 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Features with Flow Infused Attention for Realistic Virtual Try-On
Dec 16, 2024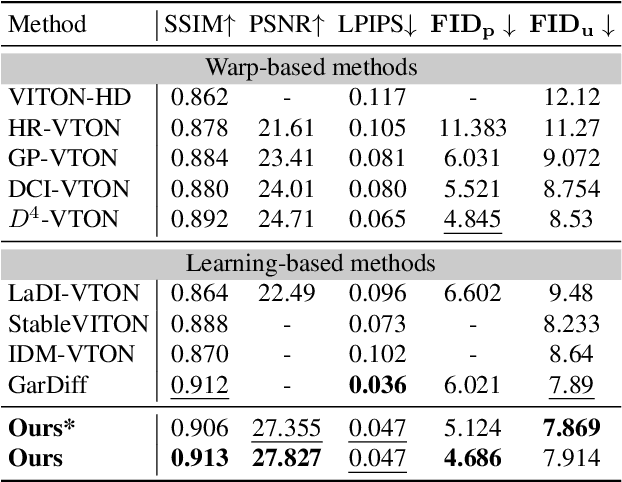
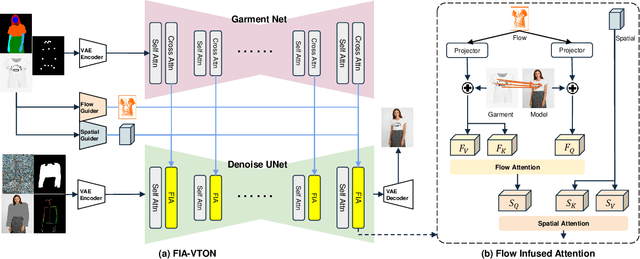
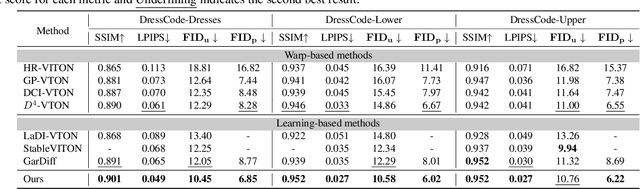

Image-based virtual try-on is challenging since the generated image should fit the garment to model images in various poses and keep the characteristics and details of the garment simultaneously. A popular research stream warps the garment image firstly to reduce the burden of the generation stage, which relies highly on the performance of the warping module. Other methods without explicit warping often lack sufficient guidance to fit the garment to the model images. In this paper, we propose FIA-VTON, which leverages the implicit warp feature by adopting a Flow Infused Attention module on virtual try-on. The dense warp flow map is projected as indirect guidance attention to enhance the feature map warping in the generation process implicitly, which is less sensitive to the warping estimation accuracy than an explicit warp of the garment image. To further enhance implicit warp guidance, we incorporate high-level spatial attention to complement the dense warp. Experimental results on the VTON-HD and DressCode dataset significantly outperform state-of-the-art methods, demonstrating that FIA-VTON is effective and robust for virtual try-on.
CPN: Complementary Proposal Network for Unconstrained Text Detection
Feb 18, 2024Existing methods for scene text detection can be divided into two paradigms: segmentation-based and anchor-based. While Segmentation-based methods are well-suited for irregular shapes, they struggle with compact or overlapping layouts. Conversely, anchor-based approaches excel for complex layouts but suffer from irregular shapes. To strengthen their merits and overcome their respective demerits, we propose a Complementary Proposal Network (CPN) that seamlessly and parallelly integrates semantic and geometric information for superior performance. The CPN comprises two efficient networks for proposal generation: the Deformable Morphology Semantic Network, which generates semantic proposals employing an innovative deformable morphological operator, and the Balanced Region Proposal Network, which produces geometric proposals with pre-defined anchors. To further enhance the complementarity, we introduce an Interleaved Feature Attention module that enables semantic and geometric features to interact deeply before proposal generation. By leveraging both complementary proposals and features, CPN outperforms state-of-the-art approaches with significant margins under comparable computation cost. Specifically, our approach achieves improvements of 3.6%, 1.3% and 1.0% on challenging benchmarks ICDAR19-ArT, IC15, and MSRA-TD500, respectively. Code for our method will be released.
Center Contrastive Loss for Metric Learning
Aug 01, 2023Contrastive learning is a major studied topic in metric learning. However, sampling effective contrastive pairs remains a challenge due to factors such as limited batch size, imbalanced data distribution, and the risk of overfitting. In this paper, we propose a novel metric learning function called Center Contrastive Loss, which maintains a class-wise center bank and compares the category centers with the query data points using a contrastive loss. The center bank is updated in real-time to boost model convergence without the need for well-designed sample mining. The category centers are well-optimized classification proxies to re-balance the supervisory signal of each class. Furthermore, the proposed loss combines the advantages of both contrastive and classification methods by reducing intra-class variations and enhancing inter-class differences to improve the discriminative power of embeddings. Our experimental results, as shown in Figure 1, demonstrate that a standard network (ResNet50) trained with our loss achieves state-of-the-art performance and faster convergence.
Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching
Jul 26, 2023Correlation based stereo matching has achieved outstanding performance, which pursues cost volume between two feature maps. Unfortunately, current methods with a fixed model do not work uniformly well across various datasets, greatly limiting their real-world applicability. To tackle this issue, this paper proposes a new perspective to dynamically calculate correlation for robust stereo matching. A novel Uncertainty Guided Adaptive Correlation (UGAC) module is introduced to robustly adapt the same model for different scenarios. Specifically, a variance-based uncertainty estimation is employed to adaptively adjust the sampling area during warping operation. Additionally, we improve the traditional non-parametric warping with learnable parameters, such that the position-specific weights can be learned. We show that by empowering the recurrent network with the UGAC module, stereo matching can be exploited more robustly and effectively. Extensive experiments demonstrate that our method achieves state-of-the-art performance over the ETH3D, KITTI, and Middlebury datasets when employing the same fixed model over these datasets without any retraining procedure. To target real-time applications, we further design a lightweight model based on UGAC, which also outperforms other methods over KITTI benchmarks with only 0.6 M parameters.
Both Spatial and Frequency Cues Contribute to High-Fidelity Image Inpainting
Jul 15, 2023Deep generative approaches have obtained great success in image inpainting recently. However, most generative inpainting networks suffer from either over-smooth results or aliasing artifacts. The former lacks high-frequency details, while the latter lacks semantic structure. To address this issue, we propose an effective Frequency-Spatial Complementary Network (FSCN) by exploiting rich semantic information in both spatial and frequency domains. Specifically, we introduce an extra Frequency Branch and Frequency Loss on the spatial-based network to impose direct supervision on the frequency information, and propose a Frequency-Spatial Cross-Attention Block (FSCAB) to fuse multi-domain features and combine the corresponding characteristics. With our FSCAB, the inpainting network is capable of capturing frequency information and preserving visual consistency simultaneously. Extensive quantitative and qualitative experiments demonstrate that our inpainting network can effectively achieve superior results, outperforming previous state-of-the-art approaches with significantly fewer parameters and less computation cost. The code will be released soon.
Video-Text as Game Players: Hierarchical Banzhaf Interaction for Cross-Modal Representation Learning
Mar 25, 2023



Contrastive learning-based video-language representation learning approaches, e.g., CLIP, have achieved outstanding performance, which pursue semantic interaction upon pre-defined video-text pairs. To clarify this coarse-grained global interaction and move a step further, we have to encounter challenging shell-breaking interactions for fine-grained cross-modal learning. In this paper, we creatively model video-text as game players with multivariate cooperative game theory to wisely handle the uncertainty during fine-grained semantic interaction with diverse granularity, flexible combination, and vague intensity. Concretely, we propose Hierarchical Banzhaf Interaction (HBI) to value possible correspondence between video frames and text words for sensitive and explainable cross-modal contrast. To efficiently realize the cooperative game of multiple video frames and multiple text words, the proposed method clusters the original video frames (text words) and computes the Banzhaf Interaction between the merged tokens. By stacking token merge modules, we achieve cooperative games at different semantic levels. Extensive experiments on commonly used text-video retrieval and video-question answering benchmarks with superior performances justify the efficacy of our HBI. More encouragingly, it can also serve as a visualization tool to promote the understanding of cross-modal interaction, which have a far-reaching impact on the community. Project page is available at https://jpthu17.github.io/HBI/.
RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization
Nov 11, 2022



Feature reuse has been a key technique in light-weight convolutional neural networks (CNNs) design. Current methods usually utilize a concatenation operator to keep large channel numbers cheaply (thus large network capacity) by reusing feature maps from other layers. Although concatenation is parameters- and FLOPs-free, its computational cost on hardware devices is non-negligible. To address this, this paper provides a new perspective to realize feature reuse via structural re-parameterization technique. A novel hardware-efficient RepGhost module is proposed for implicit feature reuse via re-parameterization, instead of using concatenation operator. Based on the RepGhost module, we develop our efficient RepGhost bottleneck and RepGhostNet. Experiments on ImageNet and COCO benchmarks demonstrate that the proposed RepGhostNet is much more effective and efficient than GhostNet and MobileNetV3 on mobile devices. Specially, our RepGhostNet surpasses GhostNet 0.5x by 2.5% Top-1 accuracy on ImageNet dataset with less parameters and comparable latency on an ARM-based mobile phone.
TS2-Net: Token Shift and Selection Transformer for Text-Video Retrieval
Jul 16, 2022
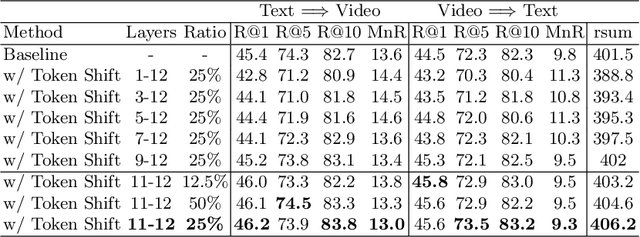
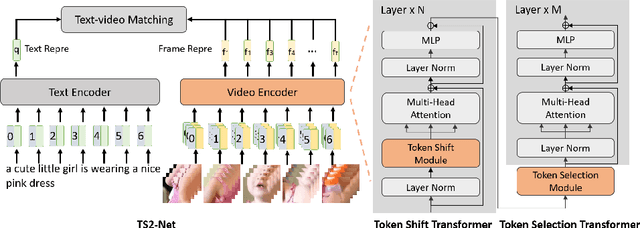
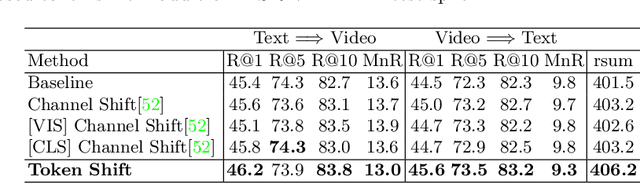
Text-Video retrieval is a task of great practical value and has received increasing attention, among which learning spatial-temporal video representation is one of the research hotspots. The video encoders in the state-of-the-art video retrieval models usually directly adopt the pre-trained vision backbones with the network structure fixed, they therefore can not be further improved to produce the fine-grained spatial-temporal video representation. In this paper, we propose Token Shift and Selection Network (TS2-Net), a novel token shift and selection transformer architecture, which dynamically adjusts the token sequence and selects informative tokens in both temporal and spatial dimensions from input video samples. The token shift module temporally shifts the whole token features back-and-forth across adjacent frames, to preserve the complete token representation and capture subtle movements. Then the token selection module selects tokens that contribute most to local spatial semantics. Based on thorough experiments, the proposed TS2-Net achieves state-of-the-art performance on major text-video retrieval benchmarks, including new records on MSRVTT, VATEX, LSMDC, ActivityNet, and DiDeMo.
Aesthetic Text Logo Synthesis via Content-aware Layout Inferring
Apr 06, 2022
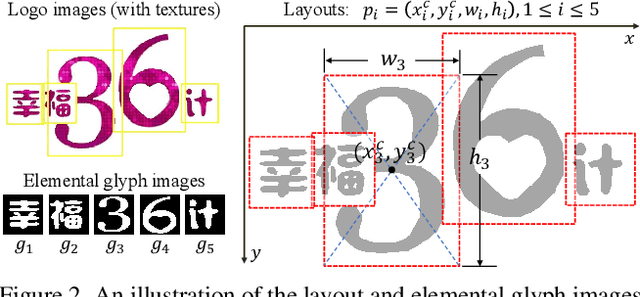
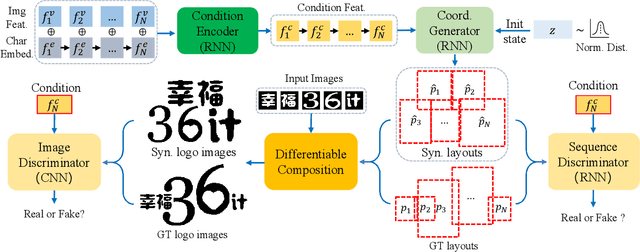
Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this task which needs to take many factors (e.g., fonts, linguistics, topics, etc.) into consideration. In this paper, we propose a content-aware layout generation network which takes glyph images and their corresponding text as input and synthesizes aesthetic layouts for them automatically. Specifically, we develop a dual-discriminator module, including a sequence discriminator and an image discriminator, to evaluate both the character placing trajectories and rendered shapes of synthesized text logos, respectively. Furthermore, we fuse the information of linguistics from texts and visual semantics from glyphs to guide layout prediction, which both play important roles in professional layout design. To train and evaluate our approach, we construct a dataset named as TextLogo3K, consisting of about 3,500 text logo images and their pixel-level annotations. Experimental studies on this dataset demonstrate the effectiveness of our approach for synthesizing visually-pleasing text logos and verify its superiority against the state of the art.
DIP: Deep Inverse Patchmatch for High-Resolution Optical Flow
Apr 01, 2022
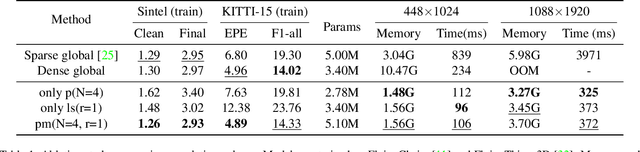
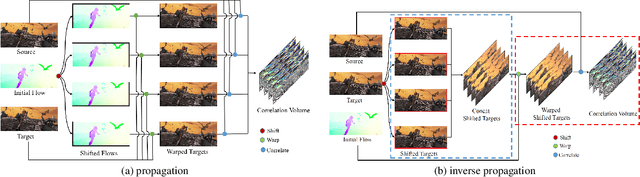
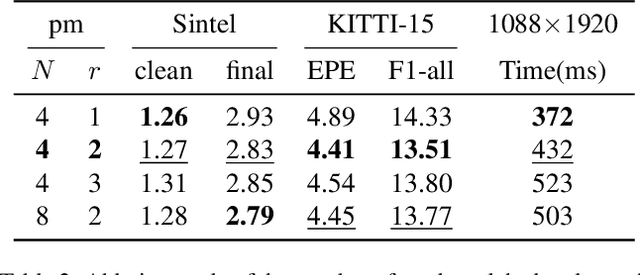
Recently, the dense correlation volume method achieves state-of-the-art performance in optical flow. However, the correlation volume computation requires a lot of memory, which makes prediction difficult on high-resolution images. In this paper, we propose a novel Patchmatch-based framework to work on high-resolution optical flow estimation. Specifically, we introduce the first end-to-end Patchmatch based deep learning optical flow. It can get high-precision results with lower memory benefiting from propagation and local search of Patchmatch. Furthermore, a new inverse propagation is proposed to decouple the complex operations of propagation, which can significantly reduce calculations in multiple iterations. At the time of submission, our method ranks first on all the metrics on the popular KITTI2015 benchmark, and ranks second on EPE on the Sintel clean benchmark among published optical flow methods. Experiment shows our method has a strong cross-dataset generalization ability that the F1-all achieves 13.73%, reducing 21% from the best published result 17.4% on KITTI2015. What's more, our method shows a good details preserving result on the high-resolution dataset DAVIS and consumes 2x less memory than RAFT.