 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffine-based Deformable Attention and Selective Fusion for Semi-dense Matching
May 22, 2024



Identifying robust and accurate correspondences across images is a fundamental problem in computer vision that enables various downstream tasks. Recent semi-dense matching methods emphasize the effectiveness of fusing relevant cross-view information through Transformer. In this paper, we propose several improvements upon this paradigm. Firstly, we introduce affine-based local attention to model cross-view deformations. Secondly, we present selective fusion to merge local and global messages from cross attention. Apart from network structure, we also identify the importance of enforcing spatial smoothness in loss design, which has been omitted by previous works. Based on these augmentations, our network demonstrate strong matching capacity under different settings. The full version of our network achieves state-of-the-art performance among semi-dense matching methods at a similar cost to LoFTR, while the slim version reaches LoFTR baseline's performance with only 15% computation cost and 18% parameters.
ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer
Aug 30, 2022
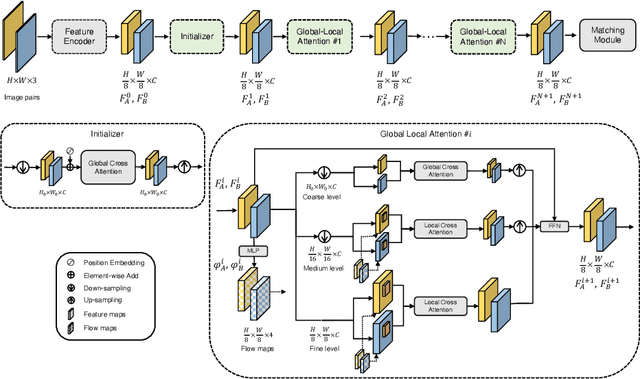
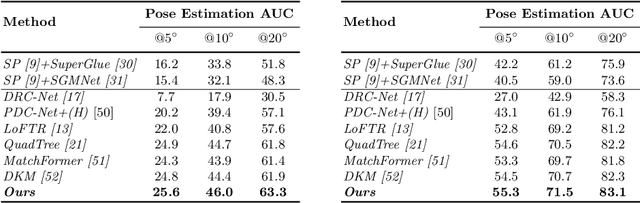

Generating robust and reliable correspondences across images is a fundamental task for a diversity of applications. To capture context at both global and local granularity, we propose ASpanFormer, a Transformer-based detector-free matcher that is built on hierarchical attention structure, adopting a novel attention operation which is capable of adjusting attention span in a self-adaptive manner. To achieve this goal, first, flow maps are regressed in each cross attention phase to locate the center of search region. Next, a sampling grid is generated around the center, whose size, instead of being empirically configured as fixed, is adaptively computed from a pixel uncertainty estimated along with the flow map. Finally, attention is computed across two images within derived regions, referred to as attention span. By these means, we are able to not only maintain long-range dependencies, but also enable fine-grained attention among pixels of high relevance that compensates essential locality and piece-wise smoothness in matching tasks. State-of-the-art accuracy on a wide range of evaluation benchmarks validates the strong matching capability of our method.
ScaleNet: A Shallow Architecture for Scale Estimation
Dec 23, 2021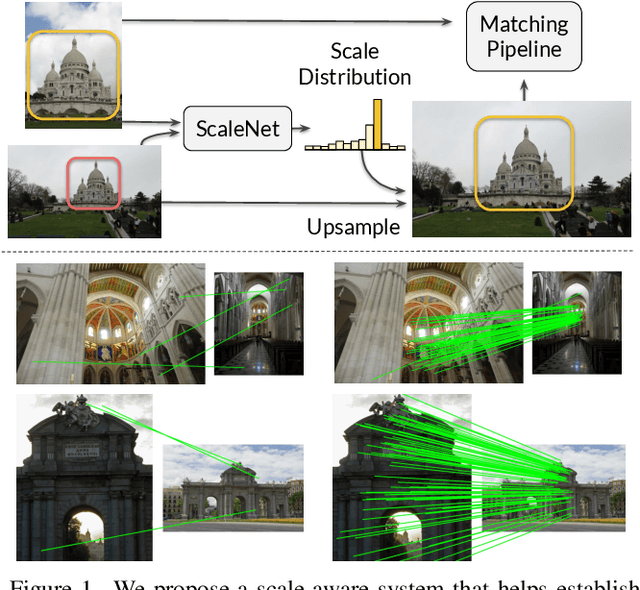

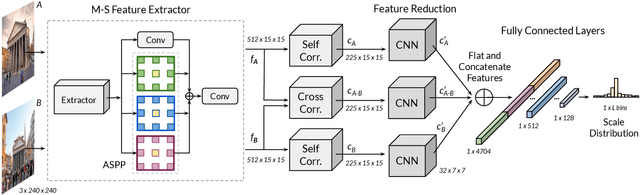

In this paper, we address the problem of estimating scale factors between images. We formulate the scale estimation problem as a prediction of a probability distribution over scale factors. We design a new architecture, ScaleNet, that exploits dilated convolutions as well as self and cross-correlation layers to predict the scale between images. We demonstrate that rectifying images with estimated scales leads to significant performance improvements for various tasks and methods. Specifically, we show how ScaleNet can be combined with sparse local features and dense correspondence networks to improve camera pose estimation, 3D reconstruction, or dense geometric matching in different benchmarks and datasets. We provide an extensive evaluation on several tasks and analyze the computational overhead of ScaleNet. The code, evaluation protocols, and trained models are publicly available at https://github.com/axelBarroso/ScaleNet.
Grasp-Oriented Fine-grained Cloth Segmentation without Real Supervision
Oct 06, 2021


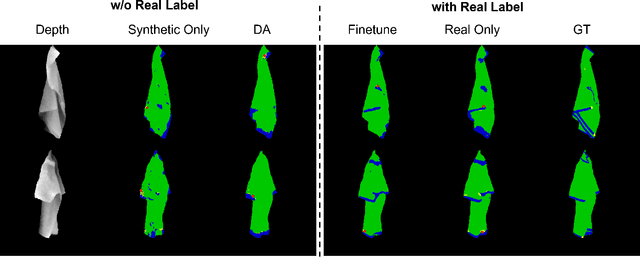
Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.
HyNet: Local Descriptor with Hybrid Similarity Measure and Triplet Loss
Jun 17, 2020
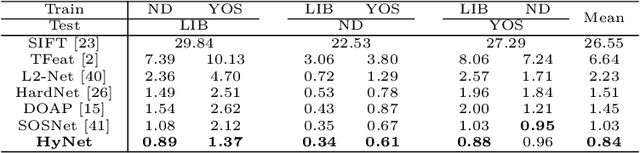
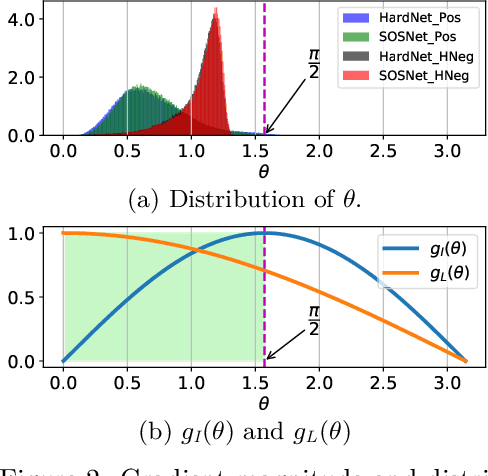

Recent works show that local descriptor learning benefits from the use of L2 normalisation, however, an in-depth analysis of this effect lacks in the literature. In this paper, we investigate how L2 normalisation affects the back-propagated descriptor gradients during training. Based on our observations, we propose HyNet, a new local descriptor that leads to state-of-the-art results in matching. HyNet introduces a hybrid similarity measure for triplet margin loss, a regularisation term constraining the descriptor norm, and a new network architecture that performs L2 normalisation of all intermediate feature maps and the output descriptors. HyNet surpasses previous methods by a significant margin on standard benchmarks that include patch matching, verification, and retrieval, as well as outperforming full end-to-end methods on 3D reconstruction tasks.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020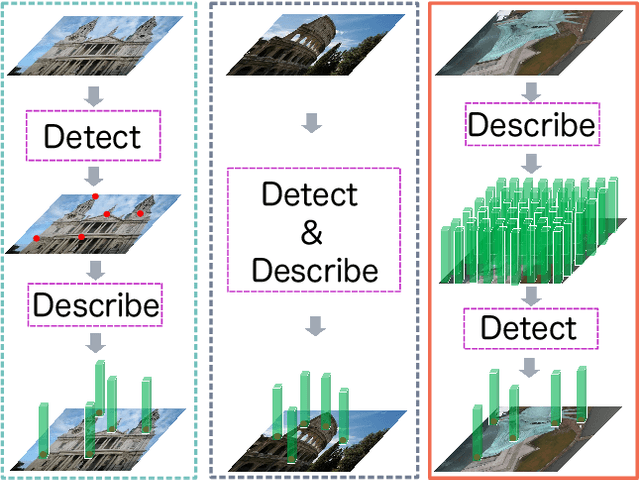
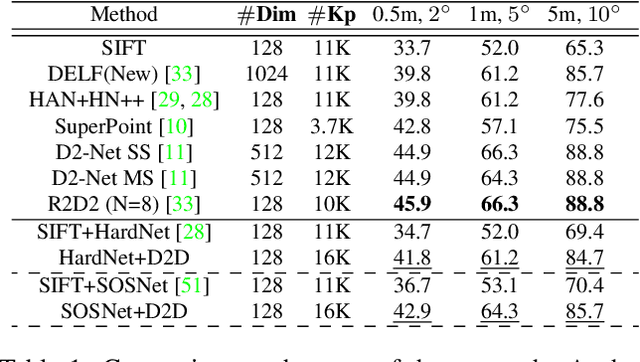
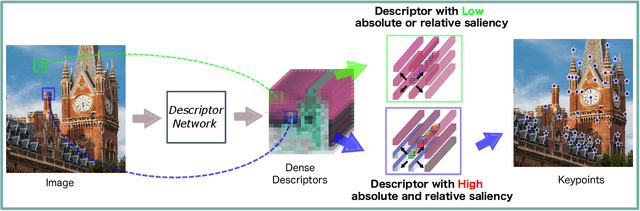
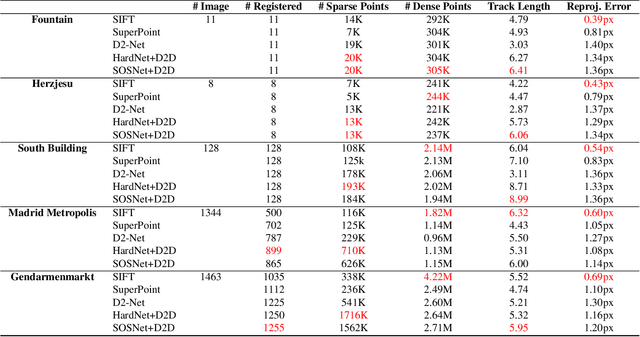
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.
SOLAR: Second-Order Loss and Attention for Image Retrieval
Feb 09, 2020
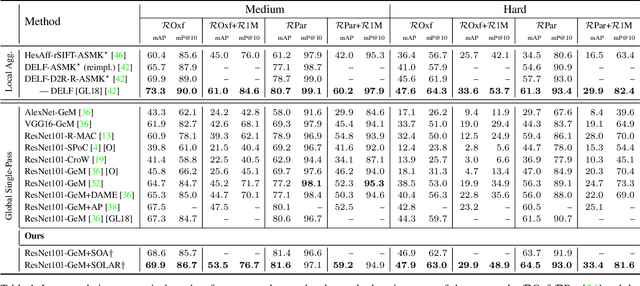
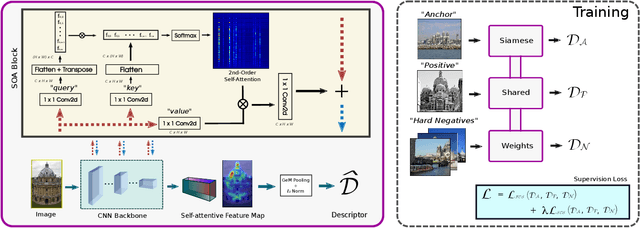

Recent works in deep-learning have shown that utilising second-order information is beneficial in many computer-vision related tasks. Second-order information can be enforced both in the spatial context and the abstract feature dimensions. In this work we explore two second order components. One is focused on second-order spatial information to increase the performance of image descriptors, both local and global. More specifically, it is used to re-weight feature maps, and thus emphasise salient image locations that are subsequently used for description. The second component is concerned with a second-order similarity (SOS) loss, that we extend to global descriptors for image retrieval, and is used to enhance the triplet loss with hard negative mining. We validate our approach on two different tasks and three datasets for image retrieval and patch matching. The results show that our second order components bring significant performance improvements in both tasks and lead to state of the art results across the benchmarks.
SOSNet: Second Order Similarity Regularization for Local Descriptor Learning
Apr 10, 2019

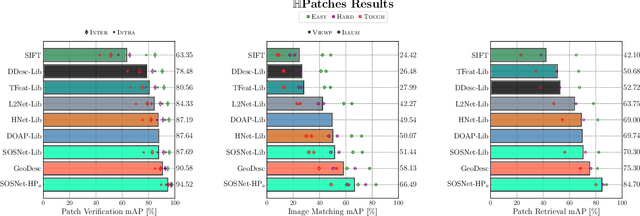
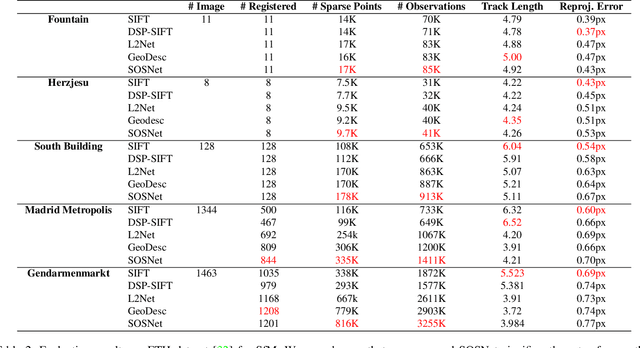
Despite the fact that Second Order Similarity (SOS) has been used with significant success in tasks such as graph matching and clustering, it has not been exploited for learning local descriptors. In this work, we explore the potential of SOS in the field of descriptor learning by building upon the intuition that a positive pair of matching points should exhibit similar distances with respect to other points in the embedding space. Thus, we propose a novel regularization term, named Second Order Similarity Regularization (SOSR), that follows this principle. By incorporating SOSR into training, our learned descriptor achieves state-of-the-art performance on several challenging benchmarks containing distinct tasks ranging from local patch retrieval to structure from motion. Furthermore, by designing a von Mises-Fischer distribution based evaluation method, we link the utilization of the descriptor space to the matching performance, thus demonstrating the effectiveness of our proposed SOSR. Extensive experimental results, empirical evidence, and in-depth analysis are provided, indicating that SOSR can significantly boost the matching performance of the learned descriptor.