 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoSPatS: Video SPatiotemporal Splines for Disentangled Occlusion, Appearance and Motion Modeling and Editing
Apr 08, 2025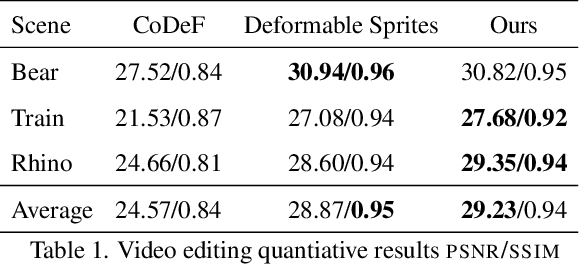
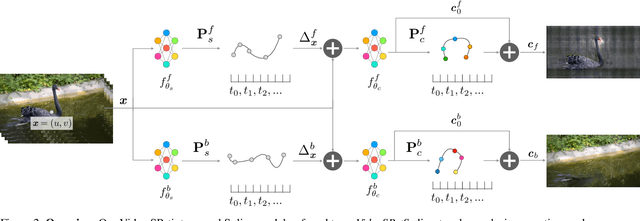
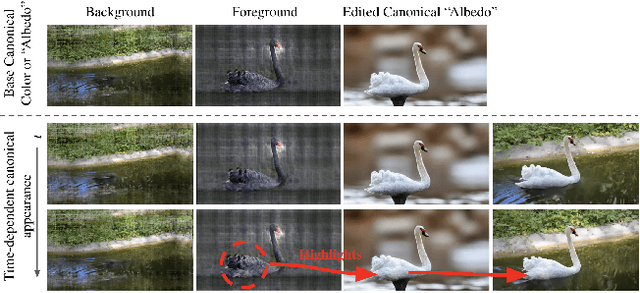

We present an implicit video representation for occlusions, appearance, and motion disentanglement from monocular videos, which we call Video SPatiotemporal Splines (VideoSPatS). Unlike previous methods that map time and coordinates to deformation and canonical colors, our VideoSPatS maps input coordinates into Spatial and Color Spline deformation fields $D_s$ and $D_c$, which disentangle motion and appearance in videos. With spline-based parametrization, our method naturally generates temporally consistent flow and guarantees long-term temporal consistency, which is crucial for convincing video editing. Using multiple prediction branches, our VideoSPatS model also performs layer separation between the latent video and the selected occluder. By disentangling occlusions, appearance, and motion, our method enables better spatiotemporal modeling and editing of diverse videos, including in-the-wild talking head videos with challenging occlusions, shadows, and specularities while maintaining an appropriate canonical space for editing. We also present general video modeling results on the DAVIS and CoDeF datasets, as well as our own talking head video dataset collected from open-source web videos. Extensive ablations show the combination of $D_s$ and $D_c$ under neural splines can overcome motion and appearance ambiguities, paving the way for more advanced video editing models.
Contextual Gesture: Co-Speech Gesture Video Generation through Context-aware Gesture Representation
Feb 11, 2025Co-speech gesture generation is crucial for creating lifelike avatars and enhancing human-computer interactions by synchronizing gestures with speech. Despite recent advancements, existing methods struggle with accurately identifying the rhythmic or semantic triggers from audio for generating contextualized gesture patterns and achieving pixel-level realism. To address these challenges, we introduce Contextual Gesture, a framework that improves co-speech gesture video generation through three innovative components: (1) a chronological speech-gesture alignment that temporally connects two modalities, (2) a contextualized gesture tokenization that incorporate speech context into motion pattern representation through distillation, and (3) a structure-aware refinement module that employs edge connection to link gesture keypoints to improve video generation. Our extensive experiments demonstrate that Contextual Gesture not only produces realistic and speech-aligned gesture videos but also supports long-sequence generation and video gesture editing applications, shown in Fig.1 Project Page: https://andypinxinliu.github.io/Contextual-Gesture/.
AutoDecoding Latent 3D Diffusion Models
Jul 07, 2023We present a novel approach to the generation of static and articulated 3D assets that has a 3D autodecoder at its core. The 3D autodecoder framework embeds properties learned from the target dataset in the latent space, which can then be decoded into a volumetric representation for rendering view-consistent appearance and geometry. We then identify the appropriate intermediate volumetric latent space, and introduce robust normalization and de-normalization operations to learn a 3D diffusion from 2D images or monocular videos of rigid or articulated objects. Our approach is flexible enough to use either existing camera supervision or no camera information at all -- instead efficiently learning it during training. Our evaluations demonstrate that our generation results outperform state-of-the-art alternatives on various benchmark datasets and metrics, including multi-view image datasets of synthetic objects, real in-the-wild videos of moving people, and a large-scale, real video dataset of static objects.
Unsupervised Volumetric Animation
Jan 26, 2023



We propose a novel approach for unsupervised 3D animation of non-rigid deformable objects. Our method learns the 3D structure and dynamics of objects solely from single-view RGB videos, and can decompose them into semantically meaningful parts that can be tracked and animated. Using a 3D autodecoder framework, paired with a keypoint estimator via a differentiable PnP algorithm, our model learns the underlying object geometry and parts decomposition in an entirely unsupervised manner. This allows it to perform 3D segmentation, 3D keypoint estimation, novel view synthesis, and animation. We primarily evaluate the framework on two video datasets: VoxCeleb $256^2$ and TEDXPeople $256^2$. In addition, on the Cats $256^2$ image dataset, we show it even learns compelling 3D geometry from still images. Finally, we show our model can obtain animatable 3D objects from a single or few images. Code and visual results available on our project website, see https://snap-research.github.io/unsupervised-volumetric-animation .
ScanEnts3D: Exploiting Phrase-to-3D-Object Correspondences for Improved Visio-Linguistic Models in 3D Scenes
Dec 12, 2022

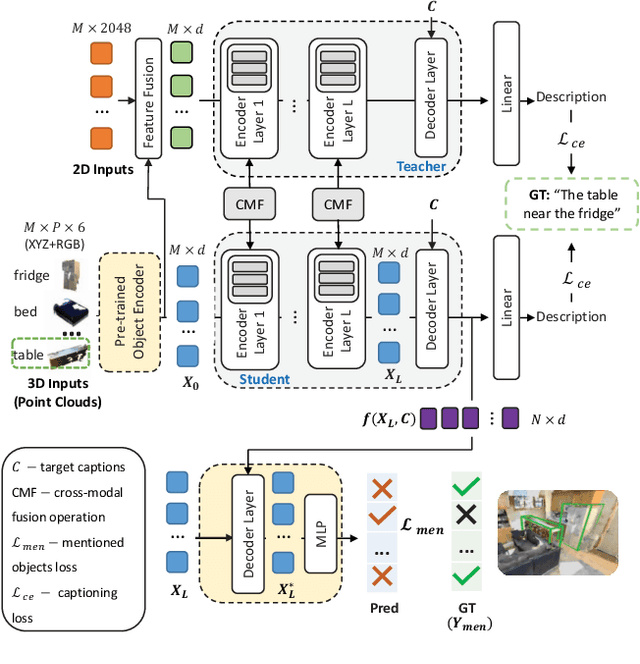
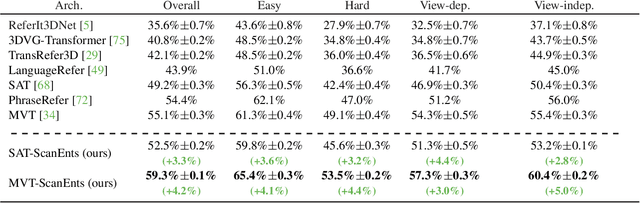
The two popular datasets ScanRefer [16] and ReferIt3D [3] connect natural language to real-world 3D data. In this paper, we curate a large-scale and complementary dataset extending both the aforementioned ones by associating all objects mentioned in a referential sentence to their underlying instances inside a 3D scene. Specifically, our Scan Entities in 3D (ScanEnts3D) dataset provides explicit correspondences between 369k objects across 84k natural referential sentences, covering 705 real-world scenes. Crucially, we show that by incorporating intuitive losses that enable learning from this novel dataset, we can significantly improve the performance of several recently introduced neural listening architectures, including improving the SoTA in both the Nr3D and ScanRefer benchmarks by 4.3% and 5.0%, respectively. Moreover, we experiment with competitive baselines and recent methods for the task of language generation and show that, as with neural listeners, 3D neural speakers can also noticeably benefit by training with ScanEnts3D, including improving the SoTA by 13.2 CIDEr points on the Nr3D benchmark. Overall, our carefully conducted experimental studies strongly support the conclusion that, by learning on ScanEnts3D, commonly used visio-linguistic 3D architectures can become more efficient and interpretable in their generalization without needing to provide these newly collected annotations at test time. The project's webpage is https://scanents3d.github.io/ .
Cross-Modal 3D Shape Generation and Manipulation
Jul 24, 2022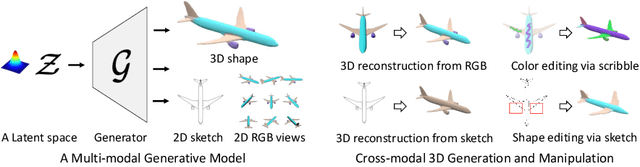

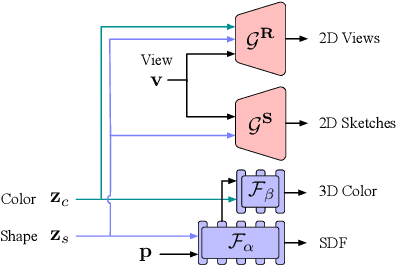
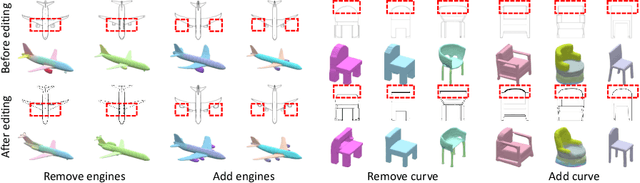
Creating and editing the shape and color of 3D objects require tremendous human effort and expertise. Compared to direct manipulation in 3D interfaces, 2D interactions such as sketches and scribbles are usually much more natural and intuitive for the users. In this paper, we propose a generic multi-modal generative model that couples the 2D modalities and implicit 3D representations through shared latent spaces. With the proposed model, versatile 3D generation and manipulation are enabled by simply propagating the editing from a specific 2D controlling modality through the latent spaces. For example, editing the 3D shape by drawing a sketch, re-colorizing the 3D surface via painting color scribbles on the 2D rendering, or generating 3D shapes of a certain category given one or a few reference images. Unlike prior works, our model does not require re-training or fine-tuning per editing task and is also conceptually simple, easy to implement, robust to input domain shifts, and flexible to diverse reconstruction on partial 2D inputs. We evaluate our framework on two representative 2D modalities of grayscale line sketches and rendered color images, and demonstrate that our method enables various shape manipulation and generation tasks with these 2D modalities.
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022
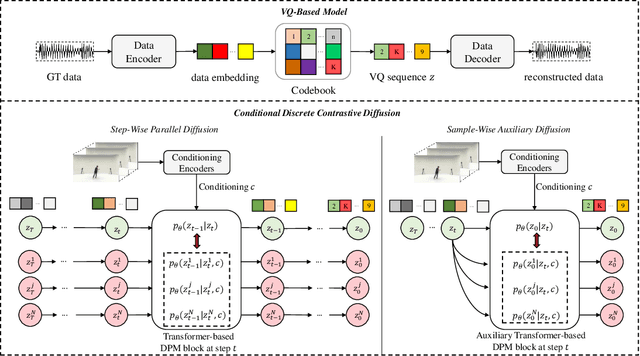
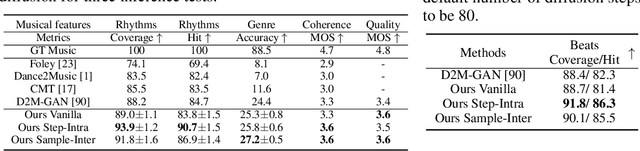
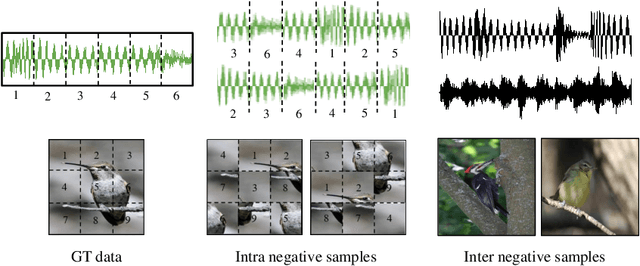
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.
Control-NeRF: Editable Feature Volumes for Scene Rendering and Manipulation
Apr 22, 2022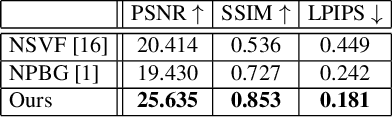
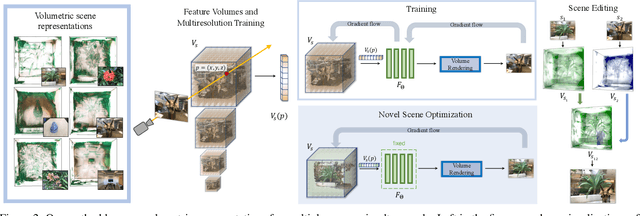
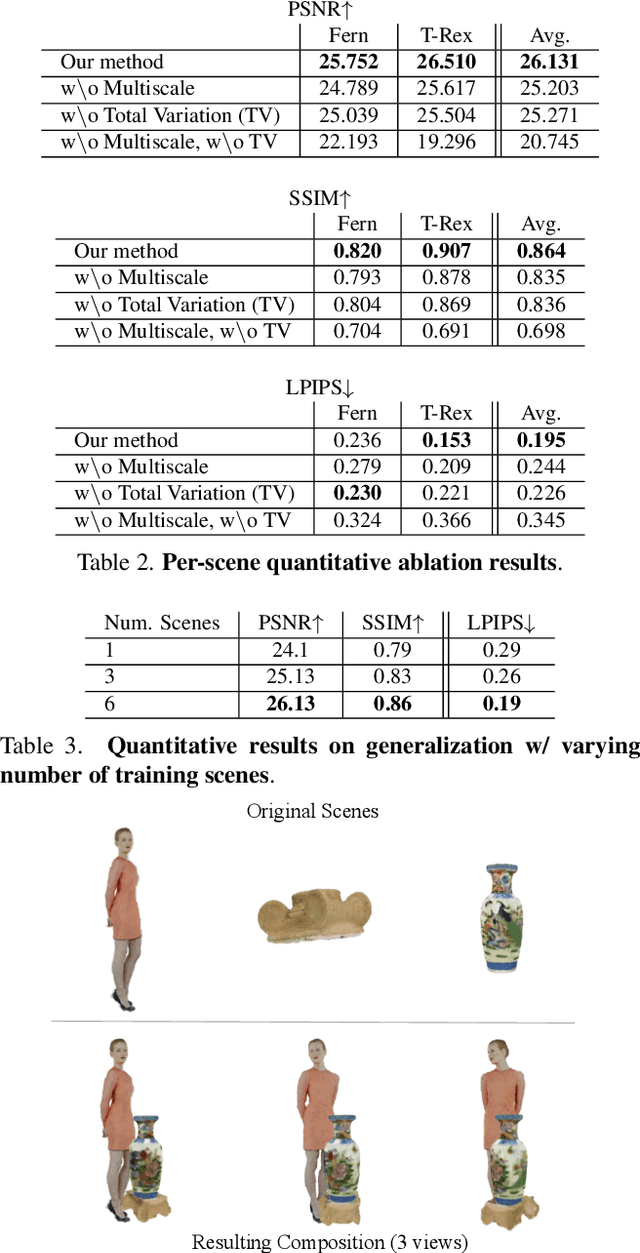

We present a novel method for performing flexible, 3D-aware image content manipulation while enabling high-quality novel view synthesis. While NeRF-based approaches are effective for novel view synthesis, such models memorize the radiance for every point in a scene within a neural network. Since these models are scene-specific and lack a 3D scene representation, classical editing such as shape manipulation, or combining scenes is not possible. Hence, editing and combining NeRF-based scenes has not been demonstrated. With the aim of obtaining interpretable and controllable scene representations, our model couples learnt scene-specific feature volumes with a scene agnostic neural rendering network. With this hybrid representation, we decouple neural rendering from scene-specific geometry and appearance. We can generalize to novel scenes by optimizing only the scene-specific 3D feature representation, while keeping the parameters of the rendering network fixed. The rendering function learnt during the initial training stage can thus be easily applied to new scenes, making our approach more flexible. More importantly, since the feature volumes are independent of the rendering model, we can manipulate and combine scenes by editing their corresponding feature volumes. The edited volume can then be plugged into the rendering model to synthesize high-quality novel views. We demonstrate various scene manipulations, including mixing scenes, deforming objects and inserting objects into scenes, while still producing photo-realistic results.
Quantized GAN for Complex Music Generation from Dance Videos
Apr 01, 2022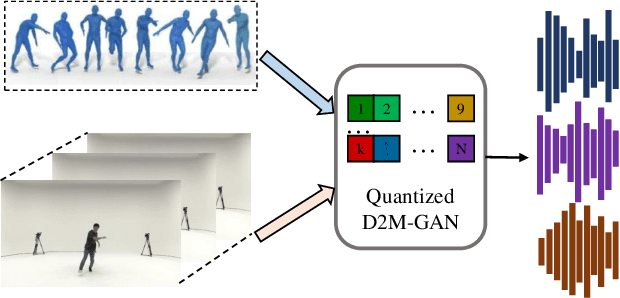
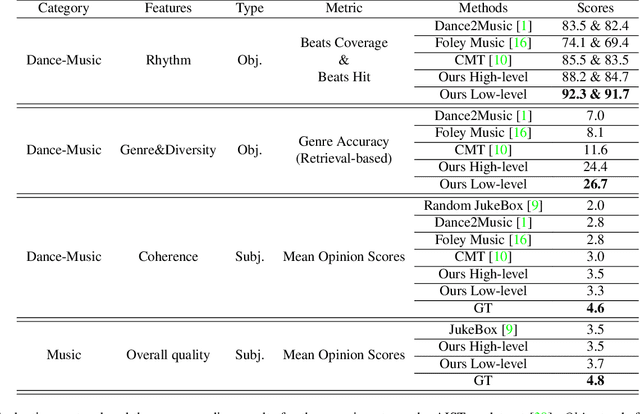
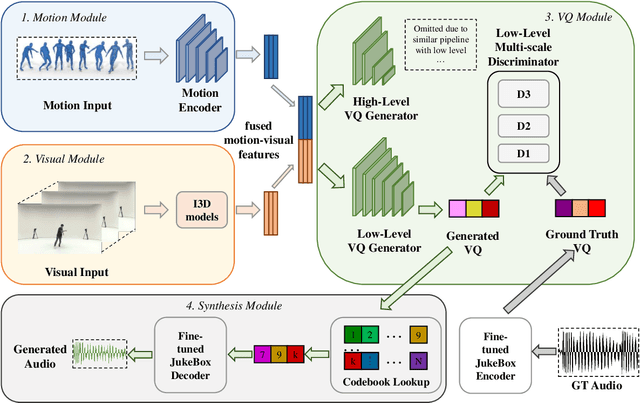
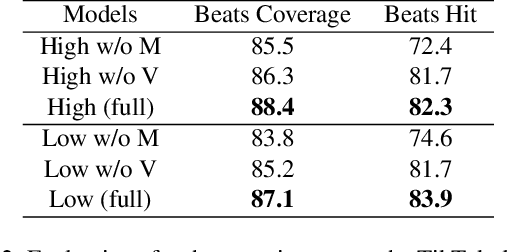
We present Dance2Music-GAN (D2M-GAN), a novel adversarial multi-modal framework that generates complex musical samples conditioned on dance videos. Our proposed framework takes dance video frames and human body motion as input, and learns to generate music samples that plausibly accompany the corresponding input. Unlike most existing conditional music generation works that generate specific types of mono-instrumental sounds using symbolic audio representations (e.g., MIDI), and that heavily rely on pre-defined musical synthesizers, in this work we generate dance music in complex styles (e.g., pop, breakdancing, etc.) by employing a Vector Quantized (VQ) audio representation, and leverage both its generality and the high abstraction capacity of its symbolic and continuous counterparts. By performing an extensive set of experiments on multiple datasets, and following a comprehensive evaluation protocol, we assess the generative quality of our approach against several alternatives. The quantitative results, which measure the music consistency, beats correspondence, and music diversity, clearly demonstrate the effectiveness of our proposed method. Last but not least, we curate a challenging dance-music dataset of in-the-wild TikTok videos, which we use to further demonstrate the efficacy of our approach in real-world applications - and which we hope to serve as a starting point for relevant future research.
R2L: Distilling Neural Radiance Field to Neural Light Field for Efficient Novel View Synthesis
Mar 31, 2022
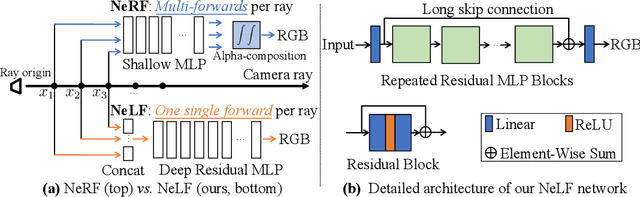
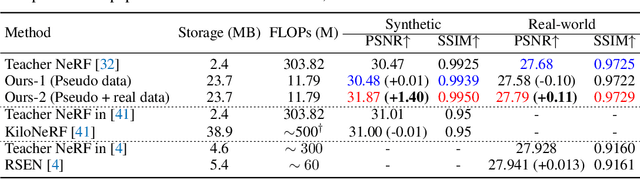
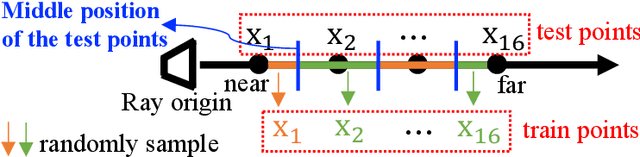
Recent research explosion on Neural Radiance Field (NeRF) shows the encouraging potential to represent complex scenes with neural networks. One major drawback of NeRF is its prohibitive inference time: Rendering a single pixel requires querying the NeRF network hundreds of times. To resolve it, existing efforts mainly attempt to reduce the number of required sampled points. However, the problem of iterative sampling still exists. On the other hand, Neural Light Field (NeLF) presents a more straightforward representation over NeRF in novel view synthesis -- the rendering of a pixel amounts to one single forward pass without ray-marching. In this work, we present a deep residual MLP network (88 layers) to effectively learn the light field. We show the key to successfully learning such a deep NeLF network is to have sufficient data, for which we transfer the knowledge from a pre-trained NeRF model via data distillation. Extensive experiments on both synthetic and real-world scenes show the merits of our method over other counterpart algorithms. On the synthetic scenes, we achieve 26-35x FLOPs reduction (per camera ray) and 28-31x runtime speedup, meanwhile delivering significantly better (1.4-2.8 dB average PSNR improvement) rendering quality than NeRF without any customized implementation tricks.