 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Autonomous Vehicle Training with Language Model Integration and Critical Scenario Generation
Apr 12, 2024This paper introduces CRITICAL, a novel closed-loop framework for autonomous vehicle (AV) training and testing. CRITICAL stands out for its ability to generate diverse scenarios, focusing on critical driving situations that target specific learning and performance gaps identified in the Reinforcement Learning (RL) agent. The framework achieves this by integrating real-world traffic dynamics, driving behavior analysis, surrogate safety measures, and an optional Large Language Model (LLM) component. It is proven that the establishment of a closed feedback loop between the data generation pipeline and the training process can enhance the learning rate during training, elevate overall system performance, and augment safety resilience. Our evaluations, conducted using the Proximal Policy Optimization (PPO) and the HighwayEnv simulation environment, demonstrate noticeable performance improvements with the integration of critical case generation and LLM analysis, indicating CRITICAL's potential to improve the robustness of AV systems and streamline the generation of critical scenarios. This ultimately serves to hasten the development of AV agents, expand the general scope of RL training, and ameliorate validation efforts for AV safety.
Self-Supervised RGB-T Tracking with Cross-Input Consistency
Jan 26, 2023



In this paper, we propose a self-supervised RGB-T tracking method. Different from existing deep RGB-T trackers that use a large number of annotated RGB-T image pairs for training, our RGB-T tracker is trained using unlabeled RGB-T video pairs in a self-supervised manner. We propose a novel cross-input consistency-based self-supervised training strategy based on the idea that tracking can be performed using different inputs. Specifically, we construct two distinct inputs using unlabeled RGB-T video pairs. We then track objects using these two inputs to generate results, based on which we construct our cross-input consistency loss. Meanwhile, we propose a reweighting strategy to make our loss function robust to low-quality training samples. We build our tracker on a Siamese correlation filter network. To the best of our knowledge, our tracker is the first self-supervised RGB-T tracker. Extensive experiments on two public RGB-T tracking benchmarks demonstrate that the proposed training strategy is effective. Remarkably, despite training only with a corpus of unlabeled RGB-T video pairs, our tracker outperforms seven supervised RGB-T trackers on the GTOT dataset.
Hearables: Ear EEG Based Driver Fatigue Detection
Jan 16, 2023Ear EEG based driver fatigue monitoring systems have the potential to provide a seamless, efficient, and feasibly deployable alternative to existing scalp EEG based systems, which are often cumbersome and impractical. However, the feasibility of detecting the relevant delta, theta, alpha, and beta band EEG activity through the ear EEG is yet to be investigated. Through measurements of scalp and ear EEG on ten subjects during a simulated, monotonous driving experiment, this study provides statistical analysis of characteristic ear EEG changes that are associated with the transition from alert to mentally fatigued states, and subsequent testing of a machine learning based automatic fatigue detection model. Novel numerical evidence is provided to support the feasibility of detection of mental fatigue with ear EEG that is in agreement with widely reported scalp EEG findings. This study paves the way for the development of ultra-wearable and readily deployable hearables based driver fatigue monitoring systems.
On Specifying for Trustworthiness
Jun 22, 2022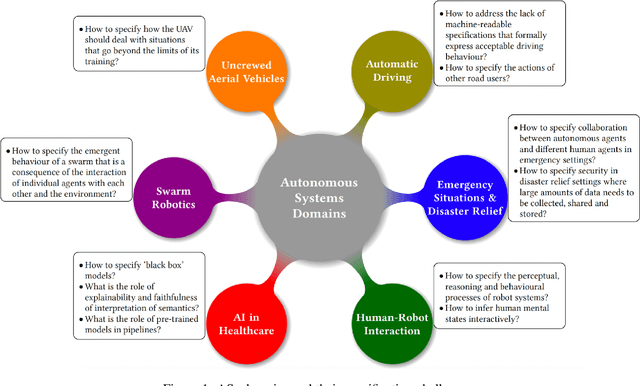
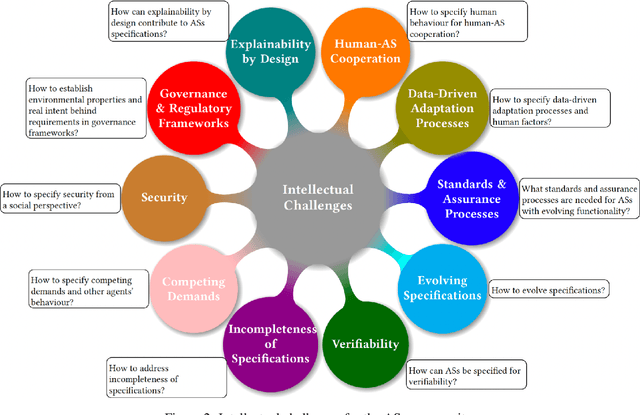
As autonomous systems are becoming part of our daily lives, ensuring their trustworthiness is crucial. There are a number of techniques for demonstrating trustworthiness. Common to all these techniques is the need to articulate specifications. In this paper, we take a broad view of specification, concentrating on top-level requirements including but not limited to functionality, safety, security and other non-functional properties. The main contribution of this article is a set of high-level intellectual challenges for the autonomous systems community related to specifying for trustworthiness. We also describe unique specification challenges concerning a number of application domains for autonomous systems.
Transferring Multi-Agent Reinforcement Learning Policies for Autonomous Driving using Sim-to-Real
Mar 22, 2022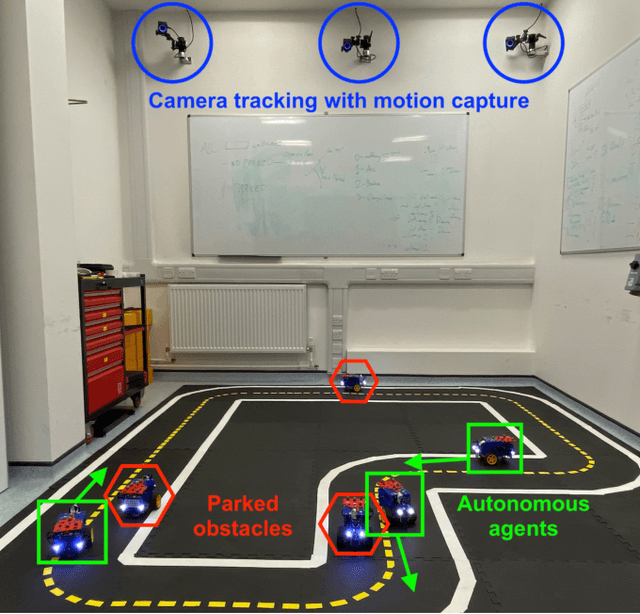
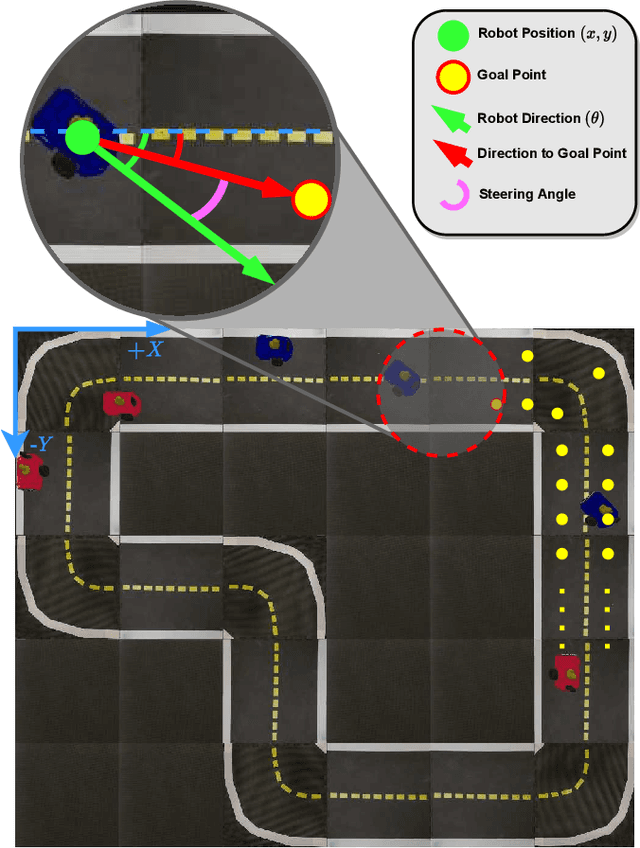
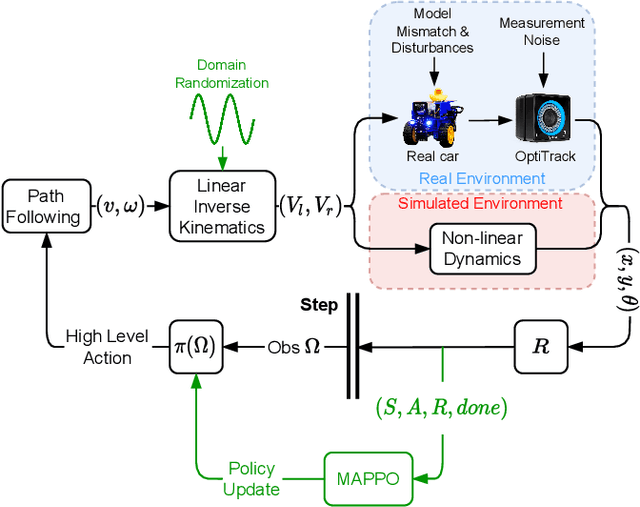
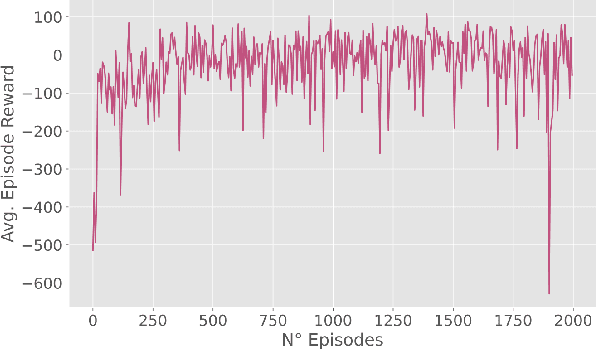
Autonomous Driving requires high levels of coordination and collaboration between agents. Achieving effective coordination in multi-agent systems is a difficult task that remains largely unresolved. Multi-Agent Reinforcement Learning has arisen as a powerful method to accomplish this task because it considers the interaction between agents and also allows for decentralized training -- which makes it highly scalable. However, transferring policies from simulation to the real world is a big challenge, even for single-agent applications. Multi-agent systems add additional complexities to the Sim-to-Real gap due to agent collaboration and environment synchronization. In this paper, we propose a method to transfer multi-agent autonomous driving policies to the real world. For this, we create a multi-agent environment that imitates the dynamics of the Duckietown multi-robot testbed, and train multi-agent policies using the MAPPO algorithm with different levels of domain randomization. We then transfer the trained policies to the Duckietown testbed and compare the use of the MAPPO algorithm against a traditional rule-based method. We show that the rewards of the transferred policies with MAPPO and domain randomization are, on average, 1.85 times superior to the rule-based method. Moreover, we show that different levels of parameter randomization have a substantial impact on the Sim-to-Real gap.
Grasp-Oriented Fine-grained Cloth Segmentation without Real Supervision
Oct 06, 2021


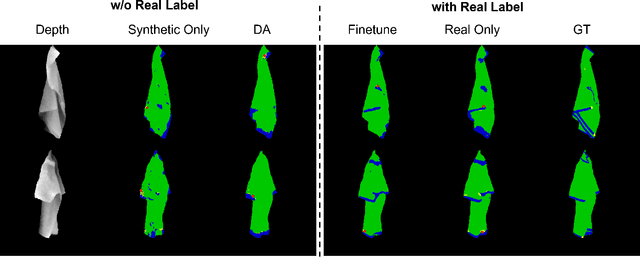
Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.
Continuous Non-Invasive Eye Tracking In Intensive Care
Jul 23, 2021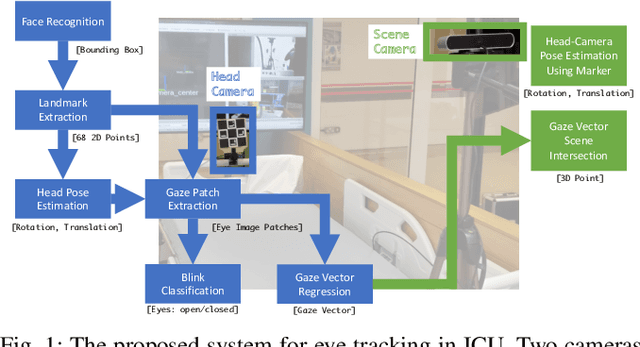

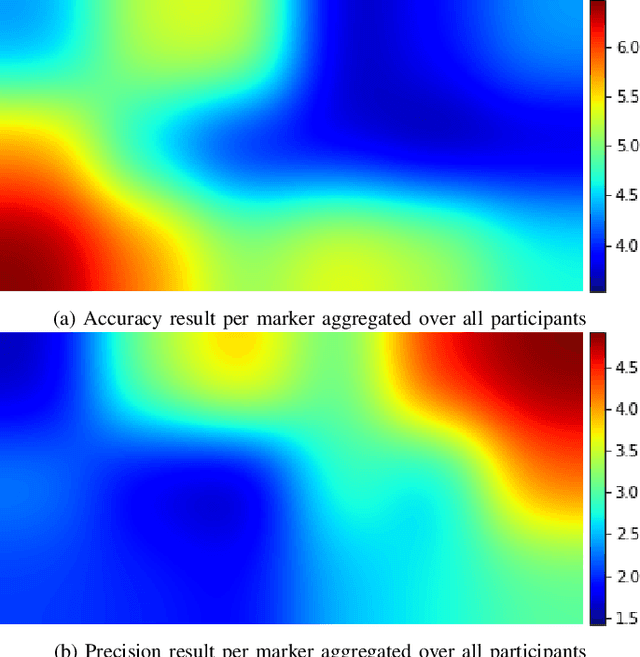
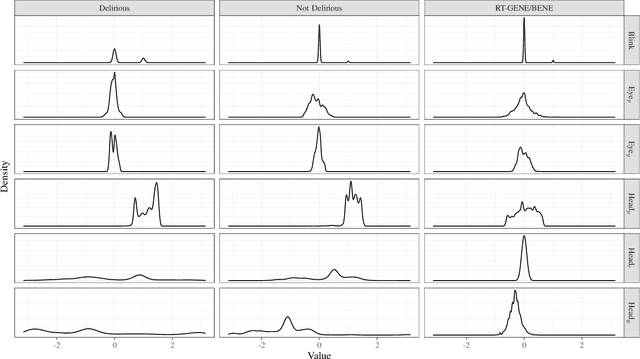
Delirium, an acute confusional state, is a common occurrence in Intensive Care Units (ICUs). Patients who develop delirium have globally worse outcomes than those who do not and thus the diagnosis of delirium is of importance. Current diagnostic methods have several limitations leading to the suggestion of eye-tracking for its diagnosis through in-attention. To ascertain the requirements for an eye-tracking system in an adult ICU, measurements were carried out at Chelsea & Westminster Hospital NHS Foundation Trust. Clinical criteria guided empirical requirements of invasiveness and calibration methods while accuracy and precision were measured. A non-invasive system was then developed utilising a patient-facing RGB-camera and a scene-facing RGBD-camera. The system's performance was measured in a replicated laboratory environment with healthy volunteers revealing an accuracy and precision that outperforms what is required while simultaneously being non-invasive and calibration-free The system was then deployed as part CONfuSED, a clinical feasibility study where we report aggregated data from 5 patients as well as the acceptability of the system to bedside nursing staff. The system is the first eye-tracking system to be deployed in an ICU.
Quantitative Risk Indices for Autonomous Vehicle Training Systems
Apr 27, 2021The development of Autonomous Vehicles (AV) presents an opportunity to save and improve lives. However, achieving SAE Level 5 (full) autonomy will require overcoming many technical challenges. There is a gap in the literature regarding the measurement of safety for self-driving systems. Measuring safety and risk is paramount for the generation of useful simulation scenarios for training and validation of autonomous systems. The limitation of current approaches is the dependence on near-crash data. Although near-miss data can substantially increase scarce available accident data, the definition of a near-miss or near-crash is arbitrary. A promising alternative is the introduction of the Responsibility-Sensitive Safety (RSS) model by Shalev-Shwartz et al., which defines safe lateral and longitudinal distances that can guarantee impossibility of collision under reasonable assumptions for vehicle dynamics. We present a framework that extends the RSS model for cases when reasonable assumptions or safe distances are violated. The proposed framework introduces risk indices that quantify the likelihood of a collision by using vehicle dynamics and driver's risk aversion. The present study concludes with proposed experiments for tuning the parameters of the formulated risk indices.
Disentangled Sequence Clustering for Human Intention Inference
Jan 23, 2021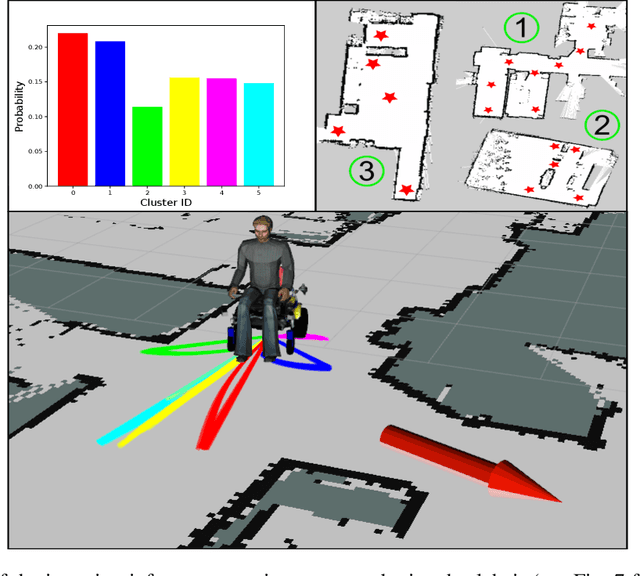
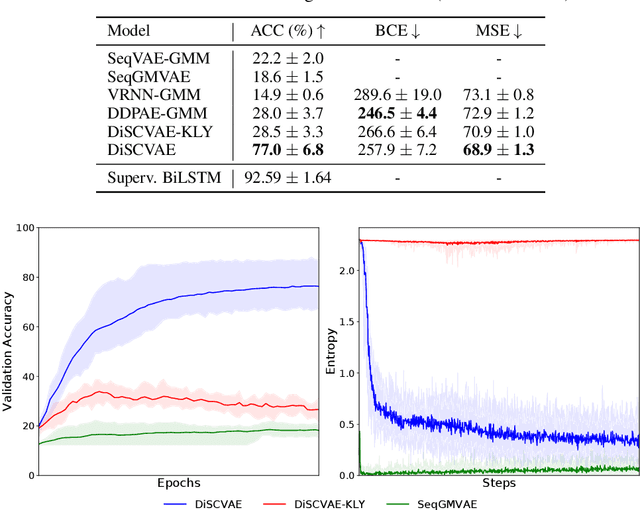

Equipping robots with the ability to infer human intent is a vital precondition for effective collaboration. Most computational approaches towards this objective employ probabilistic reasoning to recover a distribution of "intent" conditioned on the robot's perceived sensory state. However, these approaches typically assume task-specific notions of human intent (e.g. labelled goals) are known a priori. To overcome this constraint, we propose the Disentangled Sequence Clustering Variational Autoencoder (DiSCVAE), a clustering framework that can be used to learn such a distribution of intent in an unsupervised manner. The DiSCVAE leverages recent advances in unsupervised learning to derive a disentangled latent representation of sequential data, separating time-varying local features from time-invariant global aspects. Though unlike previous frameworks for disentanglement, the proposed variant also infers a discrete variable to form a latent mixture model and enable clustering of global sequence concepts, e.g. intentions from observed human behaviour. To evaluate the DiSCVAE, we first validate its capacity to discover classes from unlabelled sequences using video datasets of bouncing digits and 2D animations. We then report results from a real-world human-robot interaction experiment conducted on a robotic wheelchair. Our findings glean insights into how the inferred discrete variable coincides with human intent and thus serves to improve assistance in collaborative settings, such as shared control.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020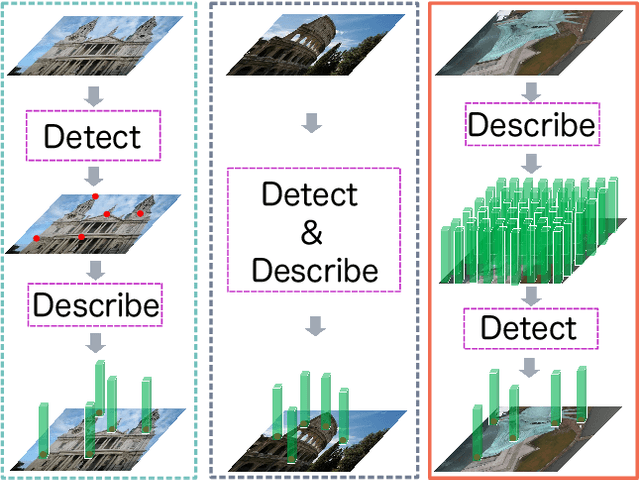
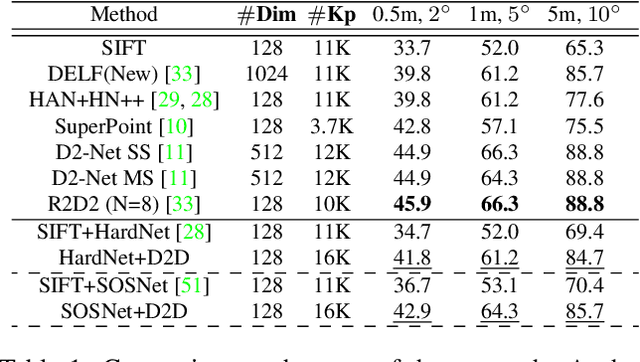
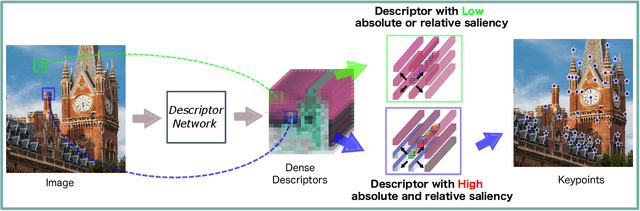
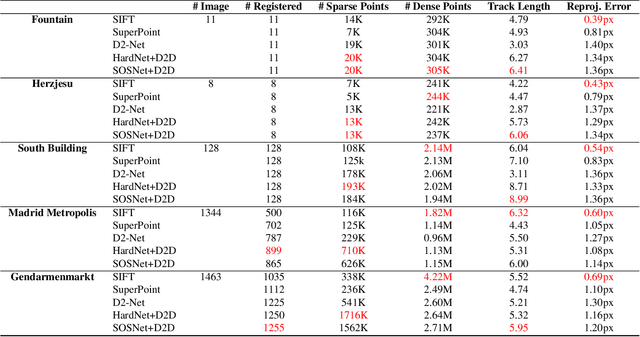
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.