 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Language-Colored Pointmap Pretraining for Unified 3D Scene Understanding
Apr 02, 2026Pretraining 3D encoders by aligning with Contrastive Language Image Pretraining (CLIP) has emerged as a promising direction to learn generalizable representations for 3D scene understanding. In this paper, we propose UniScene3D, a transformer-based encoder that learns unified scene representations from multi-view colored pointmaps, jointly modeling image appearance and geometry. For robust colored pointmap representation learning, we introduce novel cross-view geometric alignment and grounded view alignment to enforce cross-view geometry and semantic consistency. Extensive low-shot and task-specific fine-tuning evaluations on viewpoint grounding, scene retrieval, scene type classification, and 3D VQA demonstrate our state-of-the-art performance. These results highlight the effectiveness of our approach for unified 3D scene understanding. https://yebulabula.github.io/UniScene3D/
From None to All: Self-Supervised 3D Reconstruction via Novel View Synthesis
Mar 29, 2026In this paper, we introduce NAS3R, a self-supervised feed-forward framework that jointly learns explicit 3D geometry and camera parameters with no ground-truth annotations and no pretrained priors. During training, NAS3R reconstructs 3D Gaussians from uncalibrated and unposed context views and renders target views using its self-predicted camera parameters, enabling self-supervised training from 2D photometric supervision. To ensure stable convergence, NAS3R integrates reconstruction and camera prediction within a shared transformer backbone regulated by masked attention, and adopts a depth-based Gaussian formulation that facilitates well-conditioned optimization. The framework is compatible with state-of-the-art supervised 3D reconstruction architectures and can incorporate pretrained priors or intrinsic information when available. Extensive experiments show that NAS3R achieves superior results to other self-supervised methods, establishing a scalable and geometry-aware paradigm for 3D reconstruction from unconstrained data. Code and models are publicly available at https://ranrhuang.github.io/nas3r/.
Diffusion-aided Extreme Video Compression with Lightweight Semantics Guidance
Feb 05, 2026Modern video codecs and learning-based approaches struggle for semantic reconstruction at extremely low bit-rates due to reliance on low-level spatiotemporal redundancies. Generative models, especially diffusion models, offer a new paradigm for video compression by leveraging high-level semantic understanding and powerful visual synthesis. This paper propose a video compression framework that integrates generative priors to drastically reduce bit-rate while maintaining reconstruction fidelity. Specifically, our method compresses high-level semantic representations of the video, then uses a conditional diffusion model to reconstruct frames from these semantics. To further improve compression, we characterize motion information with global camera trajectories and foreground segmentation: background motion is compactly represented by camera pose parameters while foreground dynamics by sparse segmentation masks. This allows for significantly boosts compression efficiency, enabling descent video reconstruction at extremely low bit-rates.
UCorr: Wire Detection and Depth Estimation for Autonomous Drones
Sep 18, 2025In the realm of fully autonomous drones, the accurate detection of obstacles is paramount to ensure safe navigation and prevent collisions. Among these challenges, the detection of wires stands out due to their slender profile, which poses a unique and intricate problem. To address this issue, we present an innovative solution in the form of a monocular end-to-end model for wire segmentation and depth estimation. Our approach leverages a temporal correlation layer trained on synthetic data, providing the model with the ability to effectively tackle the complex joint task of wire detection and depth estimation. We demonstrate the superiority of our proposed method over existing competitive approaches in the joint task of wire detection and depth estimation. Our results underscore the potential of our model to enhance the safety and precision of autonomous drones, shedding light on its promising applications in real-world scenarios.
* Published in Proceedings of the 4th International Conference on Robotics, Computer Vision and Intelligent Systems (ROBOVIS), 2024
Stereo Any Video: Temporally Consistent Stereo Matching
Mar 07, 2025
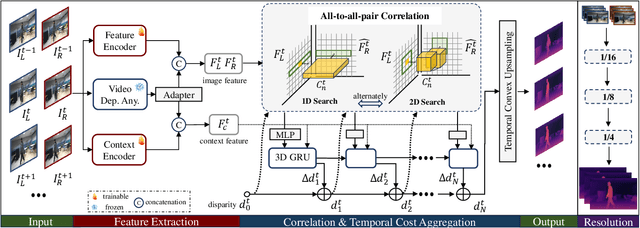
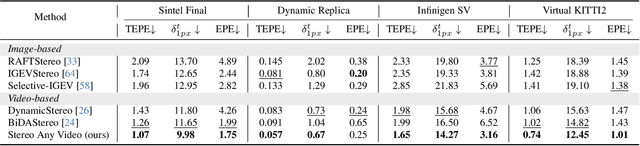
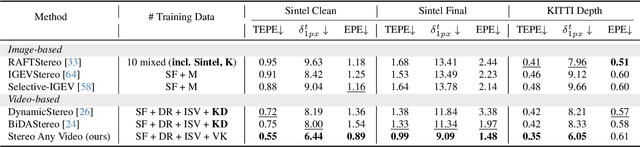
This paper introduces Stereo Any Video, a powerful framework for video stereo matching. It can estimate spatially accurate and temporally consistent disparities without relying on auxiliary information such as camera poses or optical flow. The strong capability is driven by rich priors from monocular video depth models, which are integrated with convolutional features to produce stable representations. To further enhance performance, key architectural innovations are introduced: all-to-all-pairs correlation, which constructs smooth and robust matching cost volumes, and temporal convex upsampling, which improves temporal coherence. These components collectively ensure robustness, accuracy, and temporal consistency, setting a new standard in video stereo matching. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple datasets both qualitatively and quantitatively in zero-shot settings, as well as strong generalization to real-world indoor and outdoor scenarios.
MuBlE: MuJoCo and Blender simulation Environment and Benchmark for Task Planning in Robot Manipulation
Mar 04, 2025Current embodied reasoning agents struggle to plan for long-horizon tasks that require to physically interact with the world to obtain the necessary information (e.g. 'sort the objects from lightest to heaviest'). The improvement of the capabilities of such an agent is highly dependent on the availability of relevant training environments. In order to facilitate the development of such systems, we introduce a novel simulation environment (built on top of robosuite) that makes use of the MuJoCo physics engine and high-quality renderer Blender to provide realistic visual observations that are also accurate to the physical state of the scene. It is the first simulator focusing on long-horizon robot manipulation tasks preserving accurate physics modeling. MuBlE can generate mutlimodal data for training and enable design of closed-loop methods through environment interaction on two levels: visual - action loop, and control - physics loop. Together with the simulator, we propose SHOP-VRB2, a new benchmark composed of 10 classes of multi-step reasoning scenarios that require simultaneous visual and physical measurements.
Hypo3D: Exploring Hypothetical Reasoning in 3D
Feb 04, 2025



The rise of vision-language foundation models marks an advancement in bridging the gap between human and machine capabilities in 3D scene reasoning. Existing 3D reasoning benchmarks assume real-time scene accessibility, which is impractical due to the high cost of frequent scene updates. To this end, we introduce Hypothetical 3D Reasoning, namely Hypo3D, a benchmark designed to evaluate models' ability to reason without access to real-time scene data. Models need to imagine the scene state based on a provided change description before reasoning. Hypo3D is formulated as a 3D Visual Question Answering (VQA) benchmark, comprising 7,727 context changes across 700 indoor scenes, resulting in 14,885 question-answer pairs. An anchor-based world frame is established for all scenes, ensuring consistent reference to a global frame for directional terms in context changes and QAs. Extensive experiments show that state-of-the-art foundation models struggle to reason in hypothetically changed scenes. This reveals a substantial performance gap compared to humans, particularly in scenarios involving movement changes and directional reasoning. Even when the context change is irrelevant to the question, models often incorrectly adjust their answers.
Match Stereo Videos via Bidirectional Alignment
Sep 30, 2024
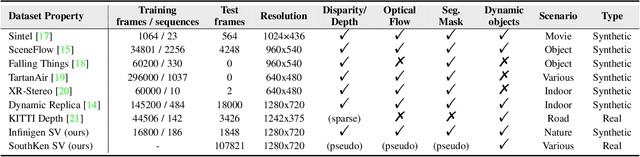


Video stereo matching is the task of estimating consistent disparity maps from rectified stereo videos. There is considerable scope for improvement in both datasets and methods within this area. Recent learning-based methods often focus on optimizing performance for independent stereo pairs, leading to temporal inconsistencies in videos. Existing video methods typically employ sliding window operation over time dimension, which can result in low-frequency oscillations corresponding to the window size. To address these challenges, we propose a bidirectional alignment mechanism for adjacent frames as a fundamental operation. Building on this, we introduce a novel video processing framework, BiDAStereo, and a plugin stabilizer network, BiDAStabilizer, compatible with general image-based methods. Regarding datasets, current synthetic object-based and indoor datasets are commonly used for training and benchmarking, with a lack of outdoor nature scenarios. To bridge this gap, we present a realistic synthetic dataset and benchmark focused on natural scenes, along with a real-world dataset captured by a stereo camera in diverse urban scenes for qualitative evaluation. Extensive experiments on in-domain, out-of-domain, and robustness evaluation demonstrate the contribution of our methods and datasets, showcasing improvements in prediction quality and achieving state-of-the-art results on various commonly used benchmarks. The project page, demos, code, and datasets are available at: \url{https://tomtomtommi.github.io/BiDAVideo/}.
OpenDlign: Enhancing Open-World 3D Learning with Depth-Aligned Images
Apr 25, 2024Recent advances in Vision and Language Models (VLMs) have improved open-world 3D representation, facilitating 3D zero-shot capability in unseen categories. Existing open-world methods pre-train an extra 3D encoder to align features from 3D data (e.g., depth maps or point clouds) with CAD-rendered images and corresponding texts. However, the limited color and texture variations in CAD images can compromise the alignment robustness. Furthermore, the volume discrepancy between pre-training datasets of the 3D encoder and VLM leads to sub-optimal 2D to 3D knowledge transfer. To overcome these issues, we propose OpenDlign, a novel framework for learning open-world 3D representations, that leverages depth-aligned images generated from point cloud-projected depth maps. Unlike CAD-rendered images, our generated images provide rich, realistic color and texture diversity while preserving geometric and semantic consistency with the depth maps. OpenDlign also optimizes depth map projection and integrates depth-specific text prompts, improving 2D VLM knowledge adaptation for 3D learning efficient fine-tuning. Experimental results show that OpenDlign significantly outperforms existing benchmarks in zero-shot and few-shot 3D tasks, exceeding prior scores by 8.0% on ModelNet40 and 16.4% on OmniObject3D with just 6 million tuned parameters. Moreover, integrating generated depth-aligned images into existing 3D learning pipelines consistently improves their performance.
Closed Loop Interactive Embodied Reasoning for Robot Manipulation
Apr 23, 2024Embodied reasoning systems integrate robotic hardware and cognitive processes to perform complex tasks typically in response to a natural language query about a specific physical environment. This usually involves changing the belief about the scene or physically interacting and changing the scene (e.g. 'Sort the objects from lightest to heaviest'). In order to facilitate the development of such systems we introduce a new simulating environment that makes use of MuJoCo physics engine and high-quality renderer Blender to provide realistic visual observations that are also accurate to the physical state of the scene. Together with the simulator we propose a new benchmark composed of 10 classes of multi-step reasoning scenarios that require simultaneous visual and physical measurements. Finally, we develop a new modular Closed Loop Interactive Reasoning (CLIER) approach that takes into account the measurements of non-visual object properties, changes in the scene caused by external disturbances as well as uncertain outcomes of robotic actions. We extensively evaluate our reasoning approach in simulation and in the real world manipulation tasks with a success rate above 76% and 64%, respectively.