 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Benchmark Datasets Should Be Contamination-Resistant
May 19, 2026Benchmark datasets are critical for reproducible, reliable, and discriminative evaluation of LLMs. However, recent studies reveal that many benchmark datasets are included in pretraining corpora, i.e., $\textit{contaminated}$, which diminishes their value as reliable measures of model generalization. In this paper, we argue that benchmark datasets should be $\textit{contamination-resistant}$, i.e., $\textit{unlearnable}$, but support $\textit{inference}$. To accomplish this, we first highlight the wide prevalence of benchmark dataset contamination and outline the properties of contamination-resistant datasets. Second, we highlight how the asymmetry between the inference and training pipelines in the Transformer architecture can be leveraged to support contamination-resistance. Third, we outline mathematical advancements to make these datasets interoperable across various LLM architectures. Based on the above, we call on the community to ensure the reliability of LLM benchmarking by: (i) advancing novel contamination-resistant methodologies, (ii) developing supporting methods and platforms, and (iii) adopting contamination-resistant benchmarks into existing evaluation pipelines.
Moltbook Moderation: Uncovering Hidden Intent Through Multi-Turn Dialogue
May 14, 2026The emergence of multi-agent systems introduces novel moderation challenges that extend beyond content filtering. Agents with malicious intent may contribute harmful content that appears benign to evade content-based moderation, while compromising the system through exploitative and malicious behavior manifested across their overall interaction patterns within the community. To address this, we introduce BOT-MOD (BOT-MODeration), a moderation framework that grounds detection in agent intent rather than traditional content level signals. BOT-MOD identifies the underlying intent by engaging with the target agent in a multi-turn exchange guided by Gibbs-based sampling over candidate intent hypotheses. This progressively narrows the space of plausible agent objectives to identify the underlying behavior. To evaluate our approach, we construct a dataset derived from Moltbook that encompasses diverse benign and malicious behaviors based on actual community structures, posts, and comments. Results demonstrate that BOT-MOD reliably identifies agent intent across a range of adversarial configurations, while maintaining a low false positive rate on benign behaviors. This work advances the foundation for scalable, intent-aware moderation of agents in open multi-agent environments.
DIA-HARM: Dialectal Disparities in Harmful Content Detection Across 50 English Dialects
Apr 07, 2026Harmful content detectors-particularly disinformation classifiers-are predominantly developed and evaluated on Standard American English (SAE), leaving their robustness to dialectal variation unexplored. We present DIA-HARM, the first benchmark for evaluating disinformation detection robustness across 50 English dialects spanning U.S., British, African, Caribbean, and Asia-Pacific varieties. Using Multi-VALUE's linguistically grounded transformations, we introduce D3 (Dialectal Disinformation Detection), a corpus of 195K samples derived from established disinformation benchmarks. Our evaluation of 16 detection models reveals systematic vulnerabilities: human-written dialectal content degrades detection by 1.4-3.6% F1, while AI-generated content remains stable. Fine-tuned transformers substantially outperform zero-shot LLMs (96.6% vs. 78.3% best-case F1), with some models exhibiting catastrophic failures exceeding 33% degradation on mixed content. Cross-dialectal transfer analysis across 2,450 dialect pairs shows that multilingual models (mDeBERTa: 97.2% average F1) generalize effectively, while monolingual models like RoBERTa and XLM-RoBERTa fail on dialectal inputs. These findings demonstrate that current disinformation detectors may systematically disadvantage hundreds of millions of non-SAE speakers worldwide. We release the DIA-HARM framework, D3 corpus, and evaluation tools: https://github.com/jsl5710/dia-harm
BLUFF: Benchmarking the Detection of False and Synthetic Content across 58 Low-Resource Languages
Feb 28, 2026Multilingual falsehoods threaten information integrity worldwide, yet detection benchmarks remain confined to English or a few high-resource languages, leaving low-resource linguistic communities without robust defense tools. We introduce BLUFF, a comprehensive benchmark for detecting false and synthetic content, spanning 79 languages with over 202K samples, combining human-written fact-checked content (122K+ samples across 57 languages) and LLM-generated content (79K+ samples across 71 languages). BLUFF uniquely covers both high-resource "big-head" (20) and low-resource "long-tail" (59) languages, addressing critical gaps in multilingual research on detecting false and synthetic content. Our dataset features four content types (human-written, LLM-generated, LLM-translated, and hybrid human-LLM text), bidirectional translation (English$\leftrightarrow$X), 39 textual modification techniques (36 manipulation tactics for fake news, 3 AI-editing strategies for real news), and varying edit intensities generated using 19 diverse LLMs. We present AXL-CoI (Adversarial Cross-Lingual Agentic Chainof-Interactions), a novel multi-agentic framework for controlled fake/real news generation, paired with mPURIFY, a quality filtering pipeline ensuring dataset integrity. Experiments reveal state-of-theart detectors suffer up to 25.3% F1 degradation on low-resource versus high-resource languages. BLUFF provides the research community with a multilingual benchmark, extensive linguistic-oriented benchmark evaluation, comprehensive documentation, and opensource tools to advance equitable falsehood detection. Dataset and code are available at: https://jsl5710.github.io/BLUFF/
Graph-based Molecular In-context Learning Grounded on Morgan Fingerprints
Feb 08, 2025



In-context learning (ICL) effectively conditions large language models (LLMs) for molecular tasks, such as property prediction and molecule captioning, by embedding carefully selected demonstration examples into the input prompt. This approach avoids the computational overhead of extensive pertaining and fine-tuning. However, current prompt retrieval methods for molecular tasks have relied on molecule feature similarity, such as Morgan fingerprints, which do not adequately capture the global molecular and atom-binding relationships. As a result, these methods fail to represent the full complexity of molecular structures during inference. Moreover, small-to-medium-sized LLMs, which offer simpler deployment requirements in specialized systems, have remained largely unexplored in the molecular ICL literature. To address these gaps, we propose a self-supervised learning technique, GAMIC (Graph-Aligned Molecular In-Context learning, which aligns global molecular structures, represented by graph neural networks (GNNs), with textual captions (descriptions) while leveraging local feature similarity through Morgan fingerprints. In addition, we introduce a Maximum Marginal Relevance (MMR) based diversity heuristic during retrieval to optimize input prompt demonstration samples. Our experimental findings using diverse benchmark datasets show GAMIC outperforms simple Morgan-based ICL retrieval methods across all tasks by up to 45%.
Semantic Captioning: Benchmark Dataset and Graph-Aware Few-Shot In-Context Learning for SQL2Text
Jan 06, 2025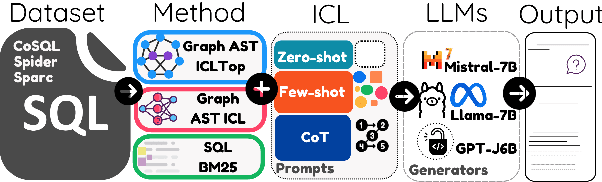
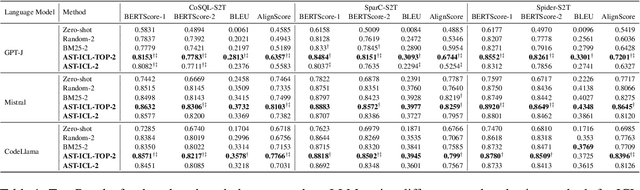

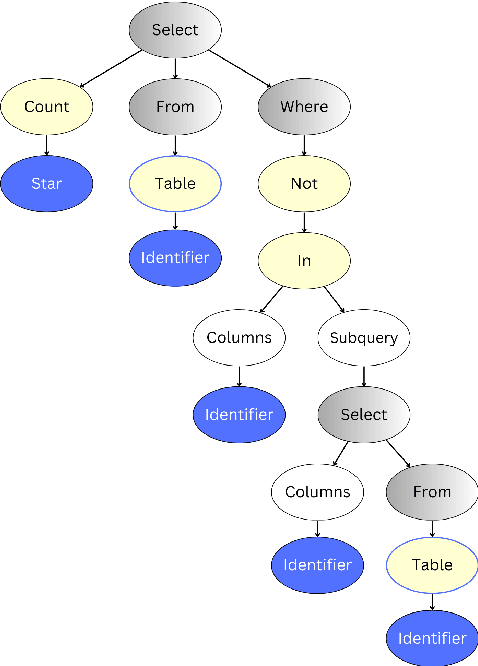
Large Language Models (LLMs) have demonstrated remarkable performance in various NLP tasks, including semantic parsing, which trans lates natural language into formal code representations. However, the reverse process, translating code into natural language, termed semantic captioning, has received less attention. This task is becoming increasingly important as LLMs are integrated into platforms for code generation, security analysis, and educational purposes. In this paper, we focus on the captioning of SQL query (SQL2Text) to address the critical need for understanding and explaining SQL queries in an era where LLM-generated code poses potential security risks. We repurpose Text2SQL datasets for SQL2Text by introducing an iterative ICL prompt using GPT-4o to generate multiple additional utterances, which enhances the robustness of the datasets for the reverse task. We conduct our experiments using in-context learning (ICL) based on different sample selection methods, emphasizing smaller, more computationally efficient LLMs. Our findings demonstrate that leveraging the inherent graph properties of SQL for ICL sample selection significantly outperforms random selection by up to 39% on BLEU score and provides better results than alternative methods. Dataset and codes are published: \url{https://github.com/aliwister/ast-icl}.
Beemo: Benchmark of Expert-edited Machine-generated Outputs
Nov 06, 2024The rapid proliferation of large language models (LLMs) has increased the volume of machine-generated texts (MGTs) and blurred text authorship in various domains. However, most existing MGT benchmarks include single-author texts (human-written and machine-generated). This conventional design fails to capture more practical multi-author scenarios, where the user refines the LLM response for natural flow, coherence, and factual correctness. Our paper introduces the Benchmark of Expert-edited Machine-generated Outputs (Beemo), which includes 6.5k texts written by humans, generated by ten instruction-finetuned LLMs, and edited by experts for various use cases, ranging from creative writing to summarization. Beemo additionally comprises 13.1k machine-generated and LLM-edited texts, allowing for diverse MGT detection evaluation across various edit types. We document Beemo's creation protocol and present the results of benchmarking 33 configurations of MGT detectors in different experimental setups. We find that expert-based editing evades MGT detection, while LLM-edited texts are unlikely to be recognized as human-written. Beemo and all materials are publicly available.
Fighting Fire with Fire: The Dual Role of LLMs in Crafting and Detecting Elusive Disinformation
Oct 24, 2023Recent ubiquity and disruptive impacts of large language models (LLMs) have raised concerns about their potential to be misused (.i.e, generating large-scale harmful and misleading content). To combat this emerging risk of LLMs, we propose a novel "Fighting Fire with Fire" (F3) strategy that harnesses modern LLMs' generative and emergent reasoning capabilities to counter human-written and LLM-generated disinformation. First, we leverage GPT-3.5-turbo to synthesize authentic and deceptive LLM-generated content through paraphrase-based and perturbation-based prefix-style prompts, respectively. Second, we apply zero-shot in-context semantic reasoning techniques with cloze-style prompts to discern genuine from deceptive posts and news articles. In our extensive experiments, we observe GPT-3.5-turbo's zero-shot superiority for both in-distribution and out-of-distribution datasets, where GPT-3.5-turbo consistently achieved accuracy at 68-72%, unlike the decline observed in previous customized and fine-tuned disinformation detectors. Our codebase and dataset are available at https://github.com/mickeymst/F3.