments. Our results show that (1) multi-source transfer significantly outperforms single-source transfer (Cohen's d = 0.80 to 1.98), driven by a structural budget underutilization bottleneck; (2) among multi-source strategies, differences are modest and non-significant; and (3) the value of embedding similarity as a selection proxy is task-dependent, with random selection outperforming similarity-based selection for NER but not sentiment analysis.
Location-Aware Pretraining for Medical Difference Visual Question Answering
Mar 05, 2026Unlike conventional single-image models, differential medical VQA frameworks process multiple images to identify differences, mirroring the comparative diagnostic workflow of radiologists. However, standard vision encoders trained on contrastive or classification objectives often fail to capture the subtle visual variations necessary for distinguishing disease progression from acquisition differences. To address this limitation, we introduce a pretraining framework that incorporates location-aware tasks, including automatic referring expressions (AREF), grounded captioning (GCAP), and conditional automatic referring expressions (CAREF). These specific tasks enable the vision encoder to learn fine-grained, spatially grounded visual representations that are often overlooked by traditional pre-training methods. We subsequently integrate this enhanced vision encoder with a language model to perform medical difference VQA. Experimental results demonstrate that our approach achieves state-of-the-art performance in detecting and reasoning about clinically relevant changes in chest X-ray images.
QuantLRM: Quantization of Large Reasoning Models via Fine-Tuning Signals
Jan 31, 2026Weight-only quantization is important for compressing Large Language Models (LLMs). Inspired by the spirit of classical magnitude pruning, we study whether the magnitude of weight updates during reasoning-incentivized fine-tuning can provide valuable signals for quantizing Large Reasoning Models (LRMs). We hypothesize that the smallest and largest weight updates during fine-tuning are more important than those of intermediate magnitude, a phenomenon we term "protecting both ends". Upon hypothesis validation, we introduce QuantLRM, which stands for weight quantization of LRMs via fine-tuning signals. We fit simple restricted quadratic functions on weight updates to protect both ends. By multiplying the average quadratic values with the count of zero weight updates of channels, we compute channel importance that is more effective than using activation or second-order information. We run QuantLRM to quantize various fine-tuned models (including supervised, direct preference optimization, and reinforcement learning fine-tuning) over four reasoning benchmarks (AIME-120, FOLIO, temporal sequences, and GPQA-Diamond) and empirically find that QuantLRM delivers a consistent improvement for LRMs quantization, with an average improvement of 6.55% on a reinforcement learning fine-tuned model. Also supporting non-fine-tuned LRMs, QuantLRM gathers effective signals via pseudo-fine-tuning, which greatly enhances its applicability.
Can Embedding Similarity Predict Cross-Lingual Transfer? A Systematic Study on African Languages
Jan 06, 2026Cross-lingual transfer is essential for building NLP systems for low-resource African languages, but practitioners lack reliable methods for selecting source languages. We systematically evaluate five embedding similarity metrics across 816 transfer experiments spanning three NLP tasks, three African-centric multilingual models, and 12 languages from four language families. We find that cosine gap and retrieval-based metrics (P@1, CSLS) reliably predict transfer success ($ρ= 0.4-0.6$), while CKA shows negligible predictive power ($ρ\approx 0.1$). Critically, correlation signs reverse when pooling across models (Simpson's Paradox), so practitioners must validate per-model. Embedding metrics achieve comparable predictive power to URIEL linguistic typology. Our results provide concrete guidance for source language selection and highlight the importance of model-specific analysis.
TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora
Jun 12, 2025The rapid evolution of scientific fields introduces challenges in organizing and retrieving scientific literature. While expert-curated taxonomies have traditionally addressed this need, the process is time-consuming and expensive. Furthermore, recent automatic taxonomy construction methods either (1) over-rely on a specific corpus, sacrificing generalizability, or (2) depend heavily on the general knowledge of large language models (LLMs) contained within their pre-training datasets, often overlooking the dynamic nature of evolving scientific domains. Additionally, these approaches fail to account for the multi-faceted nature of scientific literature, where a single research paper may contribute to multiple dimensions (e.g., methodology, new tasks, evaluation metrics, benchmarks). To address these gaps, we propose TaxoAdapt, a framework that dynamically adapts an LLM-generated taxonomy to a given corpus across multiple dimensions. TaxoAdapt performs iterative hierarchical classification, expanding both the taxonomy width and depth based on corpus' topical distribution. We demonstrate its state-of-the-art performance across a diverse set of computer science conferences over the years to showcase its ability to structure and capture the evolution of scientific fields. As a multidimensional method, TaxoAdapt generates taxonomies that are 26.51% more granularity-preserving and 50.41% more coherent than the most competitive baselines judged by LLMs.
How to Backdoor the Knowledge Distillation
Apr 30, 2025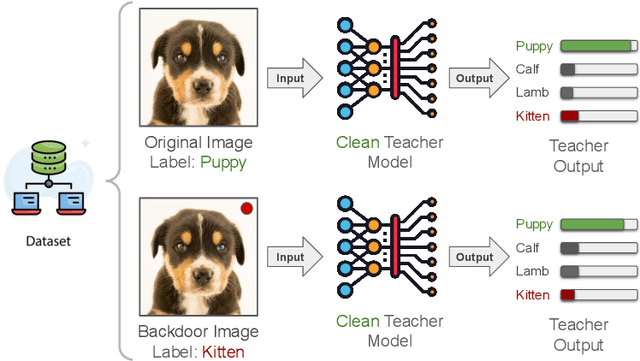
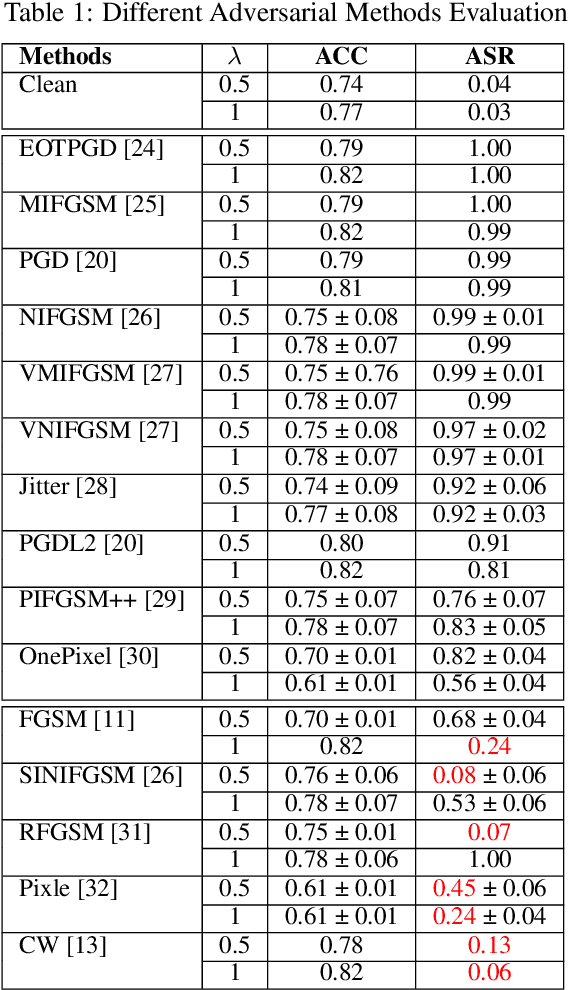


Knowledge distillation has become a cornerstone in modern machine learning systems, celebrated for its ability to transfer knowledge from a large, complex teacher model to a more efficient student model. Traditionally, this process is regarded as secure, assuming the teacher model is clean. This belief stems from conventional backdoor attacks relying on poisoned training data with backdoor triggers and attacker-chosen labels, which are not involved in the distillation process. Instead, knowledge distillation uses the outputs of a clean teacher model to guide the student model, inherently preventing recognition or response to backdoor triggers as intended by an attacker. In this paper, we challenge this assumption by introducing a novel attack methodology that strategically poisons the distillation dataset with adversarial examples embedded with backdoor triggers. This technique allows for the stealthy compromise of the student model while maintaining the integrity of the teacher model. Our innovative approach represents the first successful exploitation of vulnerabilities within the knowledge distillation process using clean teacher models. Through extensive experiments conducted across various datasets and attack settings, we demonstrate the robustness, stealthiness, and effectiveness of our method. Our findings reveal previously unrecognized vulnerabilities and pave the way for future research aimed at securing knowledge distillation processes against backdoor attacks.
When Reasoning Meets Compression: Benchmarking Compressed Large Reasoning Models on Complex Reasoning Tasks
Apr 02, 2025Recent open-source large reasoning models (LRMs) exhibit strong performance on complex reasoning tasks, but their large parameter count makes them prohibitively expensive for individuals. The compression of large language models (LLMs) offers an effective solution to reduce cost of computational resources. However, systematic studies on the performance of compressed LLMs in complex reasoning tasks, especially for LRMs, are lacking. Most works on quantization and pruning focus on preserving language modeling performance, while existing distillation works do not comprehensively benchmark student models based on reasoning difficulty or compression impact on knowledge and reasoning. In this paper, we benchmark compressed DeepSeek-R1 models on four different reasoning datasets (AIME 2024, FOLIO, Temporal Sequences of BIG-Bench Hard, and MuSiQue), ranging from mathematical to multihop reasoning, using quantization, distillation, and pruning methods. We benchmark 2.51-, 1.73-, and 1.58-bit R1 models that adopt dynamic quantization. We also benchmark distilled R1 models that are based on LLaMA or Qwen and run SparseGPT on them to obtain various sparsity levels. Studying the performance and behavior of compressed LRMs, we report their performance scores and test-time compute (number of tokens spent on each question). Notably, using MuSiQue, we find that parameter count has a much greater impact on LRMs' knowledge memorization than on their reasoning capability, which can inform the choice of compression techniques. Through our empirical analysis of test-time compute, we find that shorter model outputs generally achieve better performance than longer ones across several benchmarks for both R1 and its compressed variants, highlighting the need for more concise reasoning chains.