 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-View Geometry Scoring Without Correspondences
Jun 02, 2023Camera pose estimation for two-view geometry traditionally relies on RANSAC. Normally, a multitude of image correspondences leads to a pool of proposed hypotheses, which are then scored to find a winning model. The inlier count is generally regarded as a reliable indicator of "consensus". We examine this scoring heuristic, and find that it favors disappointing models under certain circumstances. As a remedy, we propose the Fundamental Scoring Network (FSNet), which infers a score for a pair of overlapping images and any proposed fundamental matrix. It does not rely on sparse correspondences, but rather embodies a two-view geometry model through an epipolar attention mechanism that predicts the pose error of the two images. FSNet can be incorporated into traditional RANSAC loops. We evaluate FSNet on fundamental and essential matrix estimation on indoor and outdoor datasets, and establish that FSNet can successfully identify good poses for pairs of images with few or unreliable correspondences. Besides, we show that naively combining FSNet with MAGSAC++ scoring approach achieves state of the art results.
Virtual Occlusions Through Implicit Depth
May 11, 2023



For augmented reality (AR), it is important that virtual assets appear to `sit among' real world objects. The virtual element should variously occlude and be occluded by real matter, based on a plausible depth ordering. This occlusion should be consistent over time as the viewer's camera moves. Unfortunately, small mistakes in the estimated scene depth can ruin the downstream occlusion mask, and thereby the AR illusion. Especially in real-time settings, depths inferred near boundaries or across time can be inconsistent. In this paper, we challenge the need for depth-regression as an intermediate step. We instead propose an implicit model for depth and use that to predict the occlusion mask directly. The inputs to our network are one or more color images, plus the known depths of any virtual geometry. We show how our occlusion predictions are more accurate and more temporally stable than predictions derived from traditional depth-estimation models. We obtain state-of-the-art occlusion results on the challenging ScanNetv2 dataset and superior qualitative results on real scenes.
Improved Handling of Motion Blur in Online Object Detection
Nov 29, 2020
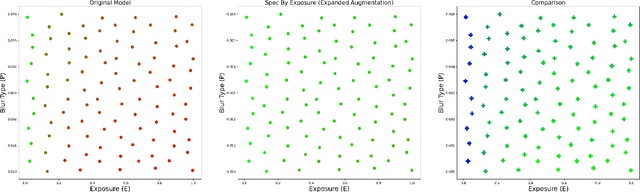
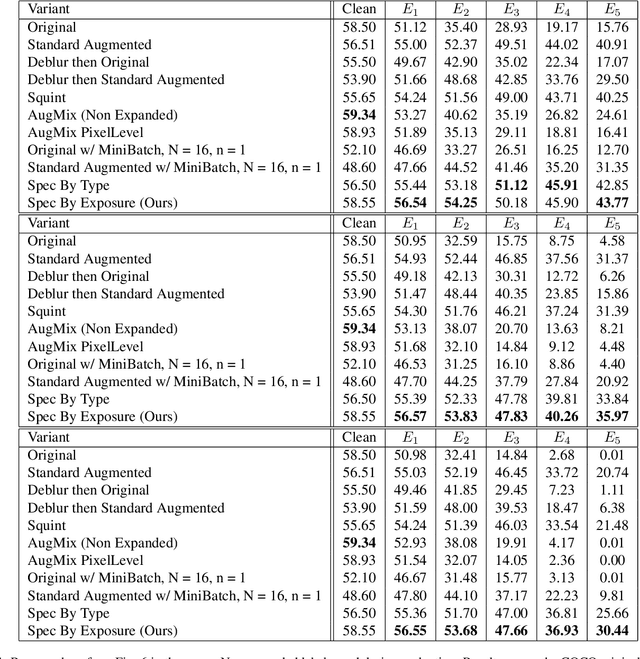
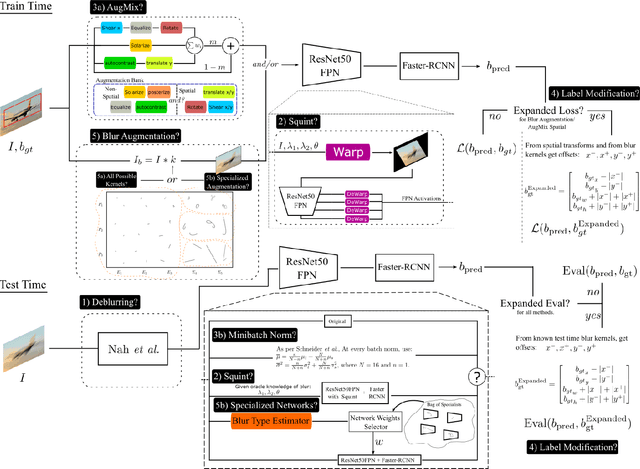
We wish to detect specific categories of objects, for online vision systems that will run in the real world. Object detection is already very challenging. It is even harder when the images are blurred, from the camera being in a car or a hand-held phone. Most existing efforts either focused on sharp images, with easy to label ground truth, or they have treated motion blur as one of many generic corruptions. Instead, we focus especially on the details of egomotion induced blur. We explore five classes of remedies, where each targets different potential causes for the performance gap between sharp and blurred images. For example, first deblurring an image changes its human interpretability, but at present, only partly improves object detection. The other four classes of remedies address multi-scale texture, out-of-distribution testing, label generation, and conditioning by blur-type. Surprisingly, we discover that custom label generation aimed at resolving spatial ambiguity, ahead of all others, markedly improves object detection. Also, in contrast to findings from classification, we see a noteworthy boost by conditioning our model on bespoke categories of motion blur. We validate and cross-breed the different remedies experimentally on blurred COCO images, producing an easy and practical favorite model with superior detection rates.
DiverseNet: When One Right Answer is not Enough
Aug 24, 2020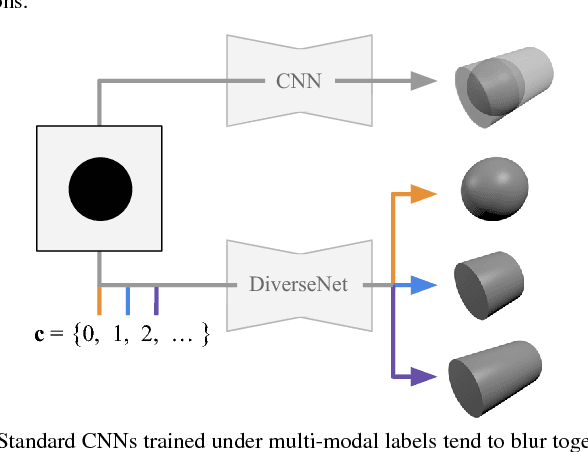
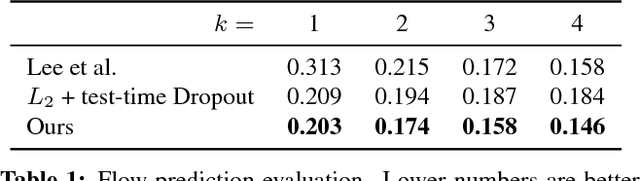
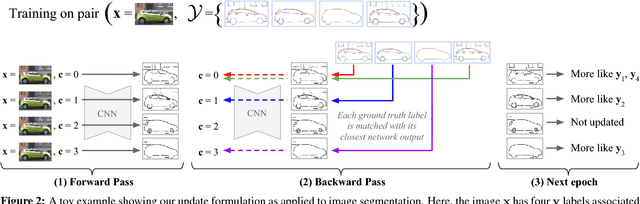
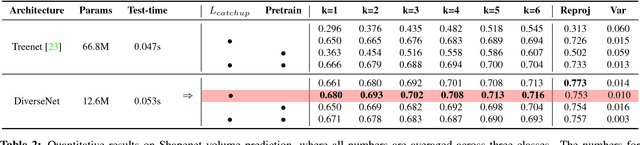
Many structured prediction tasks in machine vision have a collection of acceptable answers, instead of one definitive ground truth answer. Segmentation of images, for example, is subject to human labeling bias. Similarly, there are multiple possible pixel values that could plausibly complete occluded image regions. State-of-the art supervised learning methods are typically optimized to make a single test-time prediction for each query, failing to find other modes in the output space. Existing methods that allow for sampling often sacrifice speed or accuracy. We introduce a simple method for training a neural network, which enables diverse structured predictions to be made for each test-time query. For a single input, we learn to predict a range of possible answers. We compare favorably to methods that seek diversity through an ensemble of networks. Such stochastic multiple choice learning faces mode collapse, where one or more ensemble members fail to receive any training signal. Our best performing solution can be deployed for various tasks, and just involves small modifications to the existing single-mode architecture, loss function, and training regime. We demonstrate that our method results in quantitative improvements across three challenging tasks: 2D image completion, 3D volume estimation, and flow prediction.
Learning Stereo from Single Images
Aug 20, 2020
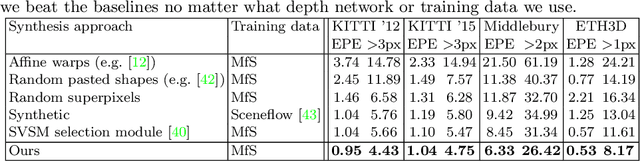
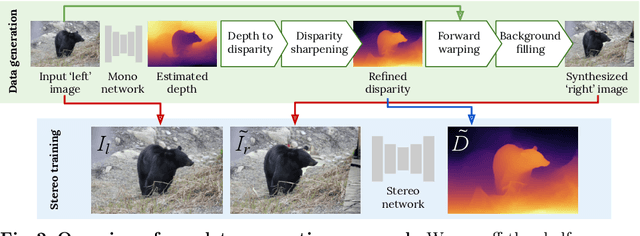

Supervised deep networks are among the best methods for finding correspondences in stereo image pairs. Like all supervised approaches, these networks require ground truth data during training. However, collecting large quantities of accurate dense correspondence data is very challenging. We propose that it is unnecessary to have such a high reliance on ground truth depths or even corresponding stereo pairs. Inspired by recent progress in monocular depth estimation, we generate plausible disparity maps from single images. In turn, we use those flawed disparity maps in a carefully designed pipeline to generate stereo training pairs. Training in this manner makes it possible to convert any collection of single RGB images into stereo training data. This results in a significant reduction in human effort, with no need to collect real depths or to hand-design synthetic data. We can consequently train a stereo matching network from scratch on datasets like COCO, which were previously hard to exploit for stereo. Through extensive experiments we show that our approach outperforms stereo networks trained with standard synthetic datasets, when evaluated on KITTI, ETH3D, and Middlebury.
Image Stylization for Robust Features
Aug 16, 2020



Local features that are robust to both viewpoint and appearance changes are crucial for many computer vision tasks. In this work we investigate if photorealistic image stylization improves robustness of local features to not only day-night, but also weather and season variations. We show that image stylization in addition to color augmentation is a powerful method of learning robust features. We evaluate learned features on visual localization benchmarks, outperforming state of the art baseline models despite training without ground-truth 3D correspondences using synthetic homographies only. We use trained feature networks to compete in Long-Term Visual Localization and Map-based Localization for Autonomous Driving challenges achieving competitive scores.
Predicting Visual Overlap of Images Through Interpretable Non-Metric Box Embeddings
Aug 13, 2020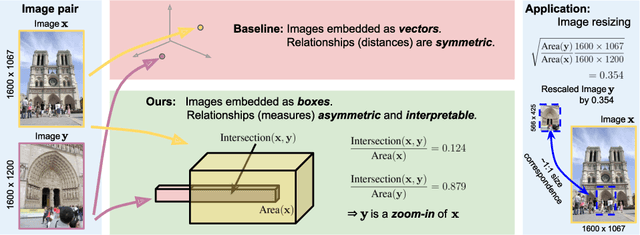
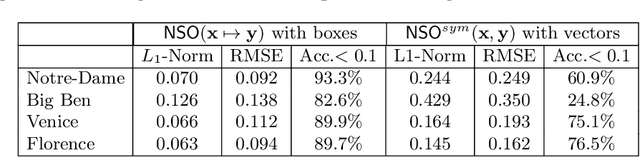

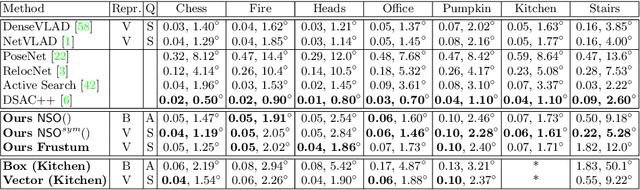
To what extent are two images picturing the same 3D surfaces? Even when this is a known scene, the answer typically requires an expensive search across scale space, with matching and geometric verification of large sets of local features. This expense is further multiplied when a query image is evaluated against a gallery, e.g. in visual relocalization. While we don't obviate the need for geometric verification, we propose an interpretable image-embedding that cuts the search in scale space to essentially a lookup. Our approach measures the asymmetric relation between two images. The model then learns a scene-specific measure of similarity, from training examples with known 3D visible-surface overlaps. The result is that we can quickly identify, for example, which test image is a close-up version of another, and by what scale factor. Subsequently, local features need only be detected at that scale. We validate our scene-specific model by showing how this embedding yields competitive image-matching results, while being simpler, faster, and also interpretable by humans.
Footprints and Free Space from a Single Color Image
Apr 14, 2020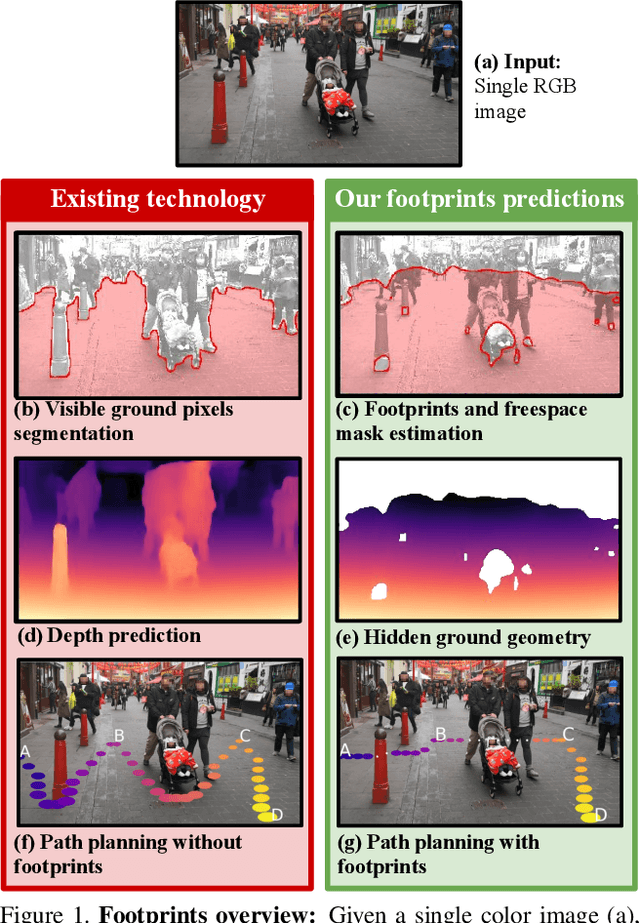

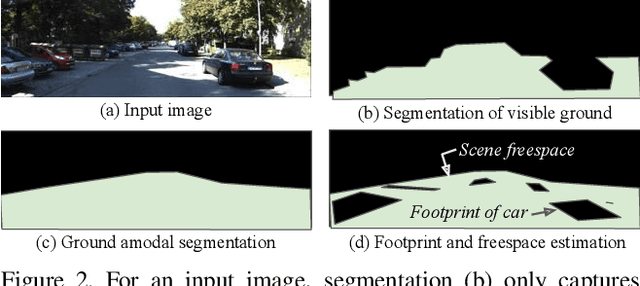

Understanding the shape of a scene from a single color image is a formidable computer vision task. However, most methods aim to predict the geometry of surfaces that are visible to the camera, which is of limited use when planning paths for robots or augmented reality agents. Such agents can only move when grounded on a traversable surface, which we define as the set of classes which humans can also walk over, such as grass, footpaths and pavement. Models which predict beyond the line of sight often parameterize the scene with voxels or meshes, which can be expensive to use in machine learning frameworks. We introduce a model to predict the geometry of both visible and occluded traversable surfaces, given a single RGB image as input. We learn from stereo video sequences, using camera poses, per-frame depth and semantic segmentation to form training data, which is used to supervise an image-to-image network. We train models from the KITTI driving dataset, the indoor Matterport dataset, and from our own casually captured stereo footage. We find that a surprisingly low bar for spatial coverage of training scenes is required. We validate our algorithm against a range of strong baselines, and include an assessment of our predictions for a path-planning task.
Self-Supervised Monocular Depth Hints
Sep 19, 2019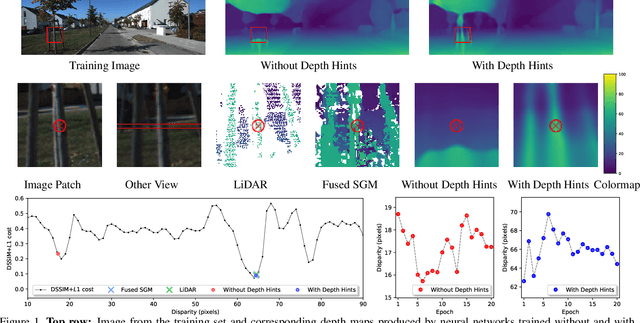

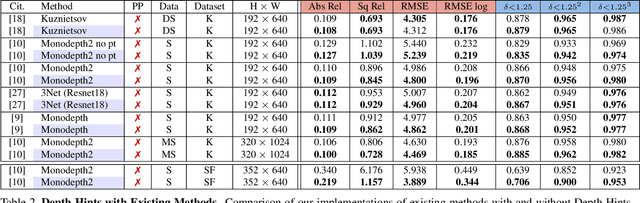
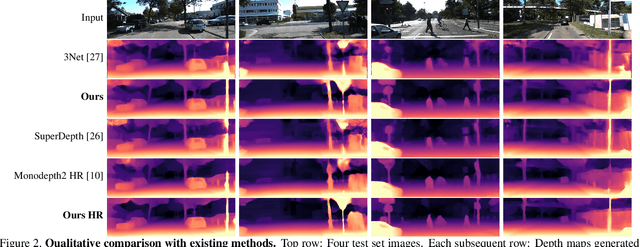
Monocular depth estimators can be trained with various forms of self-supervision from binocular-stereo data to circumvent the need for high-quality laser scans or other ground-truth data. The disadvantage, however, is that the photometric reprojection losses used with self-supervised learning typically have multiple local minima. These plausible-looking alternatives to ground truth can restrict what a regression network learns, causing it to predict depth maps of limited quality. As one prominent example, depth discontinuities around thin structures are often incorrectly estimated by current state-of-the-art methods. Here, we study the problem of ambiguous reprojections in depth prediction from stereo-based self-supervision, and introduce Depth Hints to alleviate their effects. Depth Hints are complementary depth suggestions obtained from simple off-the-shelf stereo algorithms. These hints enhance an existing photometric loss function, and are used to guide a network to learn better weights. They require no additional data, and are assumed to be right only sometimes. We show that using our Depth Hints gives a substantial boost when training several leading self-supervised-from-stereo models, not just our own. Further, combined with other good practices, we produce state-of-the-art depth predictions on the KITTI benchmark.
Virtual Adversarial Ladder Networks For Semi-supervised Learning
Dec 12, 2017
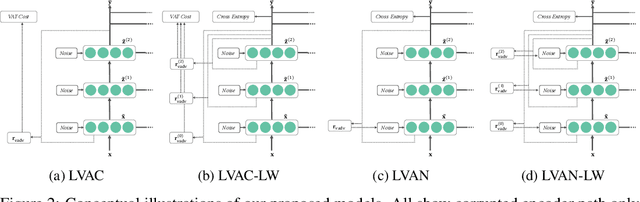
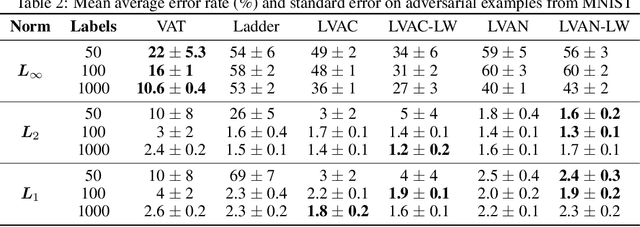
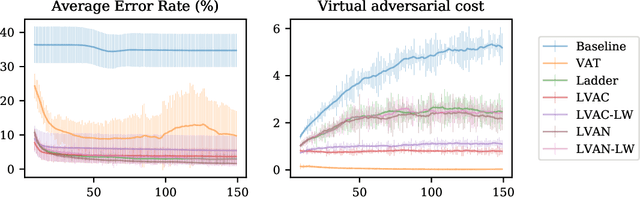
Semi-supervised learning (SSL) partially circumvents the high cost of labeling data by augmenting a small labeled dataset with a large and relatively cheap unlabeled dataset drawn from the same distribution. This paper offers a novel interpretation of two deep learning-based SSL approaches, ladder networks and virtual adversarial training (VAT), as applying distributional smoothing to their respective latent spaces. We propose a class of models that fuse these approaches. We achieve near-supervised accuracy with high consistency on the MNIST dataset using just 5 labels per class: our best model, ladder with layer-wise virtual adversarial noise (LVAN-LW), achieves 1.42% +/- 0.12 average error rate on the MNIST test set, in comparison with 1.62% +/- 0.65 reported for the ladder network. On adversarial examples generated with L2-normalized fast gradient method, LVAN-LW trained with 5 examples per class achieves average error rate 2.4% +/- 0.3 compared to 68.6% +/- 6.5 for the ladder network and 9.9% +/- 7.5 for VAT.