 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Collaborative Learning Approach for Connected Autonomous Vehicles in Occluded Scenarios
Dec 11, 2024



Collaborative navigation becomes essential in situations of occluded scenarios in autonomous driving where independent driving policies are likely to lead to collisions. One promising approach to address this issue is through the use of Vehicle-to-Vehicle (V2V) networks that allow for the sharing of perception information with nearby agents, preventing catastrophic accidents. In this article, we propose a collaborative control method based on a V2V network for sharing compressed LiDAR features and employing Proximal Policy Optimisation to train safe and efficient navigation policies. Unlike previous approaches that rely on expert data (behaviour cloning), our proposed approach learns the multi-agent policies directly from experience in the occluded environment, while effectively meeting bandwidth limitations. The proposed method first prepossesses LiDAR point cloud data to obtain meaningful features through a convolutional neural network and then shares them with nearby CAVs to alert for potentially dangerous situations. To evaluate the proposed method, we developed an occluded intersection gym environment based on the CARLA autonomous driving simulator, allowing real-time data sharing among agents. Our experimental results demonstrate the consistent superiority of our collaborative control method over an independent reinforcement learning method and a cooperative early fusion method.
Safe and Efficient Manoeuvring for Emergency Vehicles in Autonomous Traffic using Multi-Agent Proximal Policy Optimisation
Oct 31, 2022Manoeuvring in the presence of emergency vehicles is still a major issue for vehicle autonomy systems. Most studies that address this topic are based on rule-based methods, which cannot cover all possible scenarios that can take place in autonomous traffic. Multi-Agent Proximal Policy Optimisation (MAPPO) has recently emerged as a powerful method for autonomous systems because it allows for training in thousands of different situations. In this study, we present an approach based on MAPPO to guarantee the safe and efficient manoeuvring of autonomous vehicles in the presence of an emergency vehicle. We introduce a risk metric that summarises the potential risk of collision in a single index. The proposed method generates cooperative policies allowing the emergency vehicle to go at $15 \%$ higher average speed while maintaining high safety distances. Moreover, we explore the trade-off between safety and traffic efficiency and assess the performance in a competitive scenario.
Transferring Multi-Agent Reinforcement Learning Policies for Autonomous Driving using Sim-to-Real
Mar 22, 2022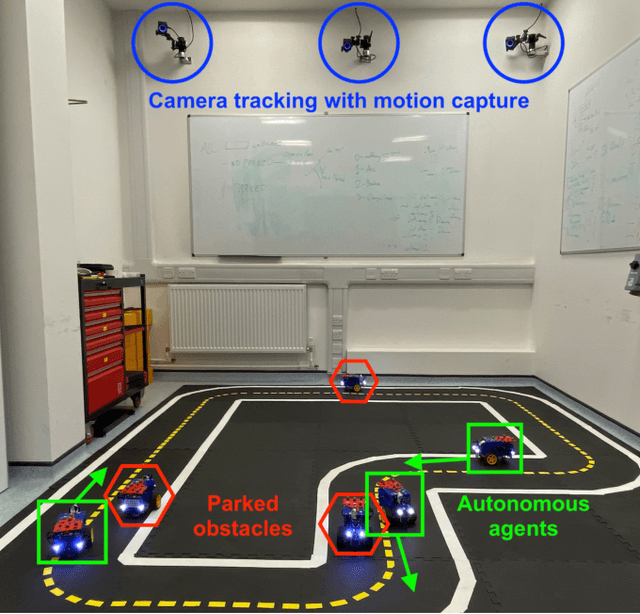
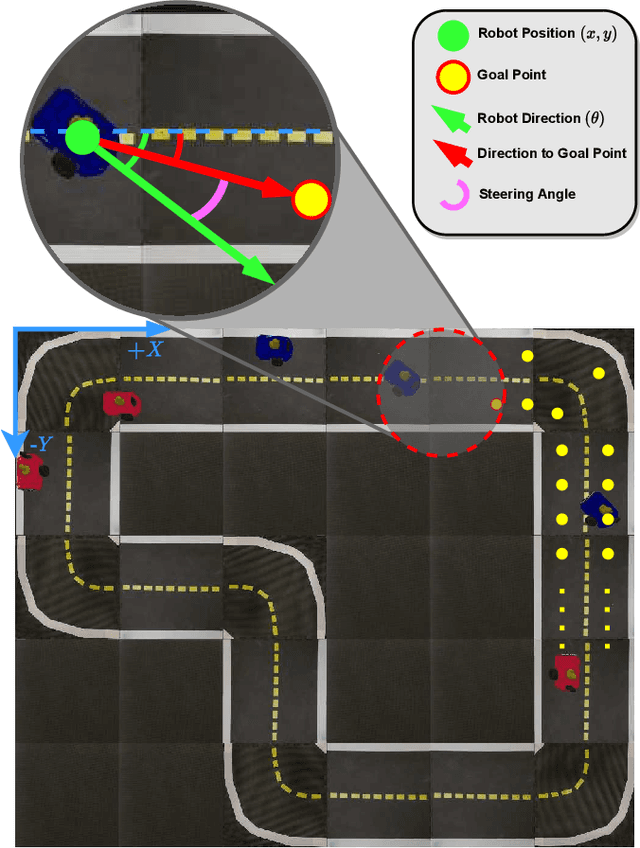
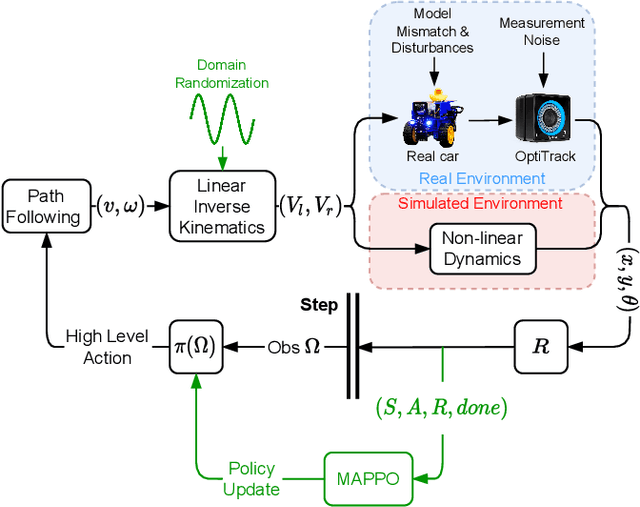
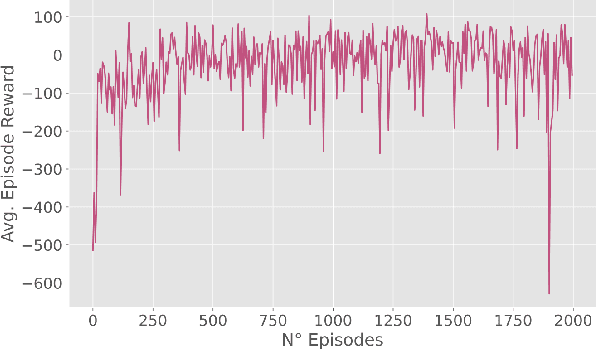
Autonomous Driving requires high levels of coordination and collaboration between agents. Achieving effective coordination in multi-agent systems is a difficult task that remains largely unresolved. Multi-Agent Reinforcement Learning has arisen as a powerful method to accomplish this task because it considers the interaction between agents and also allows for decentralized training -- which makes it highly scalable. However, transferring policies from simulation to the real world is a big challenge, even for single-agent applications. Multi-agent systems add additional complexities to the Sim-to-Real gap due to agent collaboration and environment synchronization. In this paper, we propose a method to transfer multi-agent autonomous driving policies to the real world. For this, we create a multi-agent environment that imitates the dynamics of the Duckietown multi-robot testbed, and train multi-agent policies using the MAPPO algorithm with different levels of domain randomization. We then transfer the trained policies to the Duckietown testbed and compare the use of the MAPPO algorithm against a traditional rule-based method. We show that the rewards of the transferred policies with MAPPO and domain randomization are, on average, 1.85 times superior to the rule-based method. Moreover, we show that different levels of parameter randomization have a substantial impact on the Sim-to-Real gap.