 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS2-Net: Token Shift and Selection Transformer for Text-Video Retrieval
Jul 16, 2022
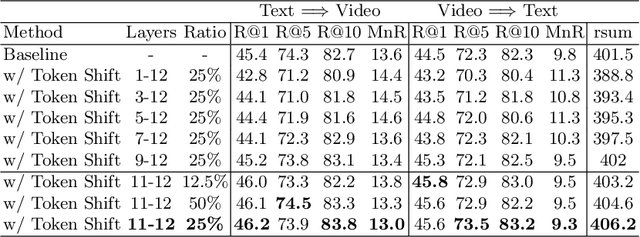
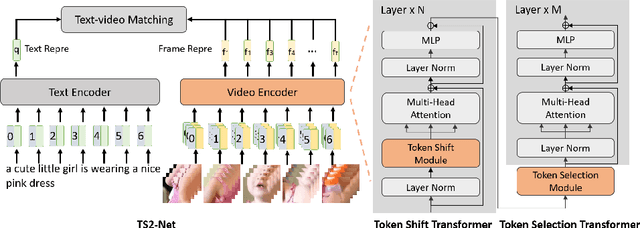
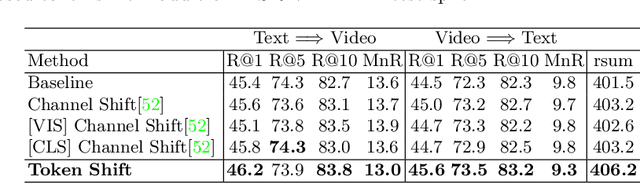
Text-Video retrieval is a task of great practical value and has received increasing attention, among which learning spatial-temporal video representation is one of the research hotspots. The video encoders in the state-of-the-art video retrieval models usually directly adopt the pre-trained vision backbones with the network structure fixed, they therefore can not be further improved to produce the fine-grained spatial-temporal video representation. In this paper, we propose Token Shift and Selection Network (TS2-Net), a novel token shift and selection transformer architecture, which dynamically adjusts the token sequence and selects informative tokens in both temporal and spatial dimensions from input video samples. The token shift module temporally shifts the whole token features back-and-forth across adjacent frames, to preserve the complete token representation and capture subtle movements. Then the token selection module selects tokens that contribute most to local spatial semantics. Based on thorough experiments, the proposed TS2-Net achieves state-of-the-art performance on major text-video retrieval benchmarks, including new records on MSRVTT, VATEX, LSMDC, ActivityNet, and DiDeMo.
CLIP2Video: Mastering Video-Text Retrieval via Image CLIP
Jun 21, 2021



We present CLIP2Video network to transfer the image-language pre-training model to video-text retrieval in an end-to-end manner. Leading approaches in the domain of video-and-language learning try to distill the spatio-temporal video features and multi-modal interaction between videos and languages from a large-scale video-text dataset. Different from them, we leverage pretrained image-language model, simplify it as a two-stage framework with co-learning of image-text and enhancing temporal relations between video frames and video-text respectively, make it able to train on comparatively small datasets. Specifically, based on the spatial semantics captured by Contrastive Language-Image Pretraining (CLIP) model, our model involves a Temporal Difference Block to capture motions at fine temporal video frames, and a Temporal Alignment Block to re-align the tokens of video clips and phrases and enhance the multi-modal correlation. We conduct thorough ablation studies, and achieve state-of-the-art performance on major text-to-video and video-to-text retrieval benchmarks, including new records of retrieval accuracy on MSR-VTT, MSVD and VATEX.