 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANE: Lexical Adversarial Negative Examples for Word Sense Disambiguation
Nov 14, 2025Fine-grained word meaning resolution remains a critical challenge for neural language models (NLMs) as they often overfit to global sentence representations, failing to capture local semantic details. We propose a novel adversarial training strategy, called LANE, to address this limitation by deliberately shifting the model's learning focus to the target word. This method generates challenging negative training examples through the selective marking of alternate words in the training set. The goal is to force the model to create a greater separability between same sentences with different marked words. Experimental results on lexical semantic change detection and word sense disambiguation benchmarks demonstrate that our approach yields more discriminative word representations, improving performance over standard contrastive learning baselines. We further provide qualitative analyses showing that the proposed negatives lead to representations that better capture subtle meaning differences even in challenging environments. Our method is model-agnostic and can be integrated into existing representation learning frameworks.
Adverbs Revisited: Enhancing WordNet Coverage of Adverbs with a Supersense Taxonomy
Nov 14, 2025WordNet offers rich supersense hierarchies for nouns and verbs, yet adverbs remain underdeveloped, lacking a systematic semantic classification. We introduce a linguistically grounded supersense typology for adverbs, empirically validated through annotation, that captures major semantic domains including manner, temporal, frequency, degree, domain, speaker-oriented, and subject-oriented functions. Results from a pilot annotation study demonstrate that these categories provide broad coverage of adverbs in natural text and can be reliably assigned by human annotators. Incorporating this typology extends WordNet's coverage, aligns it more closely with linguistic theory, and facilitates downstream NLP applications such as word sense disambiguation, event extraction, sentiment analysis, and discourse modeling. We present the proposed supersense categories, annotation outcomes, and directions for future work.
Collaborative Evaluation of Deepfake Text with Deliberation-Enhancing Dialogue Systems
Mar 06, 2025The proliferation of generative models has presented significant challenges in distinguishing authentic human-authored content from deepfake content. Collaborative human efforts, augmented by AI tools, present a promising solution. In this study, we explore the potential of DeepFakeDeLiBot, a deliberation-enhancing chatbot, to support groups in detecting deepfake text. Our findings reveal that group-based problem-solving significantly improves the accuracy of identifying machine-generated paragraphs compared to individual efforts. While engagement with DeepFakeDeLiBot does not yield substantial performance gains overall, it enhances group dynamics by fostering greater participant engagement, consensus building, and the frequency and diversity of reasoning-based utterances. Additionally, participants with higher perceived effectiveness of group collaboration exhibited performance benefits from DeepFakeDeLiBot. These findings underscore the potential of deliberative chatbots in fostering interactive and productive group dynamics while ensuring accuracy in collaborative deepfake text detection. \textit{Dataset and source code used in this study will be made publicly available upon acceptance of the manuscript.
Beemo: Benchmark of Expert-edited Machine-generated Outputs
Nov 06, 2024The rapid proliferation of large language models (LLMs) has increased the volume of machine-generated texts (MGTs) and blurred text authorship in various domains. However, most existing MGT benchmarks include single-author texts (human-written and machine-generated). This conventional design fails to capture more practical multi-author scenarios, where the user refines the LLM response for natural flow, coherence, and factual correctness. Our paper introduces the Benchmark of Expert-edited Machine-generated Outputs (Beemo), which includes 6.5k texts written by humans, generated by ten instruction-finetuned LLMs, and edited by experts for various use cases, ranging from creative writing to summarization. Beemo additionally comprises 13.1k machine-generated and LLM-edited texts, allowing for diverse MGT detection evaluation across various edit types. We document Beemo's creation protocol and present the results of benchmarking 33 configurations of MGT detectors in different experimental setups. We find that expert-based editing evades MGT detection, while LLM-edited texts are unlikely to be recognized as human-written. Beemo and all materials are publicly available.
DeepHQ: Learned Hierarchical Quantizer for Progressive Deep Image Coding
Aug 22, 2024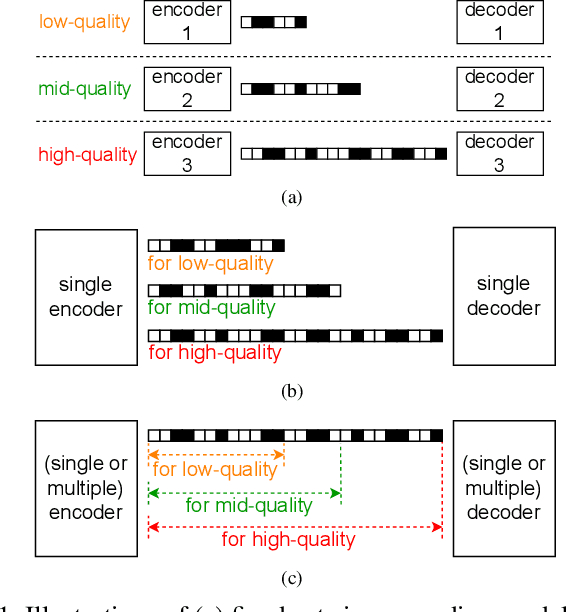



Unlike fixed- or variable-rate image coding, progressive image coding (PIC) aims to compress various qualities of images into a single bitstream, increasing the versatility of bitstream utilization and providing high compression efficiency compared to simulcast compression. Research on neural network (NN)-based PIC is in its early stages, mainly focusing on applying varying quantization step sizes to the transformed latent representations in a hierarchical manner. These approaches are designed to compress only the progressively added information as the quality improves, considering that a wider quantization interval for lower-quality compression includes multiple narrower sub-intervals for higher-quality compression. However, the existing methods are based on handcrafted quantization hierarchies, resulting in sub-optimal compression efficiency. In this paper, we propose an NN-based progressive coding method that firstly utilizes learned quantization step sizes via learning for each quantization layer. We also incorporate selective compression with which only the essential representation components are compressed for each quantization layer. We demonstrate that our method achieves significantly higher coding efficiency than the existing approaches with decreased decoding time and reduced model size.
PlagBench: Exploring the Duality of Large Language Models in Plagiarism Generation and Detection
Jun 24, 2024
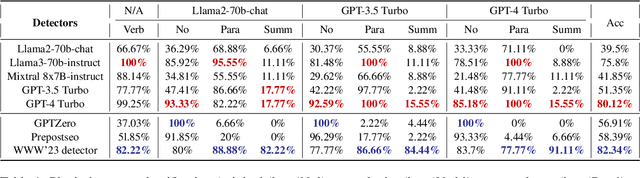
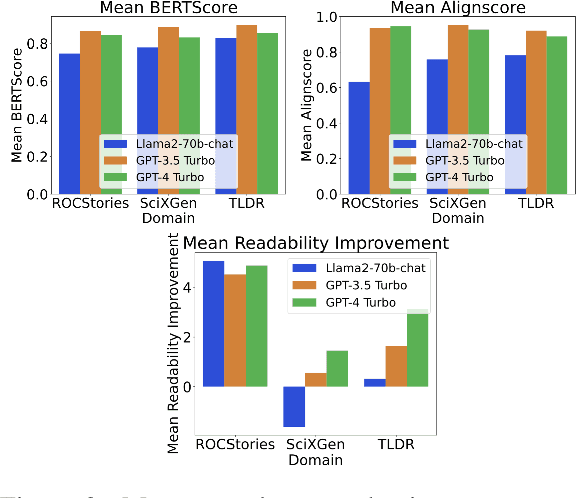

Recent literature has highlighted potential risks to academic integrity associated with large language models (LLMs), as they can memorize parts of training instances and reproduce them in the generated texts without proper attribution. In addition, given their capabilities in generating high-quality texts, plagiarists can exploit LLMs to generate realistic paraphrases or summaries indistinguishable from original work. In response to possible malicious use of LLMs in plagiarism, we introduce PlagBench, a comprehensive dataset consisting of 46.5K synthetic plagiarism cases generated using three instruction-tuned LLMs across three writing domains. The quality of PlagBench is ensured through fine-grained automatic evaluation for each type of plagiarism, complemented by human annotation. We then leverage our proposed dataset to evaluate the plagiarism detection performance of five modern LLMs and three specialized plagiarism checkers. Our findings reveal that GPT-3.5 tends to generates paraphrases and summaries of higher quality compared to Llama2 and GPT-4. Despite LLMs' weak performance in summary plagiarism identification, they can surpass current commercial plagiarism detectors. Overall, our results highlight the potential of LLMs to serve as robust plagiarism detection tools.
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Apr 04, 2024



We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
Fighting Fire with Fire: The Dual Role of LLMs in Crafting and Detecting Elusive Disinformation
Oct 24, 2023Recent ubiquity and disruptive impacts of large language models (LLMs) have raised concerns about their potential to be misused (.i.e, generating large-scale harmful and misleading content). To combat this emerging risk of LLMs, we propose a novel "Fighting Fire with Fire" (F3) strategy that harnesses modern LLMs' generative and emergent reasoning capabilities to counter human-written and LLM-generated disinformation. First, we leverage GPT-3.5-turbo to synthesize authentic and deceptive LLM-generated content through paraphrase-based and perturbation-based prefix-style prompts, respectively. Second, we apply zero-shot in-context semantic reasoning techniques with cloze-style prompts to discern genuine from deceptive posts and news articles. In our extensive experiments, we observe GPT-3.5-turbo's zero-shot superiority for both in-distribution and out-of-distribution datasets, where GPT-3.5-turbo consistently achieved accuracy at 68-72%, unlike the decline observed in previous customized and fine-tuned disinformation detectors. Our codebase and dataset are available at https://github.com/mickeymst/F3.
COMPASS: High-Efficiency Deep Image Compression with Arbitrary-scale Spatial Scalability
Sep 11, 2023Recently, neural network (NN)-based image compression studies have actively been made and has shown impressive performance in comparison to traditional methods. However, most of the works have focused on non-scalable image compression (single-layer coding) while spatially scalable image compression has drawn less attention although it has many applications. In this paper, we propose a novel NN-based spatially scalable image compression method, called COMPASS, which supports arbitrary-scale spatial scalability. Our proposed COMPASS has a very flexible structure where the number of layers and their respective scale factors can be arbitrarily determined during inference. To reduce the spatial redundancy between adjacent layers for arbitrary scale factors, our COMPASS adopts an inter-layer arbitrary scale prediction method, called LIFF, based on implicit neural representation. We propose a combined RD loss function to effectively train multiple layers. Experimental results show that our COMPASS achieves BD-rate gain of -58.33% and -47.17% at maximum compared to SHVC and the state-of-the-art NN-based spatially scalable image compression method, respectively, for various combinations of scale factors. Our COMPASS also shows comparable or even better coding efficiency than the single-layer coding for various scale factors.
End-to-End Learnable Multi-Scale Feature Compression for VCM
Jul 16, 2023The proliferation of deep learning-based machine vision applications has given rise to a new type of compression, so called video coding for machine (VCM). VCM differs from traditional video coding in that it is optimized for machine vision performance instead of human visual quality. In the feature compression track of MPEG-VCM, multi-scale features extracted from images are subject to compression. Recent feature compression works have demonstrated that the versatile video coding (VVC) standard-based approach can achieve a BD-rate reduction of up to 96% against MPEG-VCM feature anchor. However, it is still sub-optimal as VVC was not designed for extracted features but for natural images. Moreover, the high encoding complexity of VVC makes it difficult to design a lightweight encoder without sacrificing performance. To address these challenges, we propose a novel multi-scale feature compression method that enables both the end-to-end optimization on the extracted features and the design of lightweight encoders. The proposed model combines a learnable compressor with a multi-scale feature fusion network so that the redundancy in the multi-scale features is effectively removed. Instead of simply cascading the fusion network and the compression network, we integrate the fusion and encoding processes in an interleaved way. Our model first encodes a larger-scale feature to obtain a latent representation and then fuses the latent with a smaller-scale feature. This process is successively performed until the smallest-scale feature is fused and then the encoded latent at the final stage is entropy-coded for transmission. The results show that our model outperforms previous approaches by at least 52% BD-rate reduction and has $\times5$ to $\times27$ times less encoding time for object detection...