 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Collaborative Learning Approach for Connected Autonomous Vehicles in Occluded Scenarios
Dec 11, 2024



Collaborative navigation becomes essential in situations of occluded scenarios in autonomous driving where independent driving policies are likely to lead to collisions. One promising approach to address this issue is through the use of Vehicle-to-Vehicle (V2V) networks that allow for the sharing of perception information with nearby agents, preventing catastrophic accidents. In this article, we propose a collaborative control method based on a V2V network for sharing compressed LiDAR features and employing Proximal Policy Optimisation to train safe and efficient navigation policies. Unlike previous approaches that rely on expert data (behaviour cloning), our proposed approach learns the multi-agent policies directly from experience in the occluded environment, while effectively meeting bandwidth limitations. The proposed method first prepossesses LiDAR point cloud data to obtain meaningful features through a convolutional neural network and then shares them with nearby CAVs to alert for potentially dangerous situations. To evaluate the proposed method, we developed an occluded intersection gym environment based on the CARLA autonomous driving simulator, allowing real-time data sharing among agents. Our experimental results demonstrate the consistent superiority of our collaborative control method over an independent reinforcement learning method and a cooperative early fusion method.
Towards a Universal Evaluation Model for Careful and Competent Autonomous Driving
Jul 22, 2024Virtual scenario-based testing methods to validate autonomous driving systems are predominantly centred around collision avoidance, and lack a comprehensive approach to evaluate optimal driving behaviour holistically. Furthermore, current validation approaches do not align with authorisation and monitoring requirements put forth by regulatory bodies. We address these validation gaps by outlining a universal evaluation framework that: incorporates the notion of careful and competent driving, unifies behavioural competencies and evaluation criteria, and is amenable at a scenario-specific and aggregate behaviour level. This framework can be leveraged to evaluate optimal driving in scenario-based testing, and for post-deployment monitoring to ensure continual compliance with regulation and safety standards.
Enhancing Autonomous Vehicle Training with Language Model Integration and Critical Scenario Generation
Apr 12, 2024



This paper introduces CRITICAL, a novel closed-loop framework for autonomous vehicle (AV) training and testing. CRITICAL stands out for its ability to generate diverse scenarios, focusing on critical driving situations that target specific learning and performance gaps identified in the Reinforcement Learning (RL) agent. The framework achieves this by integrating real-world traffic dynamics, driving behavior analysis, surrogate safety measures, and an optional Large Language Model (LLM) component. It is proven that the establishment of a closed feedback loop between the data generation pipeline and the training process can enhance the learning rate during training, elevate overall system performance, and augment safety resilience. Our evaluations, conducted using the Proximal Policy Optimization (PPO) and the HighwayEnv simulation environment, demonstrate noticeable performance improvements with the integration of critical case generation and LLM analysis, indicating CRITICAL's potential to improve the robustness of AV systems and streamline the generation of critical scenarios. This ultimately serves to hasten the development of AV agents, expand the general scope of RL training, and ameliorate validation efforts for AV safety.
Adaptive Road Configurations for Improved Autonomous Vehicle-Pedestrian Interactions using Reinforcement Learning
Mar 22, 2023
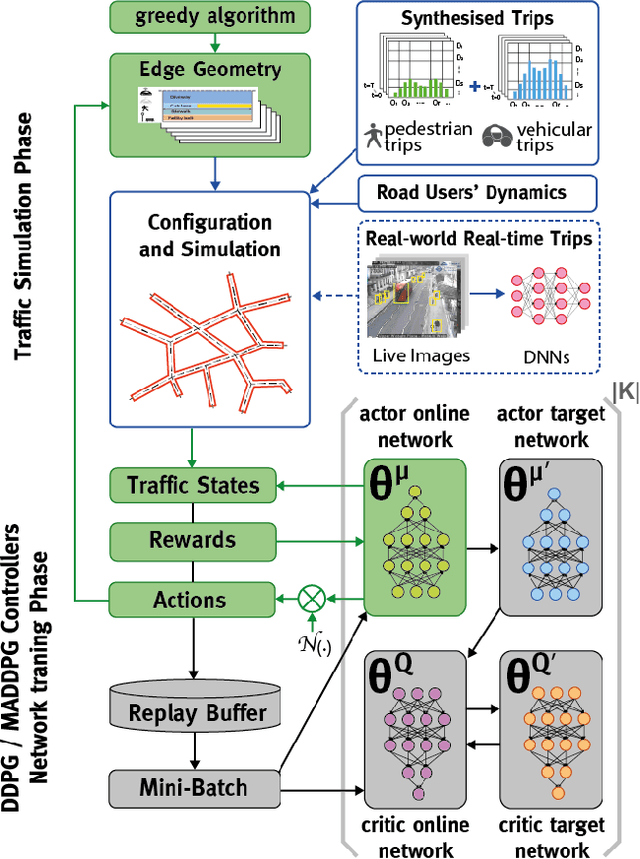


The deployment of Autonomous Vehicles (AVs) poses considerable challenges and unique opportunities for the design and management of future urban road infrastructure. In light of this disruptive transformation, the Right-Of-Way (ROW) composition of road space has the potential to be renewed. Design approaches and intelligent control models have been proposed to address this problem, but we lack an operational framework that can dynamically generate ROW plans for AVs and pedestrians in response to real-time demand. Based on microscopic traffic simulation, this study explores Reinforcement Learning (RL) methods for evolving ROW compositions. We implement a centralised paradigm and a distributive learning paradigm to separately perform the dynamic control on several road network configurations. Experimental results indicate that the algorithms have the potential to improve traffic flow efficiency and allocate more space for pedestrians. Furthermore, the distributive learning algorithm outperforms its centralised counterpart regarding computational cost (49.55\%), benchmark rewards (25.35\%), best cumulative rewards (24.58\%), optimal actions (13.49\%) and rate of convergence. This novel road management technique could potentially contribute to the flow-adaptive and active mobility-friendly streets in the AVs era.
* 11 pages, 7 figures, Copyright \c{opyright} 2023, IEEE
Safe and Efficient Manoeuvring for Emergency Vehicles in Autonomous Traffic using Multi-Agent Proximal Policy Optimisation
Oct 31, 2022Manoeuvring in the presence of emergency vehicles is still a major issue for vehicle autonomy systems. Most studies that address this topic are based on rule-based methods, which cannot cover all possible scenarios that can take place in autonomous traffic. Multi-Agent Proximal Policy Optimisation (MAPPO) has recently emerged as a powerful method for autonomous systems because it allows for training in thousands of different situations. In this study, we present an approach based on MAPPO to guarantee the safe and efficient manoeuvring of autonomous vehicles in the presence of an emergency vehicle. We introduce a risk metric that summarises the potential risk of collision in a single index. The proposed method generates cooperative policies allowing the emergency vehicle to go at $15 \%$ higher average speed while maintaining high safety distances. Moreover, we explore the trade-off between safety and traffic efficiency and assess the performance in a competitive scenario.
Location-Routing Planning for Last-Mile Deliveries Using Mobile Parcel Lockers: A Hybrid Q-Learning Network Approach
Sep 09, 2022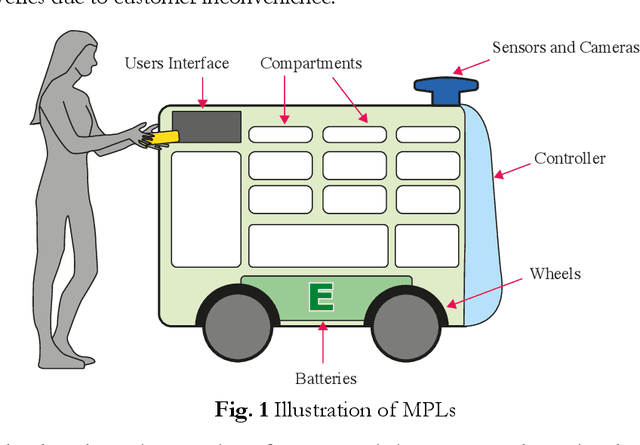

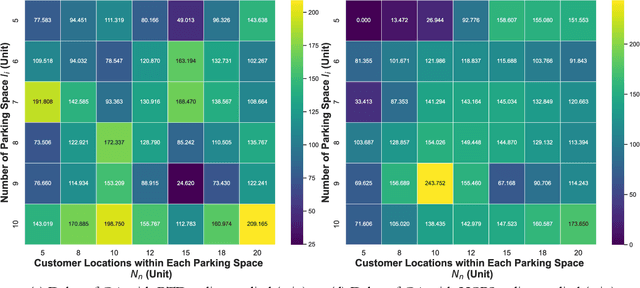
Mobile parcel lockers (MPLs) have been recently proposed by logistics operators as a technology that could help reduce traffic congestion and operational costs in urban freight distribution. Given their ability to relocate throughout their area of deployment, they hold the potential to improve customer accessibility and convenience. In this study, we formulate the Mobile Parcel Locker Problem (MPLP), a special case of the Location-Routing Problem (LRP) which determines the optimal stopover location for MPLs throughout the day and plans corresponding delivery routes. A Hybrid Q-Learning-Network-based Method (HQM) is developed to resolve the computational complexity of the resulting large problem instances while escaping local optima. In addition, the HQM is integrated with global and local search mechanisms to resolve the dilemma of exploration and exploitation faced by classic reinforcement learning (RL) methods. We examine the performance of HQM under different problem sizes (up to 200 nodes) and benchmarked it against the Genetic Algorithm (GA). Our results indicate that the average reward obtained by HQM is 1.96 times greater than GA, which demonstrates that HQM has a better optimisation ability. Finally, we identify critical factors that contribute to fleet size requirements, travel distances, and service delays. Our findings outline that the efficiency of MPLs is mainly contingent on the length of time windows and the deployment of MPL stopovers.
Transferring Multi-Agent Reinforcement Learning Policies for Autonomous Driving using Sim-to-Real
Mar 22, 2022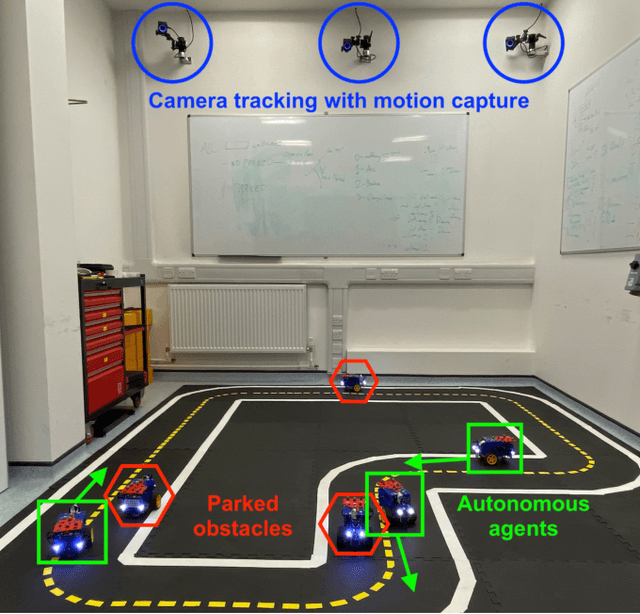
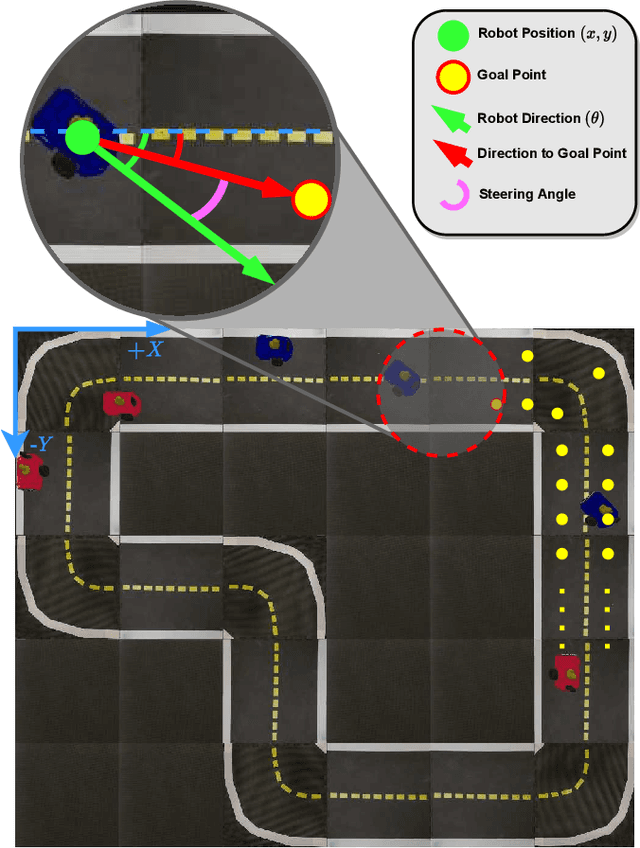
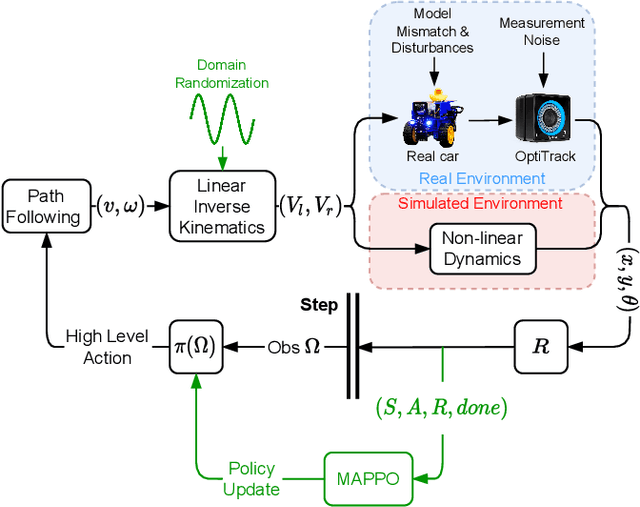
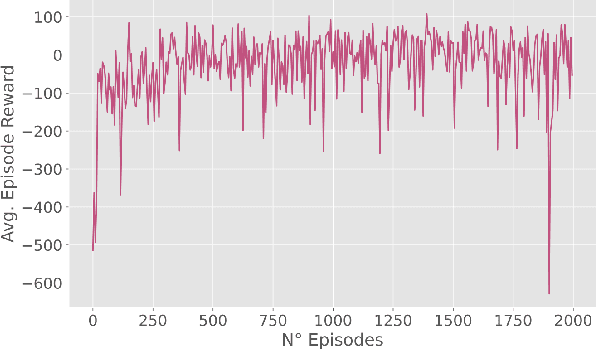
Autonomous Driving requires high levels of coordination and collaboration between agents. Achieving effective coordination in multi-agent systems is a difficult task that remains largely unresolved. Multi-Agent Reinforcement Learning has arisen as a powerful method to accomplish this task because it considers the interaction between agents and also allows for decentralized training -- which makes it highly scalable. However, transferring policies from simulation to the real world is a big challenge, even for single-agent applications. Multi-agent systems add additional complexities to the Sim-to-Real gap due to agent collaboration and environment synchronization. In this paper, we propose a method to transfer multi-agent autonomous driving policies to the real world. For this, we create a multi-agent environment that imitates the dynamics of the Duckietown multi-robot testbed, and train multi-agent policies using the MAPPO algorithm with different levels of domain randomization. We then transfer the trained policies to the Duckietown testbed and compare the use of the MAPPO algorithm against a traditional rule-based method. We show that the rewards of the transferred policies with MAPPO and domain randomization are, on average, 1.85 times superior to the rule-based method. Moreover, we show that different levels of parameter randomization have a substantial impact on the Sim-to-Real gap.
A Reinforcement Learning-based Adaptive Control Model for Future Street Planning, An Algorithm and A Case Study
Dec 10, 2021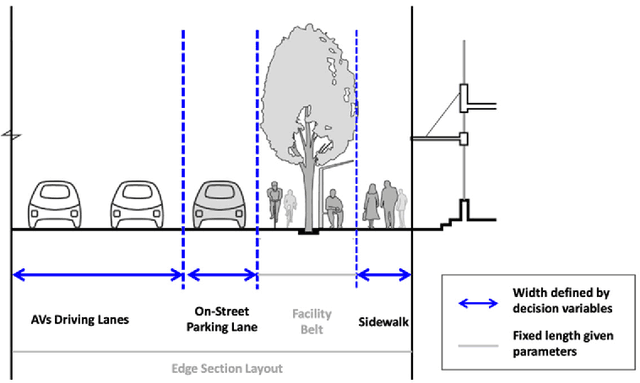

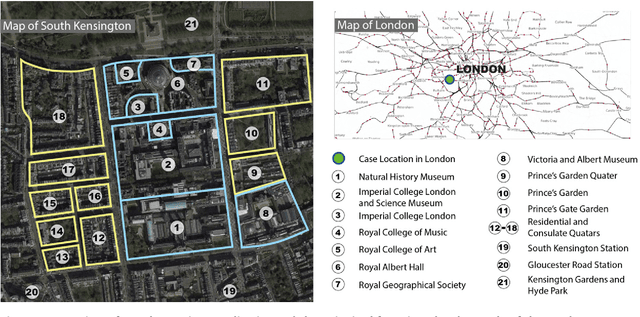
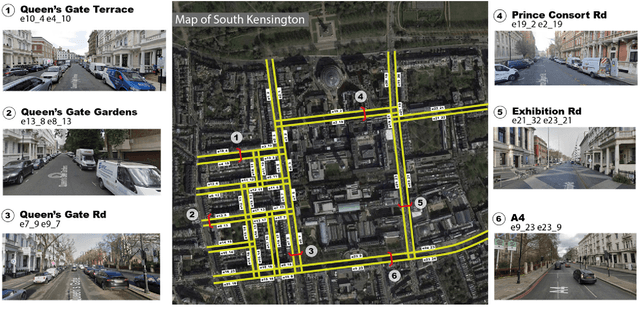
With the emerging technologies in Intelligent Transportation System (ITS), the adaptive operation of road space is likely to be realised within decades. An intelligent street can learn and improve its decision-making on the right-of-way (ROW) for road users, liberating more active pedestrian space while maintaining traffic safety and efficiency. However, there is a lack of effective controlling techniques for these adaptive street infrastructures. To fill this gap in existing studies, we formulate this control problem as a Markov Game and develop a solution based on the multi-agent Deep Deterministic Policy Gradient (MADDPG) algorithm. The proposed model can dynamically assign ROW for sidewalks, autonomous vehicles (AVs) driving lanes and on-street parking areas in real-time. Integrated with the SUMO traffic simulator, this model was evaluated using the road network of the South Kensington District against three cases of divergent traffic conditions: pedestrian flow rates, AVs traffic flow rates and parking demands. Results reveal that our model can achieve an average reduction of 3.87% and 6.26% in street space assigned for on-street parking and vehicular operations. Combined with space gained by limiting the number of driving lanes, the average proportion of sidewalks to total widths of streets can significantly increase by 10.13%.
Location-routing Optimisation for Urban Logistics Using Mobile Parcel Locker Based on Hybrid Q-Learning Algorithm
Oct 29, 2021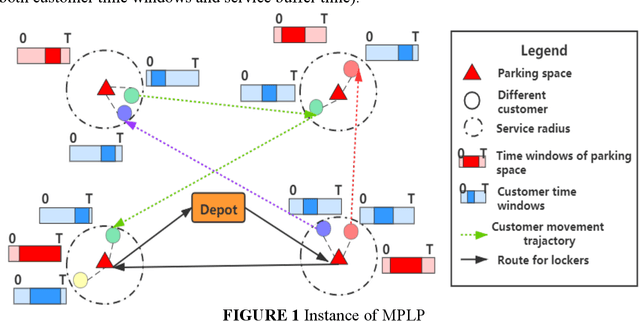
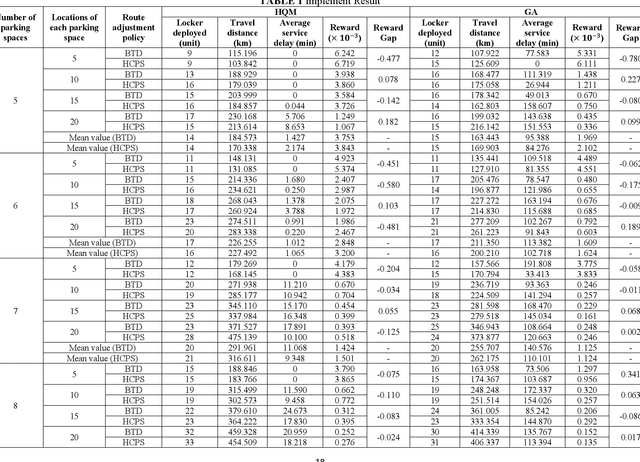
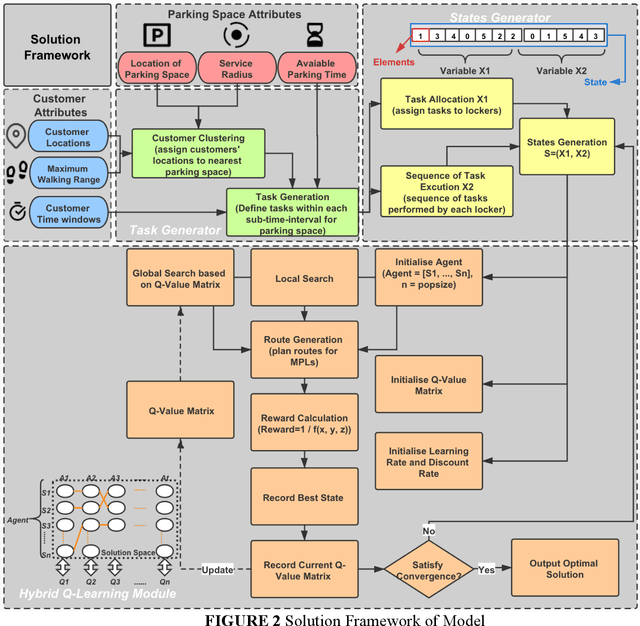
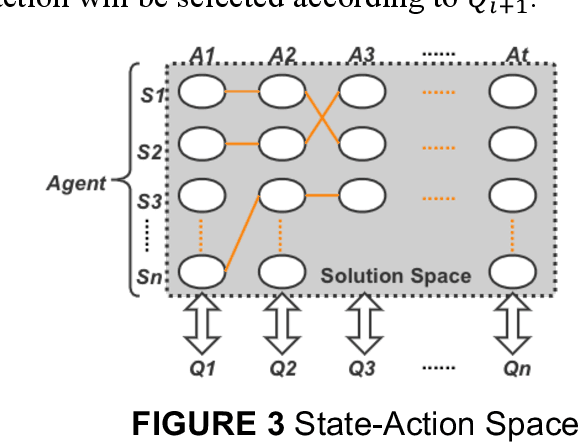
Mobile parcel lockers (MPLs) have been recently introduced by urban logistics operators as a means to reduce traffic congestion and operational cost. Their capability to relocate their position during the day has the potential to improve customer accessibility and convenience (if deployed and planned accordingly), allowing customers to collect parcels at their preferred time among one of the multiple locations. This paper proposes an integer programming model to solve the Location Routing Problem for MPLs to determine the optimal configuration and locker routes. In solving this model, a Hybrid Q-Learning algorithm-based Method (HQM) integrated with global and local search mechanisms is developed, the performance of which is examined for different problem sizes and benchmarked with genetic algorithms. Furthermore, we introduced two route adjustment strategies to resolve stochastic events that may cause delays. The results show that HQM achieves 443.41% improvement on average in solution improvement, compared with the 94.91% improvement of heuristic counterparts, suggesting HQM enables a more efficient search for better solutions. Finally, we identify critical factors that contribute to service delays and investigate their effects.
Quantitative Risk Indices for Autonomous Vehicle Training Systems
Apr 27, 2021The development of Autonomous Vehicles (AV) presents an opportunity to save and improve lives. However, achieving SAE Level 5 (full) autonomy will require overcoming many technical challenges. There is a gap in the literature regarding the measurement of safety for self-driving systems. Measuring safety and risk is paramount for the generation of useful simulation scenarios for training and validation of autonomous systems. The limitation of current approaches is the dependence on near-crash data. Although near-miss data can substantially increase scarce available accident data, the definition of a near-miss or near-crash is arbitrary. A promising alternative is the introduction of the Responsibility-Sensitive Safety (RSS) model by Shalev-Shwartz et al., which defines safe lateral and longitudinal distances that can guarantee impossibility of collision under reasonable assumptions for vehicle dynamics. We present a framework that extends the RSS model for cases when reasonable assumptions or safe distances are violated. The proposed framework introduces risk indices that quantify the likelihood of a collision by using vehicle dynamics and driver's risk aversion. The present study concludes with proposed experiments for tuning the parameters of the formulated risk indices.