 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoSplat: Efficiency-controllable Feed-forward 3D Gaussian Splatting from Multi-view Images
Dec 21, 2025Feed-forward 3D Gaussian Splatting (3DGS) enables efficient one-pass scene reconstruction, providing 3D representations for novel view synthesis without per-scene optimization. However, existing methods typically predict pixel-aligned primitives per-view, producing an excessive number of primitives in dense-view settings and offering no explicit control over the number of predicted Gaussians. To address this, we propose EcoSplat, the first efficiency-controllable feed-forward 3DGS framework that adaptively predicts the 3D representation for any given target primitive count at inference time. EcoSplat adopts a two-stage optimization process. The first stage is Pixel-aligned Gaussian Training (PGT) where our model learns initial primitive prediction. The second stage is Importance-aware Gaussian Finetuning (IGF) stage where our model learns rank primitives and adaptively adjust their parameters based on the target primitive count. Extensive experiments across multiple dense-view settings show that EcoSplat is robust and outperforms state-of-the-art methods under strict primitive-count constraints, making it well-suited for flexible downstream rendering tasks.
MoBGS: Motion Deblurring Dynamic 3D Gaussian Splatting for Blurry Monocular Video
Apr 21, 2025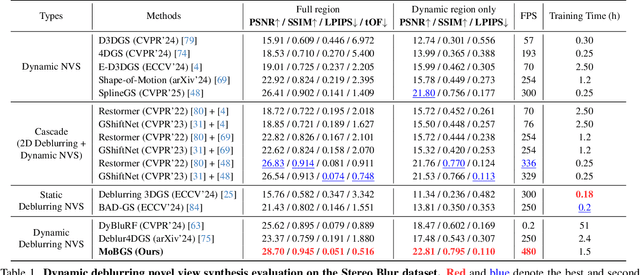

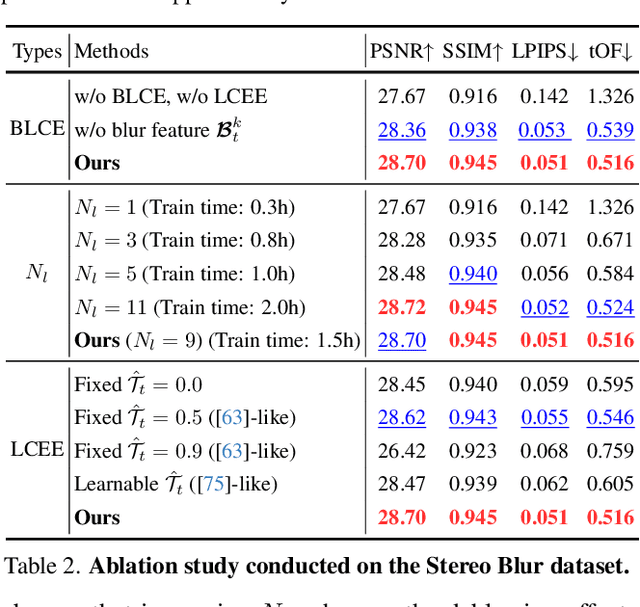

We present MoBGS, a novel deblurring dynamic 3D Gaussian Splatting (3DGS) framework capable of reconstructing sharp and high-quality novel spatio-temporal views from blurry monocular videos in an end-to-end manner. Existing dynamic novel view synthesis (NVS) methods are highly sensitive to motion blur in casually captured videos, resulting in significant degradation of rendering quality. While recent approaches address motion-blurred inputs for NVS, they primarily focus on static scene reconstruction and lack dedicated motion modeling for dynamic objects. To overcome these limitations, our MoBGS introduces a novel Blur-adaptive Latent Camera Estimation (BLCE) method for effective latent camera trajectory estimation, improving global camera motion deblurring. In addition, we propose a physically-inspired Latent Camera-induced Exposure Estimation (LCEE) method to ensure consistent deblurring of both global camera and local object motion. Our MoBGS framework ensures the temporal consistency of unseen latent timestamps and robust motion decomposition of static and dynamic regions. Extensive experiments on the Stereo Blur dataset and real-world blurry videos show that our MoBGS significantly outperforms the very recent advanced methods (DyBluRF and Deblur4DGS), achieving state-of-the-art performance for dynamic NVS under motion blur.
VideoSPatS: Video SPatiotemporal Splines for Disentangled Occlusion, Appearance and Motion Modeling and Editing
Apr 08, 2025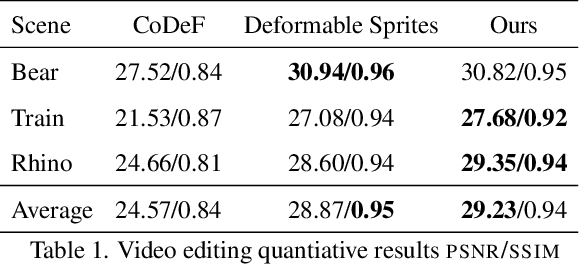
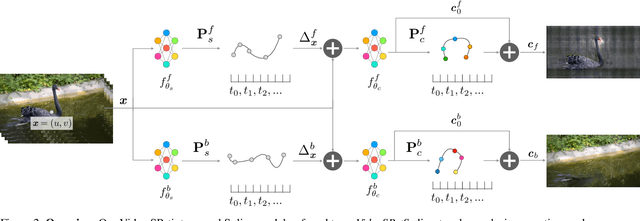
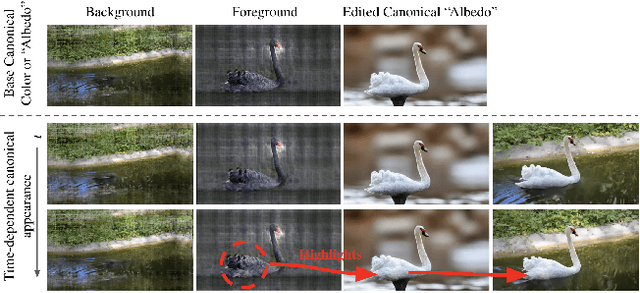

We present an implicit video representation for occlusions, appearance, and motion disentanglement from monocular videos, which we call Video SPatiotemporal Splines (VideoSPatS). Unlike previous methods that map time and coordinates to deformation and canonical colors, our VideoSPatS maps input coordinates into Spatial and Color Spline deformation fields $D_s$ and $D_c$, which disentangle motion and appearance in videos. With spline-based parametrization, our method naturally generates temporally consistent flow and guarantees long-term temporal consistency, which is crucial for convincing video editing. Using multiple prediction branches, our VideoSPatS model also performs layer separation between the latent video and the selected occluder. By disentangling occlusions, appearance, and motion, our method enables better spatiotemporal modeling and editing of diverse videos, including in-the-wild talking head videos with challenging occlusions, shadows, and specularities while maintaining an appropriate canonical space for editing. We also present general video modeling results on the DAVIS and CoDeF datasets, as well as our own talking head video dataset collected from open-source web videos. Extensive ablations show the combination of $D_s$ and $D_c$ under neural splines can overcome motion and appearance ambiguities, paving the way for more advanced video editing models.
SplineGS: Robust Motion-Adaptive Spline for Real-Time Dynamic 3D Gaussians from Monocular Video
Dec 13, 2024



Synthesizing novel views from in-the-wild monocular videos is challenging due to scene dynamics and the lack of multi-view cues. To address this, we propose SplineGS, a COLMAP-free dynamic 3D Gaussian Splatting (3DGS) framework for high-quality reconstruction and fast rendering from monocular videos. At its core is a novel Motion-Adaptive Spline (MAS) method, which represents continuous dynamic 3D Gaussian trajectories using cubic Hermite splines with a small number of control points. For MAS, we introduce a Motion-Adaptive Control points Pruning (MACP) method to model the deformation of each dynamic 3D Gaussian across varying motions, progressively pruning control points while maintaining dynamic modeling integrity. Additionally, we present a joint optimization strategy for camera parameter estimation and 3D Gaussian attributes, leveraging photometric and geometric consistency. This eliminates the need for Structure-from-Motion preprocessing and enhances SplineGS's robustness in real-world conditions. Experiments show that SplineGS significantly outperforms state-of-the-art methods in novel view synthesis quality for dynamic scenes from monocular videos, achieving thousands times faster rendering speed.
From-Ground-To-Objects: Coarse-to-Fine Self-supervised Monocular Depth Estimation of Dynamic Objects with Ground Contact Prior
Dec 15, 2023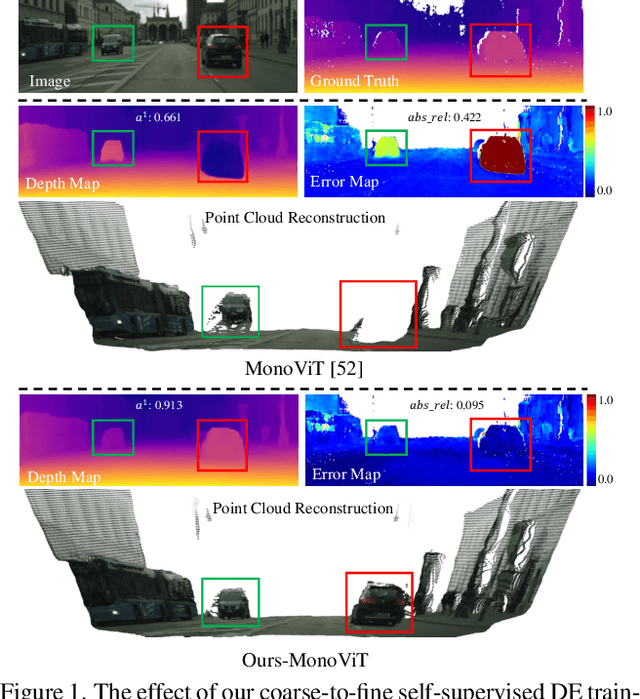
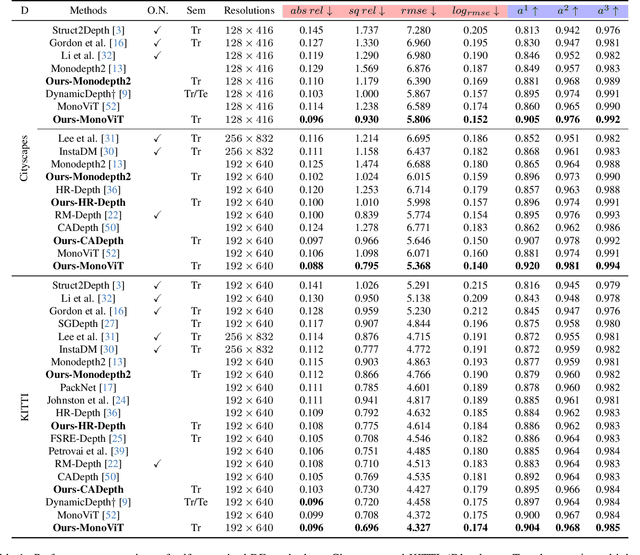
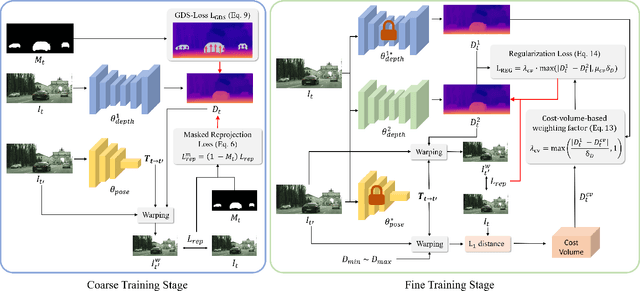
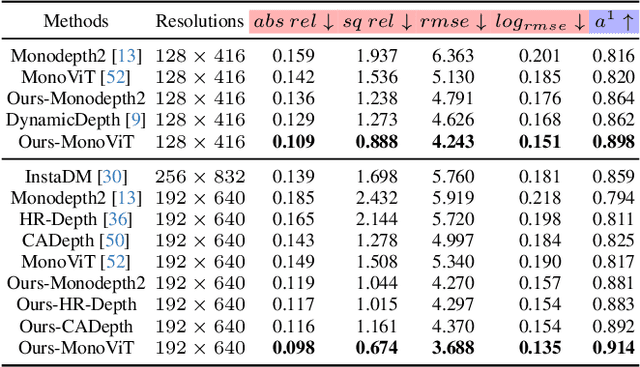
Self-supervised monocular depth estimation (DE) is an approach to learning depth without costly depth ground truths. However, it often struggles with moving objects that violate the static scene assumption during training. To address this issue, we introduce a coarse-to-fine training strategy leveraging the ground contacting prior based on the observation that most moving objects in outdoor scenes contact the ground. In the coarse training stage, we exclude the objects in dynamic classes from the reprojection loss calculation to avoid inaccurate depth learning. To provide precise supervision on the depth of the objects, we present a novel Ground-contacting-prior Disparity Smoothness Loss (GDS-Loss) that encourages a DE network to align the depth of the objects with their ground-contacting points. Subsequently, in the fine training stage, we refine the DE network to learn the detailed depth of the objects from the reprojection loss, while ensuring accurate DE on the moving object regions by employing our regularization loss with a cost-volume-based weighting factor. Our overall coarse-to-fine training strategy can easily be integrated with existing DE methods without any modifications, significantly enhancing DE performance on challenging Cityscapes and KITTI datasets, especially in the moving object regions.
ProNeRF: Learning Efficient Projection-Aware Ray Sampling for Fine-Grained Implicit Neural Radiance Fields
Dec 13, 2023Recent advances in neural rendering have shown that, albeit slow, implicit compact models can learn a scene's geometries and view-dependent appearances from multiple views. To maintain such a small memory footprint but achieve faster inference times, recent works have adopted `sampler' networks that adaptively sample a small subset of points along each ray in the implicit neural radiance fields. Although these methods achieve up to a 10$\times$ reduction in rendering time, they still suffer from considerable quality degradation compared to the vanilla NeRF. In contrast, we propose ProNeRF, which provides an optimal trade-off between memory footprint (similar to NeRF), speed (faster than HyperReel), and quality (better than K-Planes). ProNeRF is equipped with a novel projection-aware sampling (PAS) network together with a new training strategy for ray exploration and exploitation, allowing for efficient fine-grained particle sampling. Our ProNeRF yields state-of-the-art metrics, being 15-23x faster with 0.65dB higher PSNR than NeRF and yielding 0.95dB higher PSNR than the best published sampler-based method, HyperReel. Our exploration and exploitation training strategy allows ProNeRF to learn the full scenes' color and density distributions while also learning efficient ray sampling focused on the highest-density regions. We provide extensive experimental results that support the effectiveness of our method on the widely adopted forward-facing and 360 datasets, LLFF and Blender, respectively.
Novel View Synthesis with View-Dependent Effects from a Single Image
Dec 13, 2023In this paper, we firstly consider view-dependent effects into single image-based novel view synthesis (NVS) problems. For this, we propose to exploit the camera motion priors in NVS to model view-dependent appearance or effects (VDE) as the negative disparity in the scene. By recognizing specularities "follow" the camera motion, we infuse VDEs into the input images by aggregating input pixel colors along the negative depth region of the epipolar lines. Also, we propose a `relaxed volumetric rendering' approximation that allows computing the densities in a single pass, improving efficiency for NVS from single images. Our method can learn single-image NVS from image sequences only, which is a completely self-supervised learning method, for the first time requiring neither depth nor camera pose annotations. We present extensive experiment results and show that our proposed method can learn NVS with VDEs, outperforming the SOTA single-view NVS methods on the RealEstate10k and MannequinChallenge datasets.
Positional Information is All You Need: A Novel Pipeline for Self-Supervised SVDE from Videos
May 18, 2022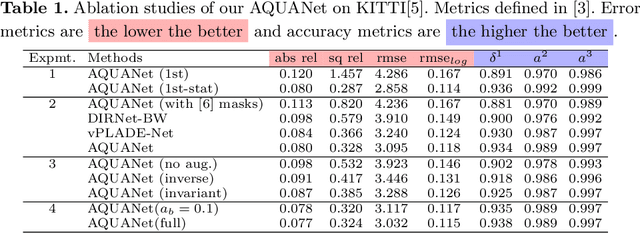
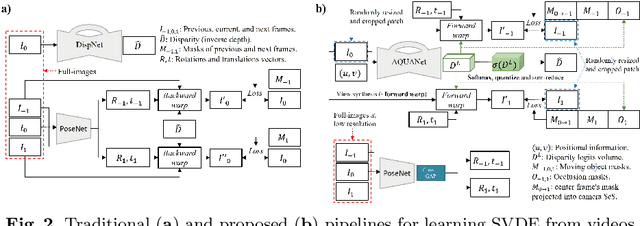
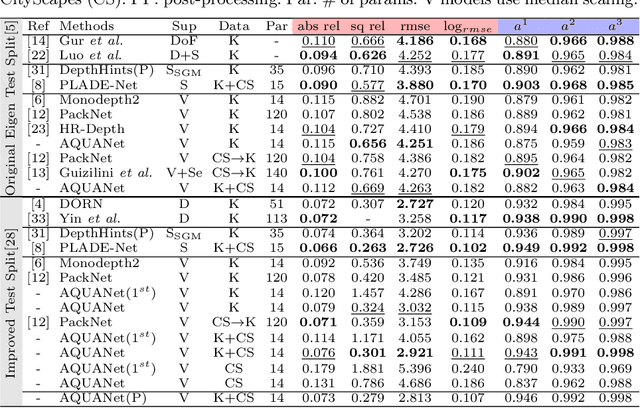
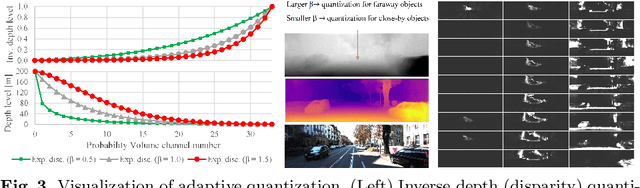
Recently, much attention has been drawn to learning the underlying 3D structures of a scene from monocular videos in a fully self-supervised fashion. One of the most challenging aspects of this task is handling the independently moving objects as they break the rigid-scene assumption. For the first time, we show that pixel positional information can be exploited to learn SVDE (Single View Depth Estimation) from videos. Our proposed moving object (MO) masks, which are induced by shifted positional information (SPI) and referred to as `SPIMO' masks, are very robust and consistently remove the independently moving objects in the scenes, allowing for better learning of SVDE from videos. Additionally, we introduce a new adaptive quantization scheme that assigns the best per-pixel quantization curve for our depth discretization. Finally, we employ existing boosting techniques in a new way to further self-supervise the depth of the moving objects. With these features, our pipeline is robust against moving objects and generalizes well to high-resolution images, even when trained with small patches, yielding state-of-the-art (SOTA) results with almost 8.5x fewer parameters than the previous works that learn from videos. We present extensive experiments on KITTI and CityScapes that show the effectiveness of our method.
PLADE-Net: Towards Pixel-Level Accuracy for Self-Supervised Single-View Depth Estimation with Neural Positional Encoding and Distilled Matting Loss
Mar 12, 2021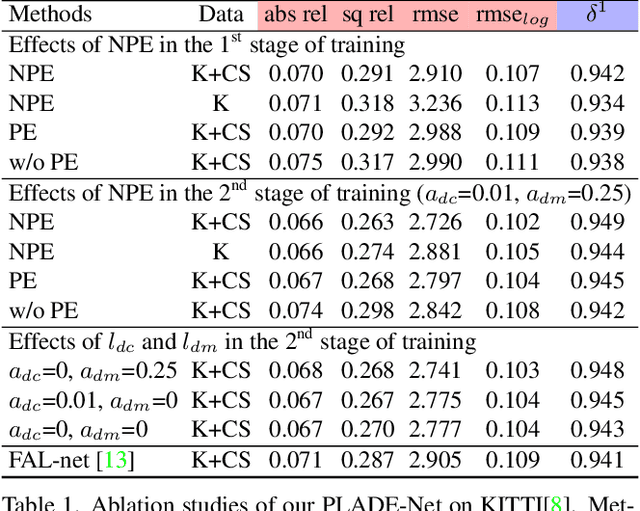

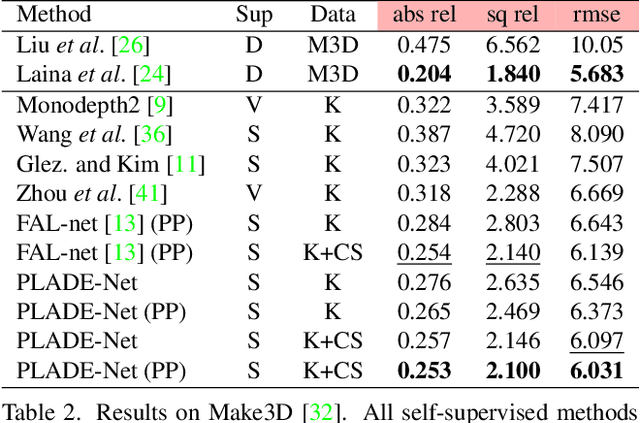

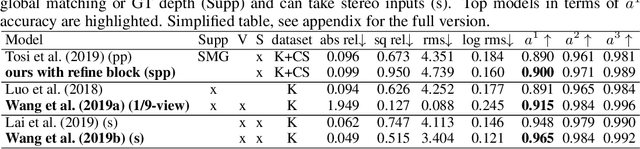
In this paper, we propose a self-supervised single-view pixel-level accurate depth estimation network, called PLADE-Net. The PLADE-Net is the first work that shows unprecedented accuracy levels, exceeding 95\% in terms of the $\delta^1$ metric on the challenging KITTI dataset. Our PLADE-Net is based on a new network architecture with neural positional encoding and a novel loss function that borrows from the closed-form solution of the matting Laplacian to learn pixel-level accurate depth estimation from stereo images. Neural positional encoding allows our PLADE-Net to obtain more consistent depth estimates by letting the network reason about location-specific image properties such as lens and projection distortions. Our novel distilled matting Laplacian loss allows our network to predict sharp depths at object boundaries and more consistent depths in highly homogeneous regions. Our proposed method outperforms all previous self-supervised single-view depth estimation methods by a large margin on the challenging KITTI dataset, with unprecedented levels of accuracy. Furthermore, our PLADE-Net, naively extended for stereo inputs, outperforms the most recent self-supervised stereo methods, even without any advanced blocks like 1D correlations, 3D convolutions, or spatial pyramid pooling. We present extensive ablation studies and experiments that support our method's effectiveness on the KITTI, CityScapes, and Make3D datasets.
Deep 3D Pan via adaptive "t-shaped" convolutions with global and local adaptive dilations
Oct 21, 2019
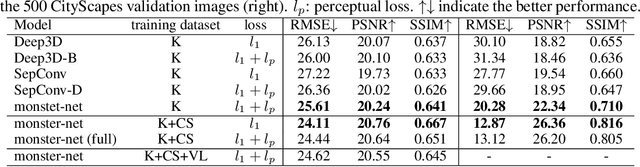
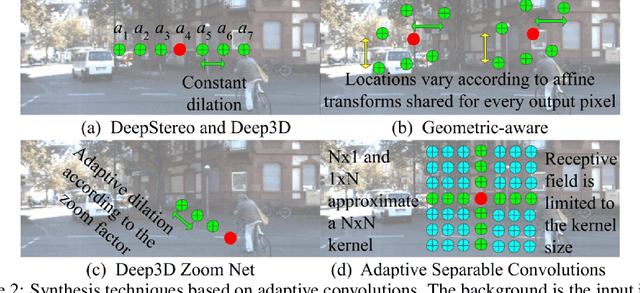
Recent advances in deep learning have shown promising results in many low-level vision tasks. However, solving the single-image-based view synthesis is still an open problem. In particular, the generation of new images at parallel camera views given a single input image is of great interest, as it enables 3D visualization of the 2D input scenery. We propose a novel network architecture to perform stereoscopic view synthesis at arbitrary camera positions along the X-axis, or Deep 3D Pan, with "t-shaped" adaptive kernels equipped with globally and locally adaptive dilations. Our proposed network architecture, the monster-net, is devised with a novel "t-shaped" adaptive kernel with globally and locally adaptive dilation, which can efficiently incorporate global camera shift into and handle local 3D geometries of the target image's pixels for the synthesis of naturally looking 3D panned views when a 2-D input image is given. Extensive experiments were performed on the KITTI, CityScapes and our VICLAB_STEREO indoors dataset to prove the efficacy of our method. Our monster-net significantly outperforms the state-of-the-art method, SOTA, by a large margin in all metrics of RMSE, PSNR, and SSIM. Our proposed monster-net is capable of reconstructing more reliable image structures in synthesized images with coherent geometry. Moreover, the disparity information that can be extracted from the "t-shaped" kernel is much more reliable than that of the SOTA for the unsupervised monocular depth estimation task, confirming the effectiveness of our method.