 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAllocentric Perceiver: Disentangling Allocentric Reasoning from Egocentric Visual Priors via Frame Instantiation
Feb 05, 2026With the rising need for spatially grounded tasks such as Vision-Language Navigation/Action, allocentric perception capabilities in Vision-Language Models (VLMs) are receiving growing focus. However, VLMs remain brittle on allocentric spatial queries that require explicit perspective shifts, where the answer depends on reasoning in a target-centric frame rather than the observed camera view. Thus, we introduce Allocentric Perceiver, a training-free strategy that recovers metric 3D states from one or more images with off-the-shelf geometric experts, and then instantiates a query-conditioned allocentric reference frame aligned with the instruction's semantic intent. By deterministically transforming reconstructed geometry into the target frame and prompting the backbone VLM with structured, geometry-grounded representations, Allocentric Perceriver offloads mental rotation from implicit reasoning to explicit computation. We evaluate Allocentric Perciver across multiple backbone families on spatial reasoning benchmarks, observing consistent and substantial gains ($\sim$10%) on allocentric tasks while maintaining strong egocentric performance, and surpassing both spatial-perception-finetuned models and state-of-the-art open-source and proprietary models.
NiMark: A Non-intrusive Watermarking Framework against Screen-shooting Attacks
Jan 17, 2026Unauthorized screen-shooting poses a critical data leakage risk. Resisting screen-shooting attacks typically requires high-strength watermark embedding, inevitably degrading the cover image. To resolve the robustness-fidelity conflict, non-intrusive watermarking has emerged as a solution by constructing logical verification keys without altering the original content. However, existing non-intrusive schemes lack the capacity to withstand screen-shooting noise. While deep learning offers a potential remedy, we observe that directly applying it leads to a previously underexplored failure mode, the Structural Shortcut: networks tend to learn trivial identity mappings and neglect the image-watermark binding. Furthermore, even when logical binding is enforced, standard training strategies cannot fully bridge the noise gap, yielding suboptimal robustness against physical distortions. In this paper, we propose NiMark, an end-to-end framework addressing these challenges. First, to eliminate the structural shortcut, we introduce the Sigmoid-Gated XOR (SG-XOR) estimator to enable gradient propagation for the logical operation, effectively enforcing rigid image-watermark binding. Second, to overcome the robustness bottleneck, we devise a two-stage training strategy integrating a restorer to bridge the domain gap caused by screen-shooting noise. Experiments demonstrate that NiMark consistently outperforms representative state-of-the-art methods against both digital attacks and screen-shooting noise, while maintaining zero visual distortion.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SSVP: Synergistic Semantic-Visual Prompting for Industrial Zero-Shot Anomaly Detection
Jan 14, 2026Zero-Shot Anomaly Detection (ZSAD) leverages Vision-Language Models (VLMs) to enable supervision-free industrial inspection. However, existing ZSAD paradigms are constrained by single visual backbones, which struggle to balance global semantic generalization with fine-grained structural discriminability. To bridge this gap, we propose Synergistic Semantic-Visual Prompting (SSVP), that efficiently fuses diverse visual encodings to elevate model's fine-grained perception. Specifically, SSVP introduces the Hierarchical Semantic-Visual Synergy (HSVS) mechanism, which deeply integrates DINOv3's multi-scale structural priors into the CLIP semantic space. Subsequently, the Vision-Conditioned Prompt Generator (VCPG) employs cross-modal attention to guide dynamic prompt generation, enabling linguistic queries to precisely anchor to specific anomaly patterns. Furthermore, to address the discrepancy between global scoring and local evidence, the Visual-Text Anomaly Mapper (VTAM) establishes a dual-gated calibration paradigm. Extensive evaluations on seven industrial benchmarks validate the robustness of our method; SSVP achieves state-of-the-art performance with 93.0\% Image-AUROC and 92.2\% Pixel-AUROC on MVTec-AD, significantly outperforming existing zero-shot approaches.
OMP: One-step Meanflow Policy with Directional Alignment
Dec 22, 2025Robot manipulation, a key capability of embodied AI, has turned to data-driven generative policy frameworks, but mainstream approaches like Diffusion Models suffer from high inference latency and Flow-based Methods from increased architectural complexity. While simply applying meanFlow on robotic tasks achieves single-step inference and outperforms FlowPolicy, it lacks few-shot generalization due to fixed temperature hyperparameters in its Dispersive Loss and misaligned predicted-true mean velocities. To solve these issues, this study proposes an improved MeanFlow-based Policies: we introduce a lightweight Cosine Loss to align velocity directions and use the Differential Derivation Equation (DDE) to optimize the Jacobian-Vector Product (JVP) operator. Experiments on Adroit and Meta-World tasks show the proposed method outperforms MP1 and FlowPolicy in average success rate, especially in challenging Meta-World tasks, effectively enhancing few-shot generalization and trajectory accuracy of robot manipulation policies while maintaining real-time performance, offering a more robust solution for high-precision robotic manipulation.
T2SMark: Balancing Robustness and Diversity in Noise-as-Watermark for Diffusion Models
Oct 25, 2025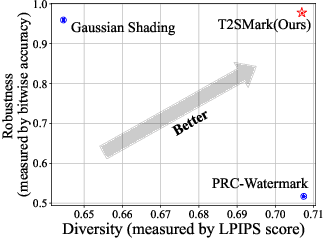
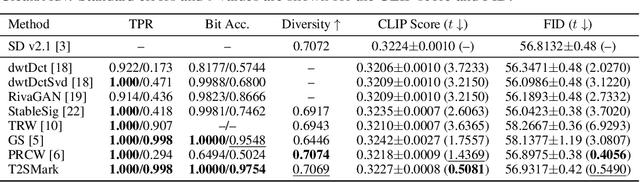
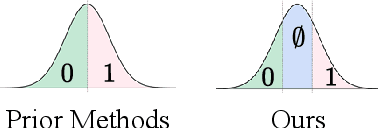
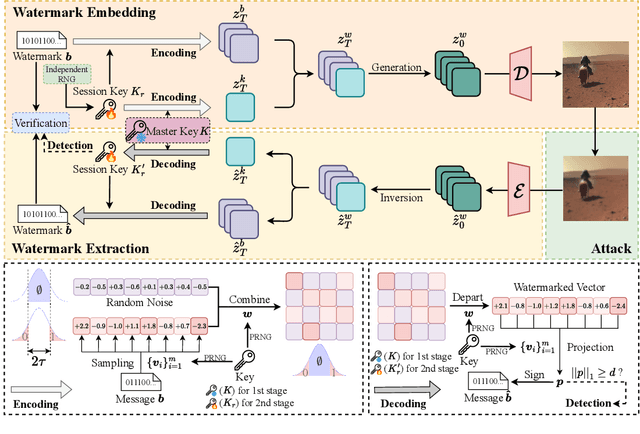
Diffusion models have advanced rapidly in recent years, producing high-fidelity images while raising concerns about intellectual property protection and the misuse of generative AI. Image watermarking for diffusion models, particularly Noise-as-Watermark (NaW) methods, encode watermark as specific standard Gaussian noise vector for image generation, embedding the infomation seamlessly while maintaining image quality. For detection, the generation process is inverted to recover the initial noise vector containing the watermark before extraction. However, existing NaW methods struggle to balance watermark robustness with generation diversity. Some methods achieve strong robustness by heavily constraining initial noise sampling, which degrades user experience, while others preserve diversity but prove too fragile for real-world deployment. To address this issue, we propose T2SMark, a two-stage watermarking scheme based on Tail-Truncated Sampling (TTS). Unlike prior methods that simply map bits to positive or negative values, TTS enhances robustness by embedding bits exclusively in the reliable tail regions while randomly sampling the central zone to preserve the latent distribution. Our two-stage framework then ensures sampling diversity by integrating a randomly generated session key into both encryption pipelines. We evaluate T2SMark on diffusion models with both U-Net and DiT backbones. Extensive experiments show that it achieves an optimal balance between robustness and diversity. Our code is available at \href{https://github.com/0xD009/T2SMark}{https://github.com/0xD009/T2SMark}.
DeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
Sep 18, 2025



Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Boosting LLM Reasoning via Spontaneous Self-Correction
Jun 07, 2025



While large language models (LLMs) have demonstrated remarkable success on a broad range of tasks, math reasoning remains a challenging one. One of the approaches for improving math reasoning is self-correction, which designs self-improving loops to let the model correct its own mistakes. However, existing self-correction approaches treat corrections as standalone post-generation refinements, relying on extra prompt and system designs to elicit self-corrections, instead of performing real-time, spontaneous self-corrections in a single pass. To address this, we propose SPOC, a spontaneous self-correction approach that enables LLMs to generate interleaved solutions and verifications in a single inference pass, with generation dynamically terminated based on verification outcomes, thereby effectively scaling inference time compute. SPOC considers a multi-agent perspective by assigning dual roles -- solution proposer and verifier -- to the same model. We adopt a simple yet effective approach to generate synthetic data for fine-tuning, enabling the model to develop capabilities for self-verification and multi-agent collaboration. We further improve its solution proposal and verification accuracy through online reinforcement learning. Experiments on mathematical reasoning benchmarks show that SPOC significantly improves performance. Notably, SPOC boosts the accuracy of Llama-3.1-8B and 70B Instruct models, achieving gains of 8.8% and 11.6% on MATH500, 10.0% and 20.0% on AMC23, and 3.3% and 6.7% on AIME24, respectively.
Reinforcement Learning from User Feedback
May 20, 2025As large language models (LLMs) are increasingly deployed in diverse user facing applications, aligning them with real user preferences becomes essential. Existing methods like Reinforcement Learning from Human Feedback (RLHF) rely on expert annotators trained on manually defined guidelines, whose judgments may not reflect the priorities of everyday users. We introduce Reinforcement Learning from User Feedback (RLUF), a framework for aligning LLMs directly to implicit signals from users in production. RLUF addresses key challenges of user feedback: user feedback is often binary (e.g., emoji reactions), sparse, and occasionally adversarial. We train a reward model, P[Love], to predict the likelihood that an LLM response will receive a Love Reaction, a lightweight form of positive user feedback, and integrate P[Love] into a multi-objective policy optimization framework alongside helpfulness and safety objectives. In large-scale experiments, we show that P[Love] is predictive of increased positive feedback and serves as a reliable offline evaluator of future user behavior. Policy optimization using P[Love] significantly raises observed positive-feedback rates, including a 28% increase in Love Reactions during live A/B tests. However, optimizing for positive reactions introduces reward hacking challenges, requiring careful balancing of objectives. By directly leveraging implicit signals from users, RLUF offers a path to aligning LLMs with real-world user preferences at scale.