 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Multi-Agent Reinforcement Learning Policies for Autonomous Driving using Sim-to-Real
Paper and Code
Mar 22, 2022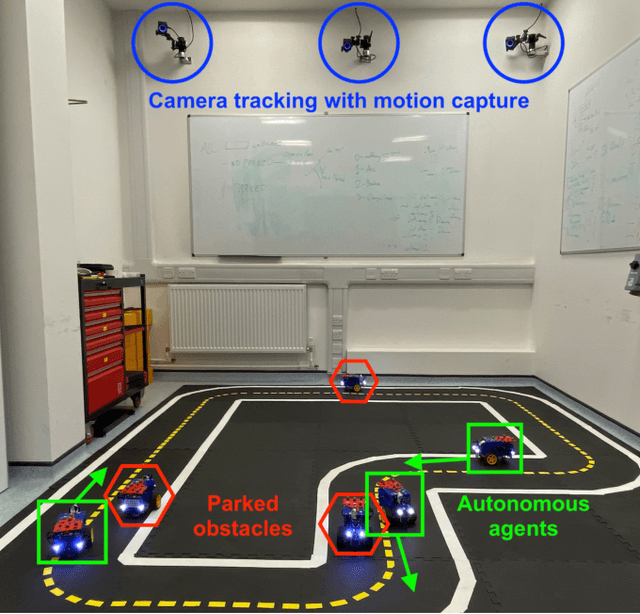
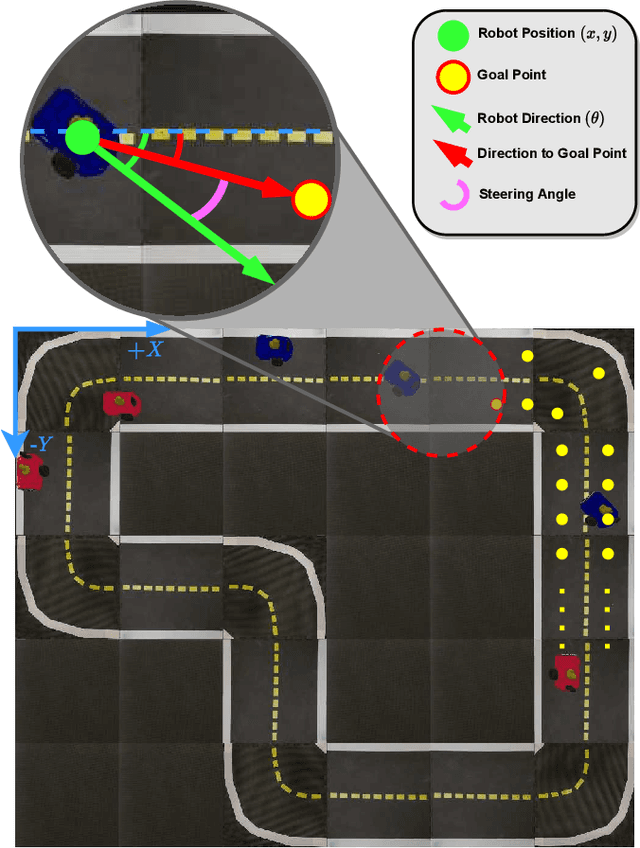
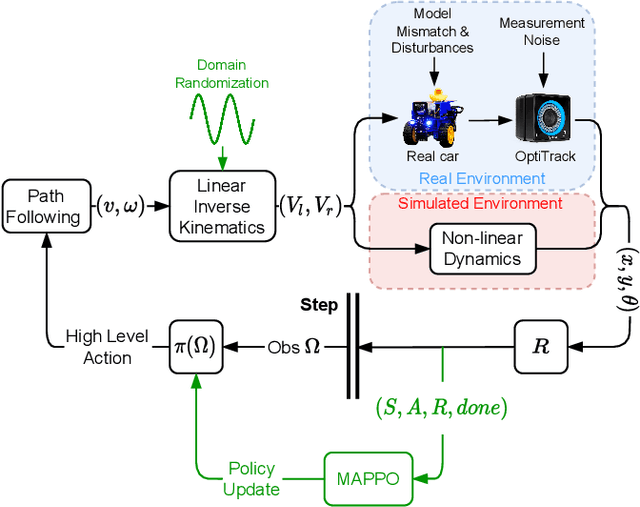
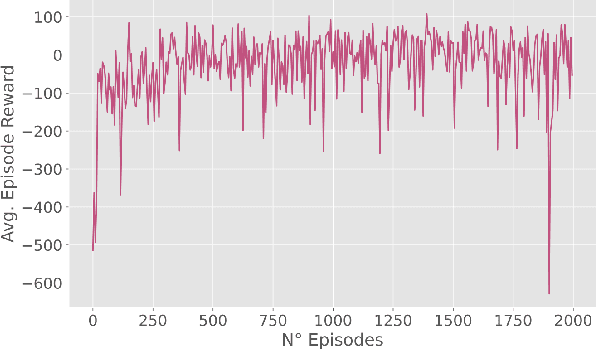
Autonomous Driving requires high levels of coordination and collaboration between agents. Achieving effective coordination in multi-agent systems is a difficult task that remains largely unresolved. Multi-Agent Reinforcement Learning has arisen as a powerful method to accomplish this task because it considers the interaction between agents and also allows for decentralized training -- which makes it highly scalable. However, transferring policies from simulation to the real world is a big challenge, even for single-agent applications. Multi-agent systems add additional complexities to the Sim-to-Real gap due to agent collaboration and environment synchronization. In this paper, we propose a method to transfer multi-agent autonomous driving policies to the real world. For this, we create a multi-agent environment that imitates the dynamics of the Duckietown multi-robot testbed, and train multi-agent policies using the MAPPO algorithm with different levels of domain randomization. We then transfer the trained policies to the Duckietown testbed and compare the use of the MAPPO algorithm against a traditional rule-based method. We show that the rewards of the transferred policies with MAPPO and domain randomization are, on average, 1.85 times superior to the rule-based method. Moreover, we show that different levels of parameter randomization have a substantial impact on the Sim-to-Real gap.