 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Coordinate Reconstruction Priors
Oct 14, 2025Scene coordinate regression (SCR) models have proven to be powerful implicit scene representations for 3D vision, enabling visual relocalization and structure-from-motion. SCR models are trained specifically for one scene. If training images imply insufficient multi-view constraints SCR models degenerate. We present a probabilistic reinterpretation of training SCR models, which allows us to infuse high-level reconstruction priors. We investigate multiple such priors, ranging from simple priors over the distribution of reconstructed depth values to learned priors over plausible scene coordinate configurations. For the latter, we train a 3D point cloud diffusion model on a large corpus of indoor scans. Our priors push predicted 3D scene points towards plausible geometry at each training step to increase their likelihood. On three indoor datasets our priors help learning better scene representations, resulting in more coherent scene point clouds, higher registration rates and better camera poses, with a positive effect on down-stream tasks such as novel view synthesis and camera relocalization.
Matching 2D Images in 3D: Metric Relative Pose from Metric Correspondences
Apr 09, 2024



Given two images, we can estimate the relative camera pose between them by establishing image-to-image correspondences. Usually, correspondences are 2D-to-2D and the pose we estimate is defined only up to scale. Some applications, aiming at instant augmented reality anywhere, require scale-metric pose estimates, and hence, they rely on external depth estimators to recover the scale. We present MicKey, a keypoint matching pipeline that is able to predict metric correspondences in 3D camera space. By learning to match 3D coordinates across images, we are able to infer the metric relative pose without depth measurements. Depth measurements are also not required for training, nor are scene reconstructions or image overlap information. MicKey is supervised only by pairs of images and their relative poses. MicKey achieves state-of-the-art performance on the Map-Free Relocalisation benchmark while requiring less supervision than competing approaches.
Two-View Geometry Scoring Without Correspondences
Jun 02, 2023Camera pose estimation for two-view geometry traditionally relies on RANSAC. Normally, a multitude of image correspondences leads to a pool of proposed hypotheses, which are then scored to find a winning model. The inlier count is generally regarded as a reliable indicator of "consensus". We examine this scoring heuristic, and find that it favors disappointing models under certain circumstances. As a remedy, we propose the Fundamental Scoring Network (FSNet), which infers a score for a pair of overlapping images and any proposed fundamental matrix. It does not rely on sparse correspondences, but rather embodies a two-view geometry model through an epipolar attention mechanism that predicts the pose error of the two images. FSNet can be incorporated into traditional RANSAC loops. We evaluate FSNet on fundamental and essential matrix estimation on indoor and outdoor datasets, and establish that FSNet can successfully identify good poses for pairs of images with few or unreliable correspondences. Besides, we show that naively combining FSNet with MAGSAC++ scoring approach achieves state of the art results.
ScaleNet: A Shallow Architecture for Scale Estimation
Dec 23, 2021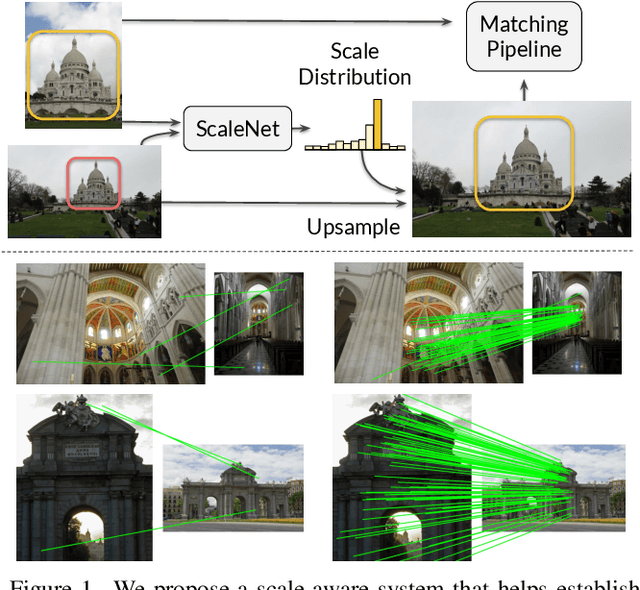

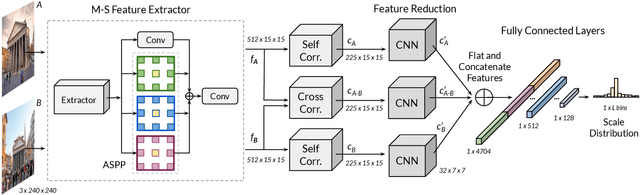

In this paper, we address the problem of estimating scale factors between images. We formulate the scale estimation problem as a prediction of a probability distribution over scale factors. We design a new architecture, ScaleNet, that exploits dilated convolutions as well as self and cross-correlation layers to predict the scale between images. We demonstrate that rectifying images with estimated scales leads to significant performance improvements for various tasks and methods. Specifically, we show how ScaleNet can be combined with sparse local features and dense correspondence networks to improve camera pose estimation, 3D reconstruction, or dense geometric matching in different benchmarks and datasets. We provide an extensive evaluation on several tasks and analyze the computational overhead of ScaleNet. The code, evaluation protocols, and trained models are publicly available at https://github.com/axelBarroso/ScaleNet.
HyNet: Local Descriptor with Hybrid Similarity Measure and Triplet Loss
Jun 17, 2020
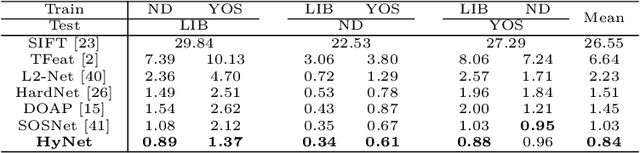
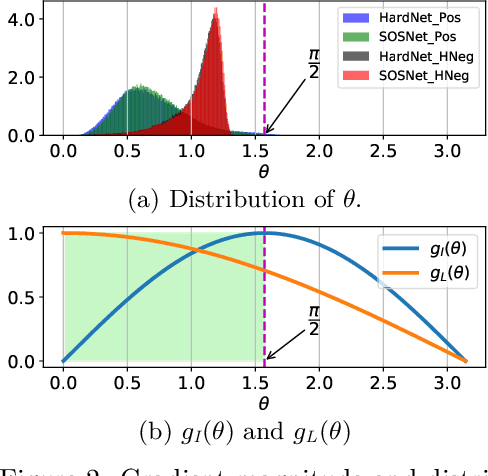

Recent works show that local descriptor learning benefits from the use of L2 normalisation, however, an in-depth analysis of this effect lacks in the literature. In this paper, we investigate how L2 normalisation affects the back-propagated descriptor gradients during training. Based on our observations, we propose HyNet, a new local descriptor that leads to state-of-the-art results in matching. HyNet introduces a hybrid similarity measure for triplet margin loss, a regularisation term constraining the descriptor norm, and a new network architecture that performs L2 normalisation of all intermediate feature maps and the output descriptors. HyNet surpasses previous methods by a significant margin on standard benchmarks that include patch matching, verification, and retrieval, as well as outperforming full end-to-end methods on 3D reconstruction tasks.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020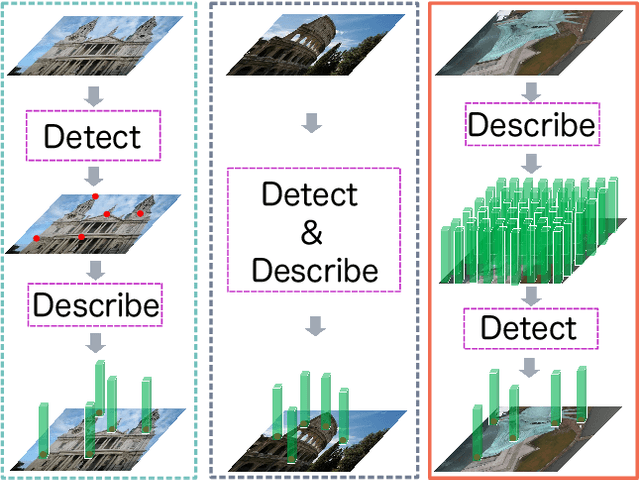
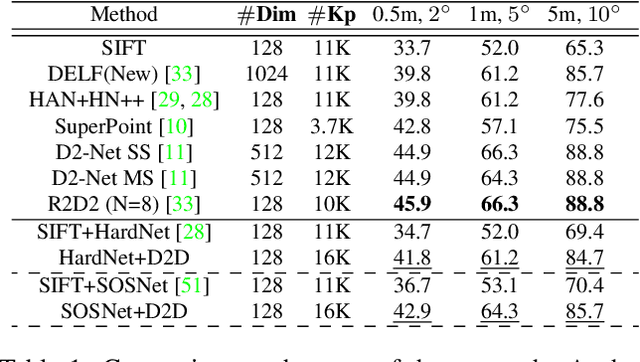
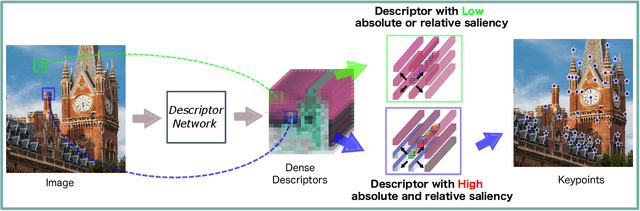
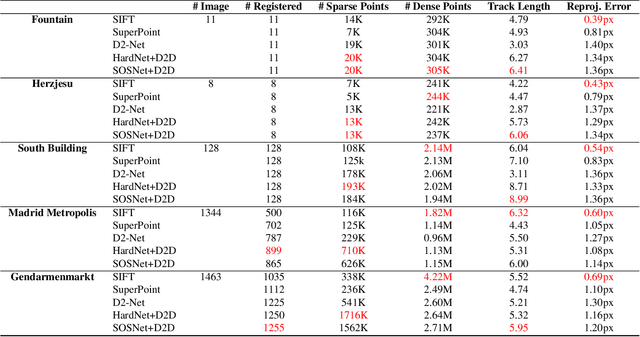
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.
HDD-Net: Hybrid Detector Descriptor with Mutual Interactive Learning
May 12, 2020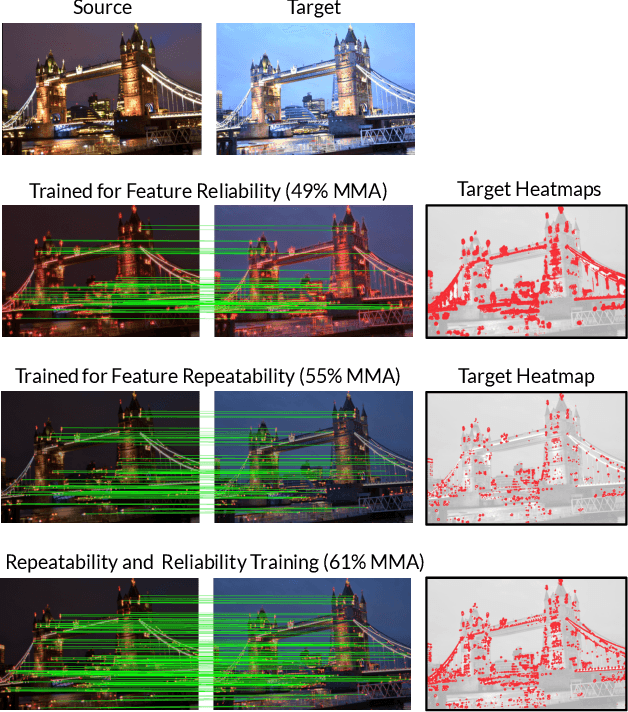

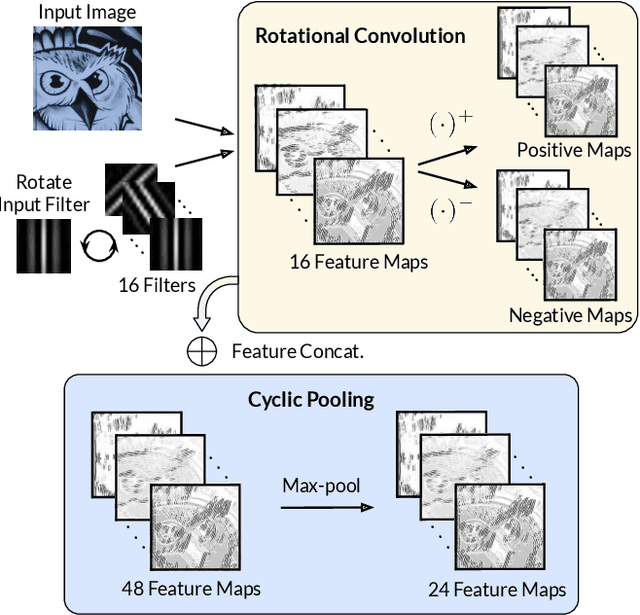

Local feature extraction remains an active research area due to the advances in fields such as SLAM, 3D reconstructions, or AR applications. The success in these applications relies on the performance of the feature detector and descriptor. While the detector-descriptor interaction of most methods is based on unifying in single network detections and descriptors, we propose a method that treats both extractions independently and focuses on their interaction in the learning process rather than by parameter sharing. We formulate the classical hard-mining triplet loss as a new detector optimisation term to refine candidate positions based on the descriptor map. We propose a dense descriptor that uses a multi-scale approach and a hybrid combination of hand-crafted and learned features to obtain rotation and scale robustness by design. We evaluate our method extensively on different benchmarks and show improvements over the state of the art in terms of image matching on HPatches and 3D reconstruction quality while keeping on par on camera localisation tasks.