 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSpline: Structure-Informed Splines for Real-Time 3D Gaussians from Monocular Videos
Jun 01, 2026Dynamic scene reconstruction from monocular videos remains highly challenging, as existing methods often struggle to balance global structural coherence and local fine-grained details under limited multi-view cues. To address this challenge, we propose WebSpline, a novel dynamic 3D Gaussian framework that enables structurally coherent and high-fidelity reconstruction from monocular videos with fast rendering. The core of WebSpline is the Structure-Informed Spline (SIS) representation, which models each dynamic Gaussian trajectory using a learnable cubic Hermite spline whose motion is structurally organized with an auxiliary Structural Proxy Graph (SPG). The proposed framework is optimized in two stages: (i) in the first stage, the SPG is initialized from 2D point tracks and refined with temporal rigidity regularization to establish structural coherence for moving objects across the sequence; and (ii) in the second stage, the SIS representation is initialized from the refined SPG and optimized under both spatial and structural neighborhood constraints. At inference, Gaussian motion is obtained solely by evaluating the learned SIS, enabling fast rendering. Extensive experiments on the challenging monocular dynamic scene benchmarks, iPhone and NVIDIA, demonstrate that our WebSpline achieves state-of-the-art rendering quality while rendering over 10 times faster than WorldTree, the second-best method on the iPhone dataset.
MotionGrounder: Grounded Multi-Object Motion Transfer via Diffusion Transformer
Apr 01, 2026Motion transfer enables controllable video generation by transferring temporal dynamics from a reference video to synthesize a new video conditioned on a target caption. However, existing Diffusion Transformer (DiT)-based methods are limited to single-object videos, restricting fine-grained control in real-world scenes with multiple objects. In this work, we introduce MotionGrounder, a DiT-based framework that firstly handles motion transfer with multi-object controllability. Our Flow-based Motion Signal (FMS) in MotionGrounder provides a stable motion prior for target video generation, while our Object-Caption Alignment Loss (OCAL) grounds object captions to their corresponding spatial regions. We further propose a new Object Grounding Score (OGS), which jointly evaluates (i) spatial alignment between source video objects and their generated counterparts and (ii) semantic consistency between each generated object and its target caption. Our experiments show that MotionGrounder consistently outperforms recent baselines across quantitative, qualitative, and human evaluations.
AA-Splat: Anti-Aliased Feed-forward Gaussian Splatting
Mar 31, 2026Feed-forward 3D Gaussian Splatting (FF-3DGS) emerges as a fast and robust solution for sparse-view 3D reconstruction and novel view synthesis (NVS). However, existing FF-3DGS methods are built on incorrect screen-space dilation filters, causing severe rendering artifacts when rendering at out-of-distribution sampling rates. We firstly propose an FF-3DGS model, called AA-Splat, to enable robust anti-aliased rendering at any resolution. AA-Splat utilizes an opacity-balanced band-limiting (OBBL) design, which combines two components: a 3D band-limiting post-filter integrates multi-view maximal frequency bounds into the feed-forward reconstruction pipeline, effectively band-limiting the resulting 3D scene representations and eliminating degenerate Gaussians; an Opacity Balancing (OB) to seamlessly integrate all pixel-aligned Gaussian primitives into the rendering process, compensating for the increased overlap between expanded Gaussian primitives. AA-Splat demonstrates drastic improvements with average 5.4$\sim$7.5dB PSNR gains on NVS performance over a state-of-the-art (SOTA) baseline, DepthSplat, at all resolutions, between $4\times$ and $1/4\times$. Code will be made available.
AirSplat: Alignment and Rating for Robust Feed-Forward 3D Gaussian Splatting
Mar 26, 2026While 3D Vision Foundation Models (3DVFMs) have demonstrated remarkable zero-shot capabilities in visual geometry estimation, their direct application to generalizable novel view synthesis (NVS) remains challenging. In this paper, we propose AirSplat, a novel training framework that effectively adapts the robust geometric priors of 3DVFMs into high-fidelity, pose-free NVS. Our approach introduces two key technical contributions: (1) Self-Consistent Pose Alignment (SCPA), a training-time feedback loop that ensures pixel-aligned supervision to resolve pose-geometry discrepancy; and (2) Rating-based Opacity Matching (ROM), which leverages the local 3D geometry consistency knowledge from a sparse-view NVS teacher model to filter out degraded primitives. Experimental results on large-scale benchmarks demonstrate that our method significantly outperforms state-of-the-art pose-free NVS approaches in reconstruction quality. Our AirSplat highlights the potential of adapting 3DVFMs to enable simultaneous visual geometry estimation and high-quality view synthesis.
Less is More: Decoder-Free Masked Modeling for Efficient Skeleton Representation Learning
Mar 12, 2026The landscape of skeleton-based action representation learning has evolved from Contrastive Learning (CL) to Masked Auto-Encoder (MAE) architectures. However, each paradigm faces inherent limitations: CL often overlooks fine-grained local details, while MAE is burdened by computationally heavy decoders. Moreover, MAE suffers from severe computational asymmetry -- benefiting from efficient masking during pre-training but requiring exhaustive full-sequence processing for downstream tasks. To resolve these bottlenecks, we propose SLiM (Skeleton Less is More), a novel unified framework that harmonizes masked modeling with contrastive learning via a shared encoder. By eschewing the reconstruction decoder, SLiM not only eliminates computational redundancy but also compels the encoder to capture discriminative features directly. SLiM is the first framework with decoder-free masked modeling of representative learning. Crucially, to prevent trivial reconstruction arising from high skeletal-temporal correlation, we introduce semantic tube masking, alongside skeletal-aware augmentations designed to ensure anatomical consistency across diverse temporal granularities. Extensive experiments demonstrate that SLiM consistently achieves state-of-the-art performance across all downstream protocols. Notably, our method delivers this superior accuracy with exceptional efficiency, reducing inference computational cost by 7.89x compared to existing MAE methods.
PropFly: Learning to Propagate via On-the-Fly Supervision from Pre-trained Video Diffusion Models
Feb 24, 2026Propagation-based video editing enables precise user control by propagating a single edited frame into following frames while maintaining the original context such as motion and structures. However, training such models requires large-scale, paired (source and edited) video datasets, which are costly and complex to acquire. Hence, we propose the PropFly, a training pipeline for Propagation-based video editing, relying on on-the-Fly supervision from pre-trained video diffusion models (VDMs) instead of requiring off-the-shelf or precomputed paired video editing datasets. Specifically, our PropFly leverages one-step clean latent estimations from intermediate noised latents with varying Classifier-Free Guidance (CFG) scales to synthesize diverse pairs of 'source' (low-CFG) and 'edited' (high-CFG) latents on-the-fly. The source latent serves as structural information of the video, while the edited latent provides the target transformation for learning propagation. Our pipeline enables an additional adapter attached to the pre-trained VDM to learn to propagate edits via Guidance-Modulated Flow Matching (GMFM) loss, which guides the model to replicate the target transformation. Our on-the-fly supervision ensures the model to learn temporally consistent and dynamic transformations. Extensive experiments demonstrate that our PropFly significantly outperforms the state-of-the-art methods on various video editing tasks, producing high-quality editing results.
EcoSplat: Efficiency-controllable Feed-forward 3D Gaussian Splatting from Multi-view Images
Dec 21, 2025Feed-forward 3D Gaussian Splatting (3DGS) enables efficient one-pass scene reconstruction, providing 3D representations for novel view synthesis without per-scene optimization. However, existing methods typically predict pixel-aligned primitives per-view, producing an excessive number of primitives in dense-view settings and offering no explicit control over the number of predicted Gaussians. To address this, we propose EcoSplat, the first efficiency-controllable feed-forward 3DGS framework that adaptively predicts the 3D representation for any given target primitive count at inference time. EcoSplat adopts a two-stage optimization process. The first stage is Pixel-aligned Gaussian Training (PGT) where our model learns initial primitive prediction. The second stage is Importance-aware Gaussian Finetuning (IGF) stage where our model learns rank primitives and adaptively adjust their parameters based on the target primitive count. Extensive experiments across multiple dense-view settings show that EcoSplat is robust and outperforms state-of-the-art methods under strict primitive-count constraints, making it well-suited for flexible downstream rendering tasks.
ABBSPO: Adaptive Bounding Box Scaling and Symmetric Prior based Orientation Prediction for Detecting Aerial Image Objects
Dec 10, 2025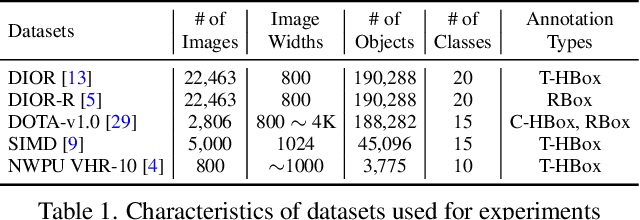
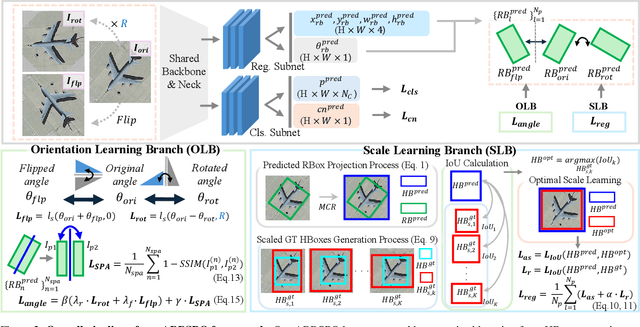
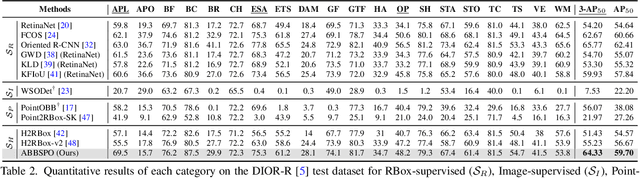
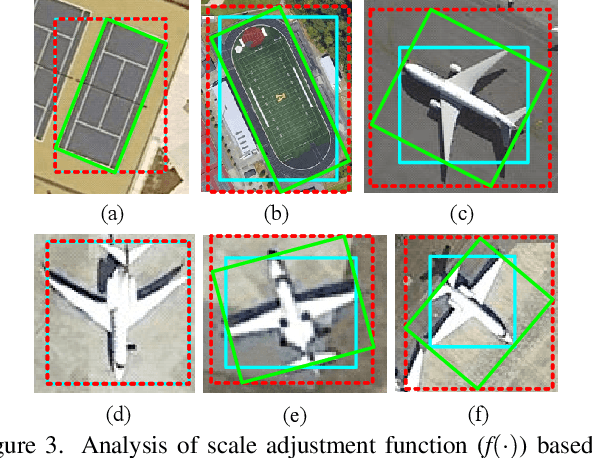
Weakly supervised oriented object detection (WS-OOD) has gained attention as a cost-effective alternative to fully supervised methods, providing both efficiency and high accuracy. Among weakly supervised approaches, horizontal bounding box (HBox)-supervised OOD stands out for its ability to directly leverage existing HBox annotations while achieving the highest accuracy under weak supervision settings. This paper introduces adaptive bounding box scaling and symmetry-prior-based orientation prediction, called ABBSPO, a framework for WS-OOD. Our ABBSPO addresses limitations of previous HBox-supervised OOD methods, which compare ground truth (GT) HBoxes directly with the minimum circumscribed rectangles of predicted RBoxes, often leading to inaccurate scale estimation. To overcome this, we propose: (i) Adaptive Bounding Box Scaling (ABBS), which appropriately scales GT HBoxes to optimize for the size of each predicted RBox, ensuring more accurate scale prediction; and (ii) a Symmetric Prior Angle (SPA) loss that exploits inherent symmetry of aerial objects for self-supervised learning, resolving issues in previous methods where learning collapses when predictions for all three augmented views (original, rotated, and flipped) are consistently incorrect. Extensive experimental results demonstrate that ABBSPO achieves state-of-the-art performance, outperforming existing methods.
PAN-Crafter: Learning Modality-Consistent Alignment for PAN-Sharpening
May 29, 2025



PAN-sharpening aims to fuse high-resolution panchromatic (PAN) images with low-resolution multi-spectral (MS) images to generate high-resolution multi-spectral (HRMS) outputs. However, cross-modality misalignment -- caused by sensor placement, acquisition timing, and resolution disparity -- induces a fundamental challenge. Conventional deep learning methods assume perfect pixel-wise alignment and rely on per-pixel reconstruction losses, leading to spectral distortion, double edges, and blurring when misalignment is present. To address this, we propose PAN-Crafter, a modality-consistent alignment framework that explicitly mitigates the misalignment gap between PAN and MS modalities. At its core, Modality-Adaptive Reconstruction (MARs) enables a single network to jointly reconstruct HRMS and PAN images, leveraging PAN's high-frequency details as auxiliary self-supervision. Additionally, we introduce Cross-Modality Alignment-Aware Attention (CM3A), a novel mechanism that bidirectionally aligns MS texture to PAN structure and vice versa, enabling adaptive feature refinement across modalities. Extensive experiments on multiple benchmark datasets demonstrate that our PAN-Crafter outperforms the most recent state-of-the-art method in all metrics, even with 50.11$\times$ faster inference time and 0.63$\times$ the memory size. Furthermore, it demonstrates strong generalization performance on unseen satellite datasets, showing its robustness across different conditions.
MoBGS: Motion Deblurring Dynamic 3D Gaussian Splatting for Blurry Monocular Video
Apr 21, 2025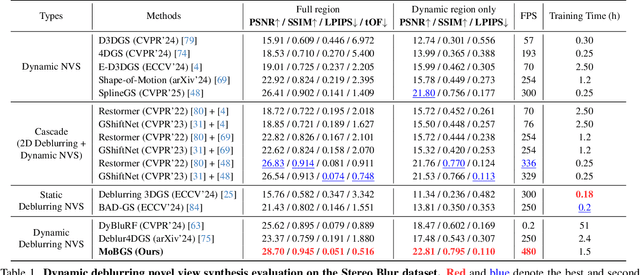

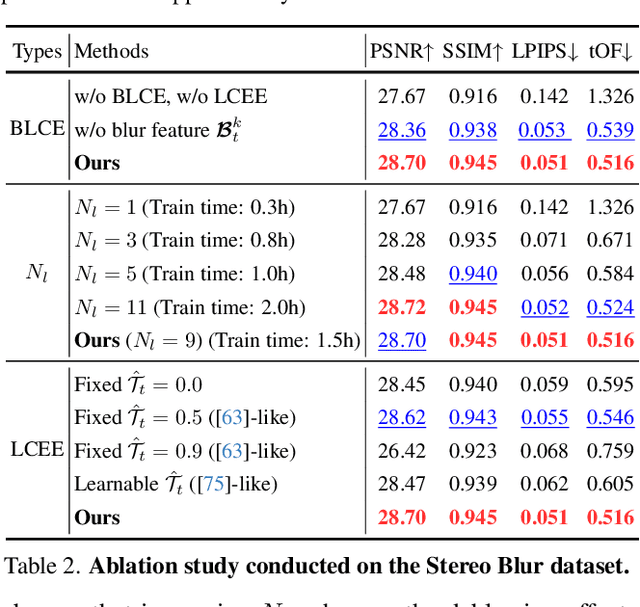

We present MoBGS, a novel deblurring dynamic 3D Gaussian Splatting (3DGS) framework capable of reconstructing sharp and high-quality novel spatio-temporal views from blurry monocular videos in an end-to-end manner. Existing dynamic novel view synthesis (NVS) methods are highly sensitive to motion blur in casually captured videos, resulting in significant degradation of rendering quality. While recent approaches address motion-blurred inputs for NVS, they primarily focus on static scene reconstruction and lack dedicated motion modeling for dynamic objects. To overcome these limitations, our MoBGS introduces a novel Blur-adaptive Latent Camera Estimation (BLCE) method for effective latent camera trajectory estimation, improving global camera motion deblurring. In addition, we propose a physically-inspired Latent Camera-induced Exposure Estimation (LCEE) method to ensure consistent deblurring of both global camera and local object motion. Our MoBGS framework ensures the temporal consistency of unseen latent timestamps and robust motion decomposition of static and dynamic regions. Extensive experiments on the Stereo Blur dataset and real-world blurry videos show that our MoBGS significantly outperforms the very recent advanced methods (DyBluRF and Deblur4DGS), achieving state-of-the-art performance for dynamic NVS under motion blur.