 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaceIt3D: Language-Guided Object Placement in Real 3D Scenes
May 08, 2025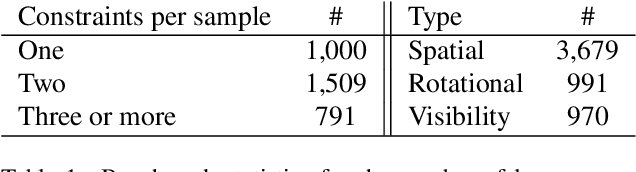
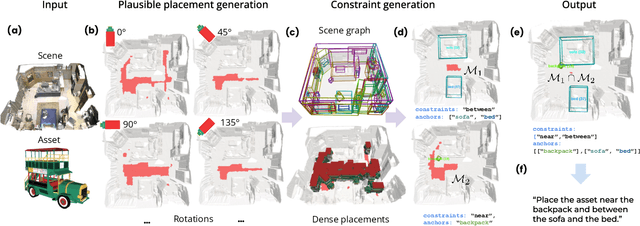
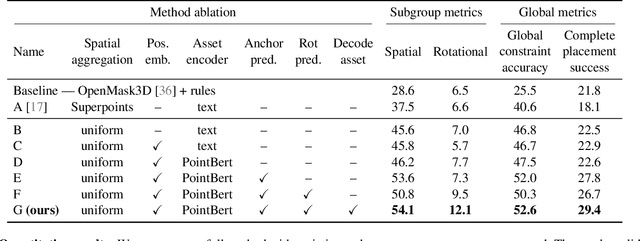
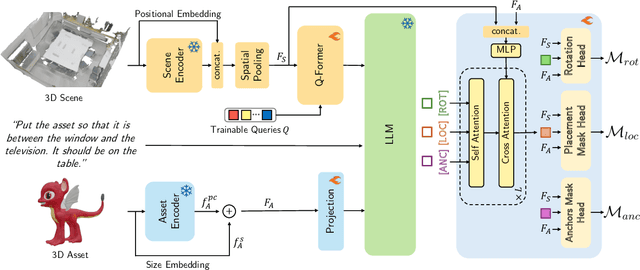
We introduce the novel task of Language-Guided Object Placement in Real 3D Scenes. Our model is given a 3D scene's point cloud, a 3D asset, and a textual prompt broadly describing where the 3D asset should be placed. The task here is to find a valid placement for the 3D asset that respects the prompt. Compared with other language-guided localization tasks in 3D scenes such as grounding, this task has specific challenges: it is ambiguous because it has multiple valid solutions, and it requires reasoning about 3D geometric relationships and free space. We inaugurate this task by proposing a new benchmark and evaluation protocol. We also introduce a new dataset for training 3D LLMs on this task, as well as the first method to serve as a non-trivial baseline. We believe that this challenging task and our new benchmark could become part of the suite of benchmarks used to evaluate and compare generalist 3D LLM models.
Morpheus: Text-Driven 3D Gaussian Splat Shape and Color Stylization
Mar 03, 2025
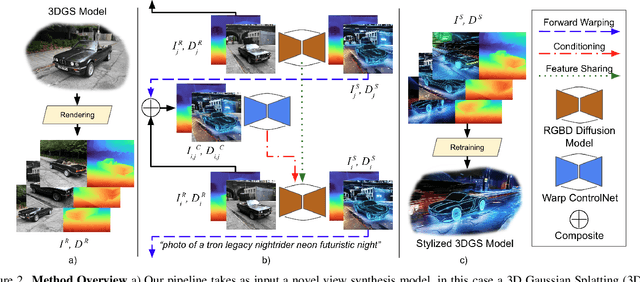
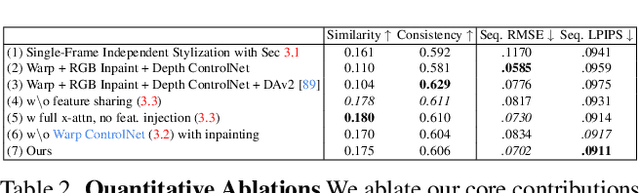
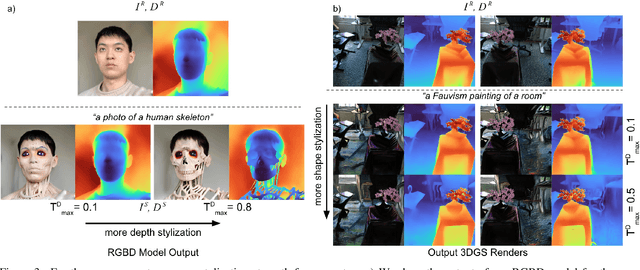
Exploring real-world spaces using novel-view synthesis is fun, and reimagining those worlds in a different style adds another layer of excitement. Stylized worlds can also be used for downstream tasks where there is limited training data and a need to expand a model's training distribution. Most current novel-view synthesis stylization techniques lack the ability to convincingly change geometry. This is because any geometry change requires increased style strength which is often capped for stylization stability and consistency. In this work, we propose a new autoregressive 3D Gaussian Splatting stylization method. As part of this method, we contribute a new RGBD diffusion model that allows for strength control over appearance and shape stylization. To ensure consistency across stylized frames, we use a combination of novel depth-guided cross attention, feature injection, and a Warp ControlNet conditioned on composite frames for guiding the stylization of new frames. We validate our method via extensive qualitative results, quantitative experiments, and a user study. Code will be released online.
DoubleTake: Geometry Guided Depth Estimation
Jun 26, 2024
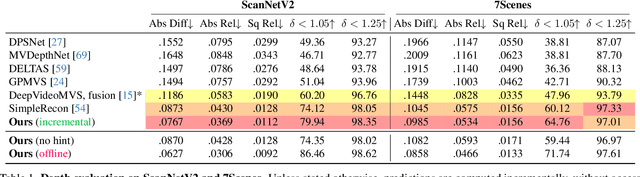
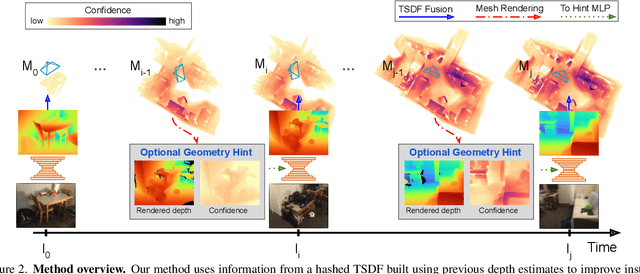
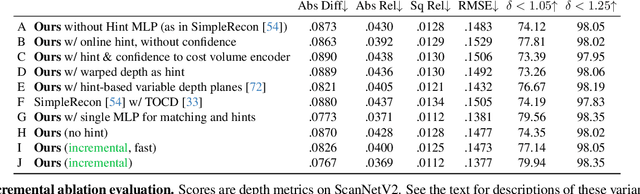
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
AirPlanes: Accurate Plane Estimation via 3D-Consistent Embeddings
Jun 13, 2024Extracting planes from a 3D scene is useful for downstream tasks in robotics and augmented reality. In this paper we tackle the problem of estimating the planar surfaces in a scene from posed images. Our first finding is that a surprisingly competitive baseline results from combining popular clustering algorithms with recent improvements in 3D geometry estimation. However, such purely geometric methods are understandably oblivious to plane semantics, which are crucial to discerning distinct planes. To overcome this limitation, we propose a method that predicts multi-view consistent plane embeddings that complement geometry when clustering points into planes. We show through extensive evaluation on the ScanNetV2 dataset that our new method outperforms existing approaches and our strong geometric baseline for the task of plane estimation.
Virtual Occlusions Through Implicit Depth
May 11, 2023



For augmented reality (AR), it is important that virtual assets appear to `sit among' real world objects. The virtual element should variously occlude and be occluded by real matter, based on a plausible depth ordering. This occlusion should be consistent over time as the viewer's camera moves. Unfortunately, small mistakes in the estimated scene depth can ruin the downstream occlusion mask, and thereby the AR illusion. Especially in real-time settings, depths inferred near boundaries or across time can be inconsistent. In this paper, we challenge the need for depth-regression as an intermediate step. We instead propose an implicit model for depth and use that to predict the occlusion mask directly. The inputs to our network are one or more color images, plus the known depths of any virtual geometry. We show how our occlusion predictions are more accurate and more temporally stable than predictions derived from traditional depth-estimation models. We obtain state-of-the-art occlusion results on the challenging ScanNetv2 dataset and superior qualitative results on real scenes.