 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Any Video: Temporally Consistent Stereo Matching
Mar 07, 2025
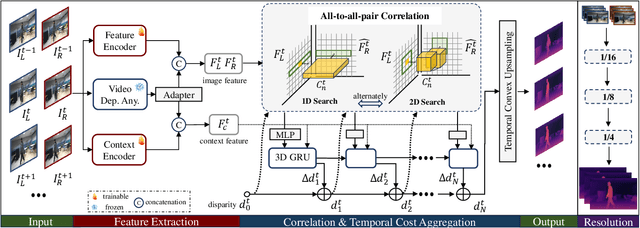
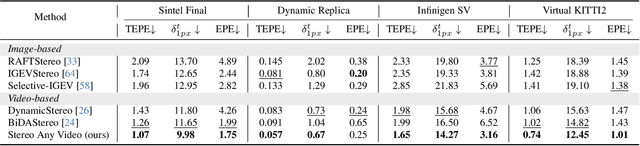
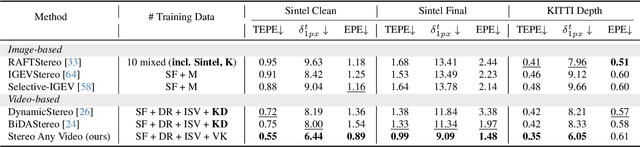
This paper introduces Stereo Any Video, a powerful framework for video stereo matching. It can estimate spatially accurate and temporally consistent disparities without relying on auxiliary information such as camera poses or optical flow. The strong capability is driven by rich priors from monocular video depth models, which are integrated with convolutional features to produce stable representations. To further enhance performance, key architectural innovations are introduced: all-to-all-pairs correlation, which constructs smooth and robust matching cost volumes, and temporal convex upsampling, which improves temporal coherence. These components collectively ensure robustness, accuracy, and temporal consistency, setting a new standard in video stereo matching. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple datasets both qualitatively and quantitatively in zero-shot settings, as well as strong generalization to real-world indoor and outdoor scenarios.
Hypo3D: Exploring Hypothetical Reasoning in 3D
Feb 04, 2025



The rise of vision-language foundation models marks an advancement in bridging the gap between human and machine capabilities in 3D scene reasoning. Existing 3D reasoning benchmarks assume real-time scene accessibility, which is impractical due to the high cost of frequent scene updates. To this end, we introduce Hypothetical 3D Reasoning, namely Hypo3D, a benchmark designed to evaluate models' ability to reason without access to real-time scene data. Models need to imagine the scene state based on a provided change description before reasoning. Hypo3D is formulated as a 3D Visual Question Answering (VQA) benchmark, comprising 7,727 context changes across 700 indoor scenes, resulting in 14,885 question-answer pairs. An anchor-based world frame is established for all scenes, ensuring consistent reference to a global frame for directional terms in context changes and QAs. Extensive experiments show that state-of-the-art foundation models struggle to reason in hypothetically changed scenes. This reveals a substantial performance gap compared to humans, particularly in scenarios involving movement changes and directional reasoning. Even when the context change is irrelevant to the question, models often incorrectly adjust their answers.
SVRDA: A Web-based Dataset Annotation Tool for Slice-to-Volume Registration
Nov 27, 2023


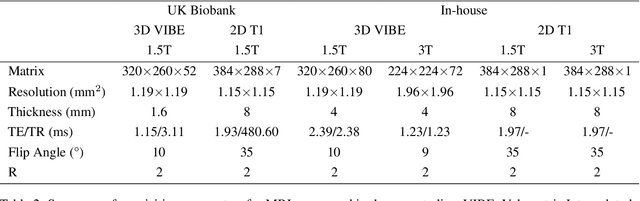
Background and Objective: The lack of benchmark datasets has impeded the development of slice-to-volume registration algorithms. Such datasets are difficult to annotate, primarily due to the dimensional difference within data and the dearth of task-specific software. We aim to develop a user-friendly tool to streamline dataset annotation for slice-to-volume registration. Methods: The proposed tool, named SVRDA, is an installation-free web application for platform-agnostic collaborative dataset annotation. It enables efficient transformation manipulation via keyboard shortcuts and smooth case transitions with auto-saving. SVRDA supports configuration-based data loading and adheres to the separation of concerns, offering great flexibility and extensibility for future research. Various supplementary features have been implemented to facilitate slice-to-volume registration. Results: We validated the effectiveness of SVRDA by indirectly evaluating the post-registration segmentation quality on UK Biobank data, observing a dramatic overall improvement (24.02% in the Dice Similarity Coefficient and 48.93% in the 95th percentile Hausdorff distance, respectively) supported by highly statistically significant evidence ($p<0.001$).We further showcased the clinical usage of SVRDA by integrating it into test-retest T1 quantification on in-house magnetic resonance images, leading to more consistent results after registration. Conclusions: SVRDA can facilitate collaborative annotation of benchmark datasets while being potentially applicable to other pipelines incorporating slice-to-volume registration. Full source code and documentation are available at https://github.com/Roldbach/SVRDA