 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Sequence Clustering for Human Intention Inference
Paper and Code
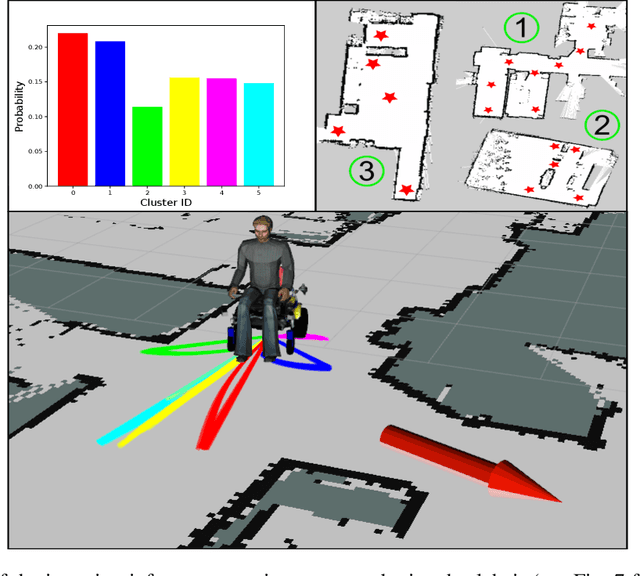
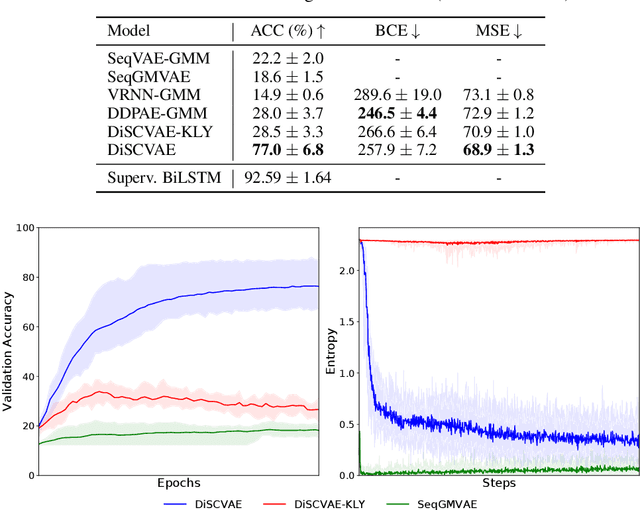
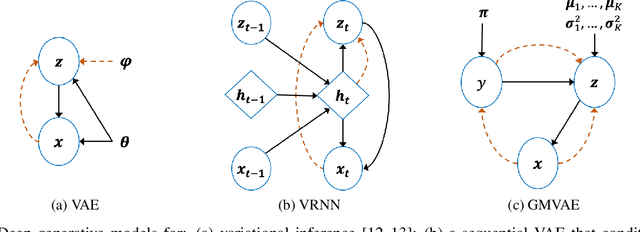

Equipping robots with the ability to infer human intent is a vital precondition for effective collaboration. Most computational approaches towards this objective employ probabilistic reasoning to recover a distribution of "intent" conditioned on the robot's perceived sensory state. However, these approaches typically assume task-specific notions of human intent (e.g. labelled goals) are known a priori. To overcome this constraint, we propose the Disentangled Sequence Clustering Variational Autoencoder (DiSCVAE), a clustering framework that can be used to learn such a distribution of intent in an unsupervised manner. The DiSCVAE leverages recent advances in unsupervised learning to derive a disentangled latent representation of sequential data, separating time-varying local features from time-invariant global aspects. Though unlike previous frameworks for disentanglement, the proposed variant also infers a discrete variable to form a latent mixture model and enable clustering of global sequence concepts, e.g. intentions from observed human behaviour. To evaluate the DiSCVAE, we first validate its capacity to discover classes from unlabelled sequences using video datasets of bouncing digits and 2D animations. We then report results from a real-world human-robot interaction experiment conducted on a robotic wheelchair. Our findings glean insights into how the inferred discrete variable coincides with human intent and thus serves to improve assistance in collaborative settings, such as shared control.