 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaceIt3D: Language-Guided Object Placement in Real 3D Scenes
May 08, 2025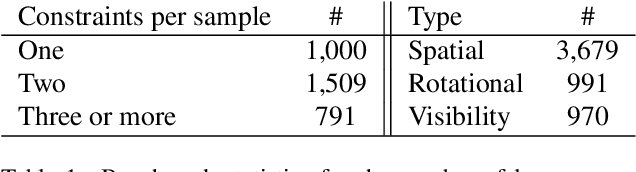
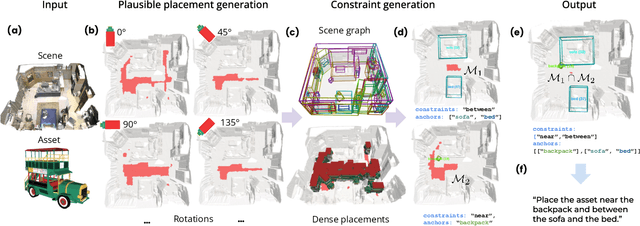
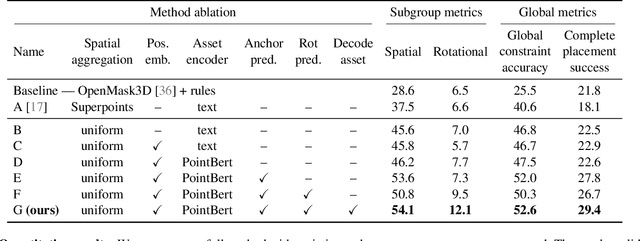
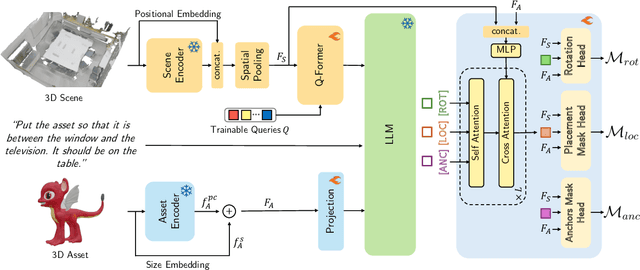
We introduce the novel task of Language-Guided Object Placement in Real 3D Scenes. Our model is given a 3D scene's point cloud, a 3D asset, and a textual prompt broadly describing where the 3D asset should be placed. The task here is to find a valid placement for the 3D asset that respects the prompt. Compared with other language-guided localization tasks in 3D scenes such as grounding, this task has specific challenges: it is ambiguous because it has multiple valid solutions, and it requires reasoning about 3D geometric relationships and free space. We inaugurate this task by proposing a new benchmark and evaluation protocol. We also introduce a new dataset for training 3D LLMs on this task, as well as the first method to serve as a non-trivial baseline. We believe that this challenging task and our new benchmark could become part of the suite of benchmarks used to evaluate and compare generalist 3D LLM models.
ZeroKey: Point-Level Reasoning and Zero-Shot 3D Keypoint Detection from Large Language Models
Dec 09, 2024



We propose a novel zero-shot approach for keypoint detection on 3D shapes. Point-level reasoning on visual data is challenging as it requires precise localization capability, posing problems even for powerful models like DINO or CLIP. Traditional methods for 3D keypoint detection rely heavily on annotated 3D datasets and extensive supervised training, limiting their scalability and applicability to new categories or domains. In contrast, our method utilizes the rich knowledge embedded within Multi-Modal Large Language Models (MLLMs). Specifically, we demonstrate, for the first time, that pixel-level annotations used to train recent MLLMs can be exploited for both extracting and naming salient keypoints on 3D models without any ground truth labels or supervision. Experimental evaluations demonstrate that our approach achieves competitive performance on standard benchmarks compared to supervised methods, despite not requiring any 3D keypoint annotations during training. Our results highlight the potential of integrating language models for localized 3D shape understanding. This work opens new avenues for cross-modal learning and underscores the effectiveness of MLLMs in contributing to 3D computer vision challenges.
3DCoMPaT$^{++}$: An improved Large-scale 3D Vision Dataset for Compositional Recognition
Oct 27, 2023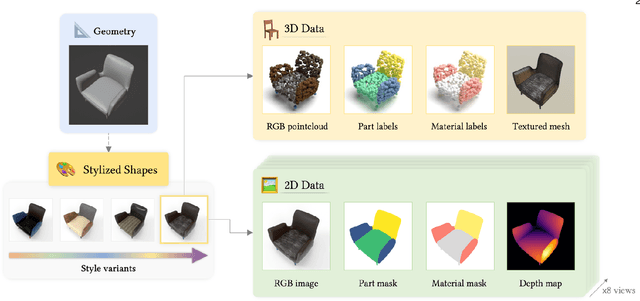
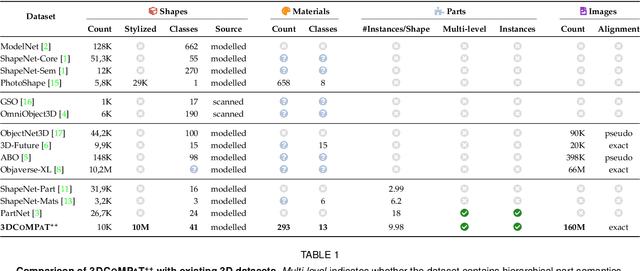

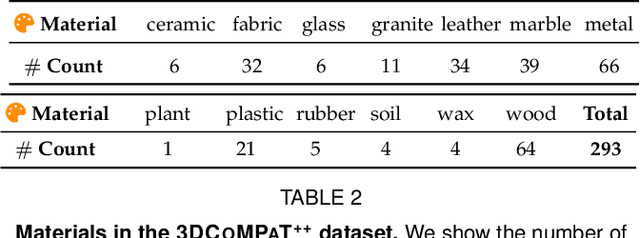
In this work, we present 3DCoMPaT$^{++}$, a multimodal 2D/3D dataset with 160 million rendered views of more than 10 million stylized 3D shapes carefully annotated at the part-instance level, alongside matching RGB point clouds, 3D textured meshes, depth maps, and segmentation masks. 3DCoMPaT$^{++}$ covers 41 shape categories, 275 fine-grained part categories, and 293 fine-grained material classes that can be compositionally applied to parts of 3D objects. We render a subset of one million stylized shapes from four equally spaced views as well as four randomized views, leading to a total of 160 million renderings. Parts are segmented at the instance level, with coarse-grained and fine-grained semantic levels. We introduce a new task, called Grounded CoMPaT Recognition (GCR), to collectively recognize and ground compositions of materials on parts of 3D objects. Additionally, we report the outcomes of a data challenge organized at CVPR2023, showcasing the winning method's utilization of a modified PointNet$^{++}$ model trained on 6D inputs, and exploring alternative techniques for GCR enhancement. We hope our work will help ease future research on compositional 3D Vision.
Zero-Shot 3D Shape Correspondence
Jun 05, 2023We propose a novel zero-shot approach to computing correspondences between 3D shapes. Existing approaches mainly focus on isometric and near-isometric shape pairs (e.g., human vs. human), but less attention has been given to strongly non-isometric and inter-class shape matching (e.g., human vs. cow). To this end, we introduce a fully automatic method that exploits the exceptional reasoning capabilities of recent foundation models in language and vision to tackle difficult shape correspondence problems. Our approach comprises multiple stages. First, we classify the 3D shapes in a zero-shot manner by feeding rendered shape views to a language-vision model (e.g., BLIP2) to generate a list of class proposals per shape. These proposals are unified into a single class per shape by employing the reasoning capabilities of ChatGPT. Second, we attempt to segment the two shapes in a zero-shot manner, but in contrast to the co-segmentation problem, we do not require a mutual set of semantic regions. Instead, we propose to exploit the in-context learning capabilities of ChatGPT to generate two different sets of semantic regions for each shape and a semantic mapping between them. This enables our approach to match strongly non-isometric shapes with significant differences in geometric structure. Finally, we employ the generated semantic mapping to produce coarse correspondences that can further be refined by the functional maps framework to produce dense point-to-point maps. Our approach, despite its simplicity, produces highly plausible results in a zero-shot manner, especially between strongly non-isometric shapes.
SATR: Zero-Shot Semantic Segmentation of 3D Shapes
Apr 11, 2023We explore the task of zero-shot semantic segmentation of 3D shapes by using large-scale off-the-shelf 2D image recognition models. Surprisingly, we find that modern zero-shot 2D object detectors are better suited for this task than contemporary text/image similarity predictors or even zero-shot 2D segmentation networks. Our key finding is that it is possible to extract accurate 3D segmentation maps from multi-view bounding box predictions by using the topological properties of the underlying surface. For this, we develop the Segmentation Assignment with Topological Reweighting (SATR) algorithm and evaluate it on two challenging benchmarks: FAUST and ShapeNetPart. On these datasets, SATR achieves state-of-the-art performance and outperforms prior work by at least 22\% on average in terms of mIoU. Our source code and data will be publicly released. Project webpage: https://samir55.github.io/SATR/
ScanEnts3D: Exploiting Phrase-to-3D-Object Correspondences for Improved Visio-Linguistic Models in 3D Scenes
Dec 12, 2022

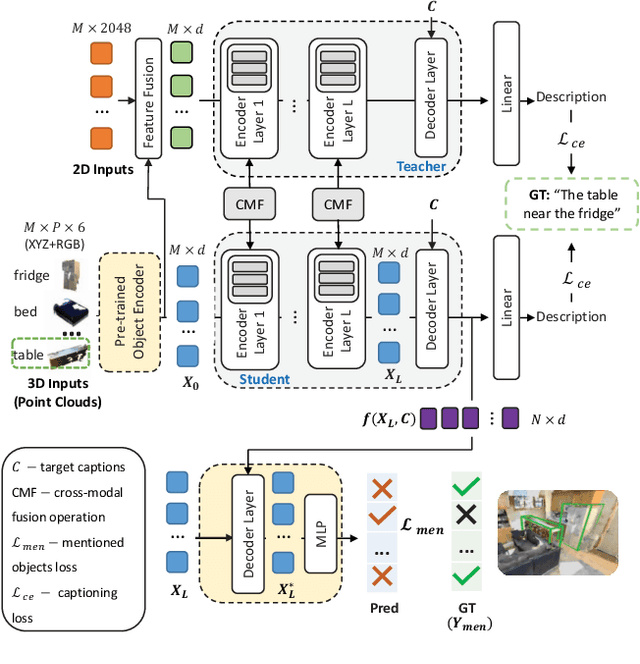
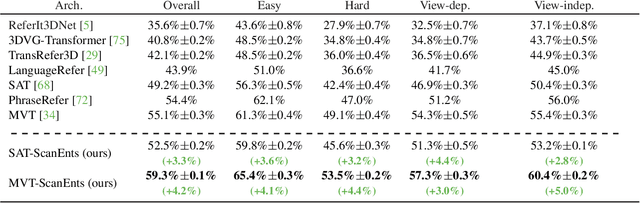
The two popular datasets ScanRefer [16] and ReferIt3D [3] connect natural language to real-world 3D data. In this paper, we curate a large-scale and complementary dataset extending both the aforementioned ones by associating all objects mentioned in a referential sentence to their underlying instances inside a 3D scene. Specifically, our Scan Entities in 3D (ScanEnts3D) dataset provides explicit correspondences between 369k objects across 84k natural referential sentences, covering 705 real-world scenes. Crucially, we show that by incorporating intuitive losses that enable learning from this novel dataset, we can significantly improve the performance of several recently introduced neural listening architectures, including improving the SoTA in both the Nr3D and ScanRefer benchmarks by 4.3% and 5.0%, respectively. Moreover, we experiment with competitive baselines and recent methods for the task of language generation and show that, as with neural listeners, 3D neural speakers can also noticeably benefit by training with ScanEnts3D, including improving the SoTA by 13.2 CIDEr points on the Nr3D benchmark. Overall, our carefully conducted experimental studies strongly support the conclusion that, by learning on ScanEnts3D, commonly used visio-linguistic 3D architectures can become more efficient and interpretable in their generalization without needing to provide these newly collected annotations at test time. The project's webpage is https://scanents3d.github.io/ .