 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypo3D: Exploring Hypothetical Reasoning in 3D
Feb 04, 2025



The rise of vision-language foundation models marks an advancement in bridging the gap between human and machine capabilities in 3D scene reasoning. Existing 3D reasoning benchmarks assume real-time scene accessibility, which is impractical due to the high cost of frequent scene updates. To this end, we introduce Hypothetical 3D Reasoning, namely Hypo3D, a benchmark designed to evaluate models' ability to reason without access to real-time scene data. Models need to imagine the scene state based on a provided change description before reasoning. Hypo3D is formulated as a 3D Visual Question Answering (VQA) benchmark, comprising 7,727 context changes across 700 indoor scenes, resulting in 14,885 question-answer pairs. An anchor-based world frame is established for all scenes, ensuring consistent reference to a global frame for directional terms in context changes and QAs. Extensive experiments show that state-of-the-art foundation models struggle to reason in hypothetically changed scenes. This reveals a substantial performance gap compared to humans, particularly in scenarios involving movement changes and directional reasoning. Even when the context change is irrelevant to the question, models often incorrectly adjust their answers.
Match Stereo Videos via Bidirectional Alignment
Sep 30, 2024
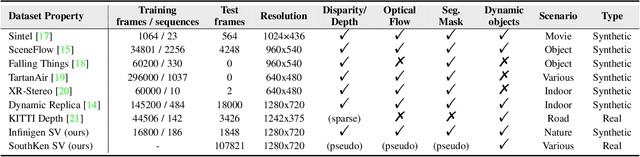


Video stereo matching is the task of estimating consistent disparity maps from rectified stereo videos. There is considerable scope for improvement in both datasets and methods within this area. Recent learning-based methods often focus on optimizing performance for independent stereo pairs, leading to temporal inconsistencies in videos. Existing video methods typically employ sliding window operation over time dimension, which can result in low-frequency oscillations corresponding to the window size. To address these challenges, we propose a bidirectional alignment mechanism for adjacent frames as a fundamental operation. Building on this, we introduce a novel video processing framework, BiDAStereo, and a plugin stabilizer network, BiDAStabilizer, compatible with general image-based methods. Regarding datasets, current synthetic object-based and indoor datasets are commonly used for training and benchmarking, with a lack of outdoor nature scenarios. To bridge this gap, we present a realistic synthetic dataset and benchmark focused on natural scenes, along with a real-world dataset captured by a stereo camera in diverse urban scenes for qualitative evaluation. Extensive experiments on in-domain, out-of-domain, and robustness evaluation demonstrate the contribution of our methods and datasets, showcasing improvements in prediction quality and achieving state-of-the-art results on various commonly used benchmarks. The project page, demos, code, and datasets are available at: \url{https://tomtomtommi.github.io/BiDAVideo/}.