 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Any Video: Temporally Consistent Stereo Matching
Mar 07, 2025
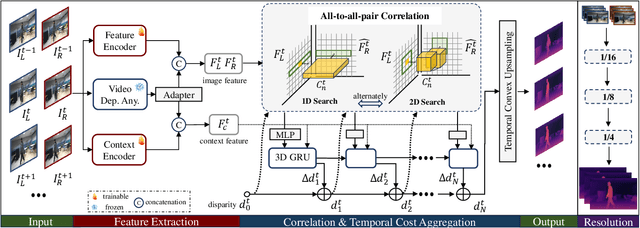
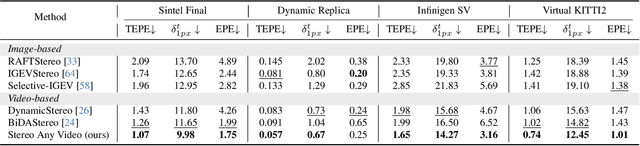
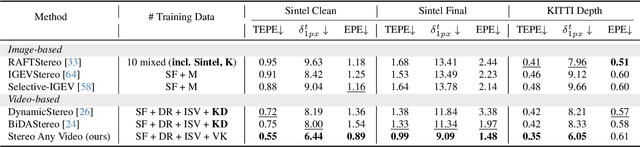
This paper introduces Stereo Any Video, a powerful framework for video stereo matching. It can estimate spatially accurate and temporally consistent disparities without relying on auxiliary information such as camera poses or optical flow. The strong capability is driven by rich priors from monocular video depth models, which are integrated with convolutional features to produce stable representations. To further enhance performance, key architectural innovations are introduced: all-to-all-pairs correlation, which constructs smooth and robust matching cost volumes, and temporal convex upsampling, which improves temporal coherence. These components collectively ensure robustness, accuracy, and temporal consistency, setting a new standard in video stereo matching. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple datasets both qualitatively and quantitatively in zero-shot settings, as well as strong generalization to real-world indoor and outdoor scenarios.
Hypo3D: Exploring Hypothetical Reasoning in 3D
Feb 04, 2025



The rise of vision-language foundation models marks an advancement in bridging the gap between human and machine capabilities in 3D scene reasoning. Existing 3D reasoning benchmarks assume real-time scene accessibility, which is impractical due to the high cost of frequent scene updates. To this end, we introduce Hypothetical 3D Reasoning, namely Hypo3D, a benchmark designed to evaluate models' ability to reason without access to real-time scene data. Models need to imagine the scene state based on a provided change description before reasoning. Hypo3D is formulated as a 3D Visual Question Answering (VQA) benchmark, comprising 7,727 context changes across 700 indoor scenes, resulting in 14,885 question-answer pairs. An anchor-based world frame is established for all scenes, ensuring consistent reference to a global frame for directional terms in context changes and QAs. Extensive experiments show that state-of-the-art foundation models struggle to reason in hypothetically changed scenes. This reveals a substantial performance gap compared to humans, particularly in scenarios involving movement changes and directional reasoning. Even when the context change is irrelevant to the question, models often incorrectly adjust their answers.
Match Stereo Videos via Bidirectional Alignment
Sep 30, 2024
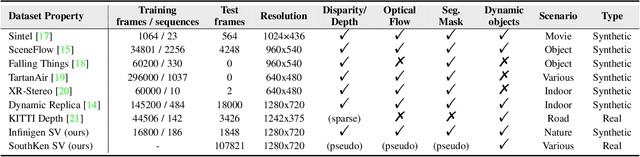


Video stereo matching is the task of estimating consistent disparity maps from rectified stereo videos. There is considerable scope for improvement in both datasets and methods within this area. Recent learning-based methods often focus on optimizing performance for independent stereo pairs, leading to temporal inconsistencies in videos. Existing video methods typically employ sliding window operation over time dimension, which can result in low-frequency oscillations corresponding to the window size. To address these challenges, we propose a bidirectional alignment mechanism for adjacent frames as a fundamental operation. Building on this, we introduce a novel video processing framework, BiDAStereo, and a plugin stabilizer network, BiDAStabilizer, compatible with general image-based methods. Regarding datasets, current synthetic object-based and indoor datasets are commonly used for training and benchmarking, with a lack of outdoor nature scenarios. To bridge this gap, we present a realistic synthetic dataset and benchmark focused on natural scenes, along with a real-world dataset captured by a stereo camera in diverse urban scenes for qualitative evaluation. Extensive experiments on in-domain, out-of-domain, and robustness evaluation demonstrate the contribution of our methods and datasets, showcasing improvements in prediction quality and achieving state-of-the-art results on various commonly used benchmarks. The project page, demos, code, and datasets are available at: \url{https://tomtomtommi.github.io/BiDAVideo/}.
OpenDlign: Enhancing Open-World 3D Learning with Depth-Aligned Images
Apr 25, 2024Recent advances in Vision and Language Models (VLMs) have improved open-world 3D representation, facilitating 3D zero-shot capability in unseen categories. Existing open-world methods pre-train an extra 3D encoder to align features from 3D data (e.g., depth maps or point clouds) with CAD-rendered images and corresponding texts. However, the limited color and texture variations in CAD images can compromise the alignment robustness. Furthermore, the volume discrepancy between pre-training datasets of the 3D encoder and VLM leads to sub-optimal 2D to 3D knowledge transfer. To overcome these issues, we propose OpenDlign, a novel framework for learning open-world 3D representations, that leverages depth-aligned images generated from point cloud-projected depth maps. Unlike CAD-rendered images, our generated images provide rich, realistic color and texture diversity while preserving geometric and semantic consistency with the depth maps. OpenDlign also optimizes depth map projection and integrates depth-specific text prompts, improving 2D VLM knowledge adaptation for 3D learning efficient fine-tuning. Experimental results show that OpenDlign significantly outperforms existing benchmarks in zero-shot and few-shot 3D tasks, exceeding prior scores by 8.0% on ModelNet40 and 16.4% on OmniObject3D with just 6 million tuned parameters. Moreover, integrating generated depth-aligned images into existing 3D learning pipelines consistently improves their performance.
Match-Stereo-Videos: Bidirectional Alignment for Consistent Dynamic Stereo Matching
Mar 16, 2024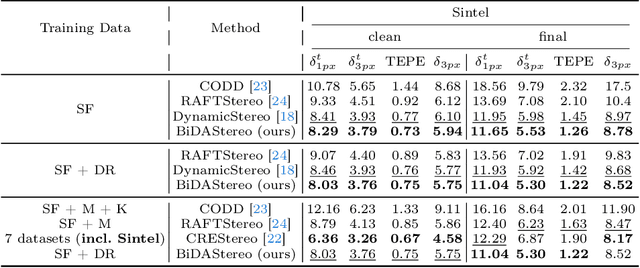
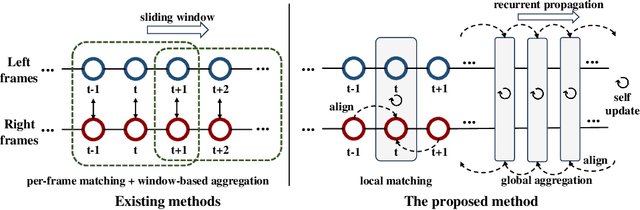
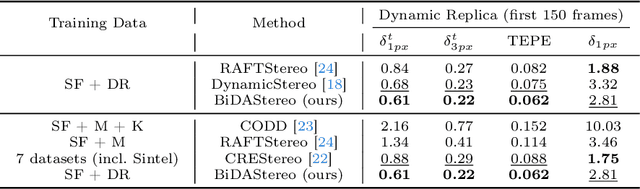
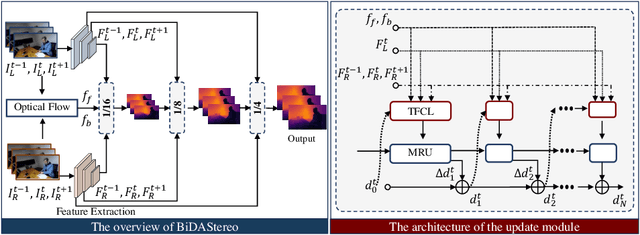
Dynamic stereo matching is the task of estimating consistent disparities from stereo videos with dynamic objects. Recent learning-based methods prioritize optimal performance on a single stereo pair, resulting in temporal inconsistencies. Existing video methods apply per-frame matching and window-based cost aggregation across the time dimension, leading to low-frequency oscillations at the scale of the window size. Towards this challenge, we develop a bidirectional alignment mechanism for adjacent frames as a fundamental operation. We further propose a novel framework, BiDAStereo, that achieves consistent dynamic stereo matching. Unlike the existing methods, we model this task as local matching and global aggregation. Locally, we consider correlation in a triple-frame manner to pool information from adjacent frames and improve the temporal consistency. Globally, to exploit the entire sequence's consistency and extract dynamic scene cues for aggregation, we develop a motion-propagation recurrent unit. Extensive experiments demonstrate the performance of our method, showcasing improvements in prediction quality and achieving state-of-the-art results on various commonly used benchmarks.
Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching
Jul 26, 2023Correlation based stereo matching has achieved outstanding performance, which pursues cost volume between two feature maps. Unfortunately, current methods with a fixed model do not work uniformly well across various datasets, greatly limiting their real-world applicability. To tackle this issue, this paper proposes a new perspective to dynamically calculate correlation for robust stereo matching. A novel Uncertainty Guided Adaptive Correlation (UGAC) module is introduced to robustly adapt the same model for different scenarios. Specifically, a variance-based uncertainty estimation is employed to adaptively adjust the sampling area during warping operation. Additionally, we improve the traditional non-parametric warping with learnable parameters, such that the position-specific weights can be learned. We show that by empowering the recurrent network with the UGAC module, stereo matching can be exploited more robustly and effectively. Extensive experiments demonstrate that our method achieves state-of-the-art performance over the ETH3D, KITTI, and Middlebury datasets when employing the same fixed model over these datasets without any retraining procedure. To target real-time applications, we further design a lightweight model based on UGAC, which also outperforms other methods over KITTI benchmarks with only 0.6 M parameters.