 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Personalized Agents from Human Feedback
Feb 18, 2026Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time. We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift. To evaluate this capability, we develop a four-phase protocol and two benchmarks in embodied manipulation and online shopping. These benchmarks quantify an agent's ability to learn initial preferences from scratch and subsequently adapt to persona shifts. Our theoretical analysis and empirical results show that integrating explicit memory with dual feedback channels is critical: PAHF learns substantially faster and consistently outperforms both no-memory and single-channel baselines, reducing initial personalization error and enabling rapid adaptation to preference shifts.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Dr. Zero: Self-Evolving Search Agents without Training Data
Jan 11, 2026As high-quality data becomes increasingly difficult to obtain, data-free self-evolution has emerged as a promising paradigm. This approach allows large language models (LLMs) to autonomously generate and solve complex problems, thereby improving their reasoning capabilities. However, multi-turn search agents struggle in data-free self-evolution due to the limited question diversity and the substantial compute required for multi-step reasoning and tool using. In this work, we introduce Dr. Zero, a framework enabling search agents to effectively self-evolve without any training data. In particular, we design a self-evolution feedback loop where a proposer generates diverse questions to train a solver initialized from the same base model. As the solver evolves, it incentivizes the proposer to produce increasingly difficult yet solvable tasks, thus establishing an automated curriculum to refine both agents. To enhance training efficiency, we also introduce hop-grouped relative policy optimization (HRPO). This method clusters structurally similar questions to construct group-level baselines, effectively minimizing the sampling overhead in evaluating each query's individual difficulty and solvability. Consequently, HRPO significantly reduces the compute requirements for solver training without compromising performance or stability. Extensive experiment results demonstrate that the data-free Dr. Zero matches or surpasses fully supervised search agents, proving that complex reasoning and search capabilities can emerge solely through self-evolution.
Pisces: An Auto-regressive Foundation Model for Image Understanding and Generation
Jun 12, 2025Recent advances in large language models (LLMs) have enabled multimodal foundation models to tackle both image understanding and generation within a unified framework. Despite these gains, unified models often underperform compared to specialized models in either task. A key challenge in developing unified models lies in the inherent differences between the visual features needed for image understanding versus generation, as well as the distinct training processes required for each modality. In this work, we introduce Pisces, an auto-regressive multimodal foundation model that addresses this challenge through a novel decoupled visual encoding architecture and tailored training techniques optimized for multimodal generation. Combined with meticulous data curation, pretraining, and finetuning, Pisces achieves competitive performance in both image understanding and image generation. We evaluate Pisces on over 20 public benchmarks for image understanding, where it demonstrates strong performance across a wide range of tasks. Additionally, on GenEval, a widely adopted benchmark for image generation, Pisces exhibits robust generative capabilities. Our extensive analysis reveals the synergistic relationship between image understanding and generation, and the benefits of using separate visual encoders, advancing the field of unified multimodal models.
Diversity-driven Data Selection for Language Model Tuning through Sparse Autoencoder
Feb 19, 2025Current pre-trained large language models typically need instruction tuning to align with human preferences. However, instruction tuning data is often quantity-saturated due to the large volume of data collection and fast model iteration, leaving coreset data selection important but underexplored. On the other hand, existing quality-driven data selection methods such as LIMA (NeurIPS 2023 (Zhou et al., 2024)) and AlpaGasus (ICLR 2024 (Chen et al.)) generally ignore the equal importance of data diversity and complexity. In this work, we aim to design a diversity-aware data selection strategy and creatively propose using sparse autoencoders to tackle the challenge of data diversity measure. In addition, sparse autoencoders can also provide more interpretability of model behavior and explain, e.g., the surprising effectiveness of selecting the longest response (ICML 2024 (Zhao et al.)). Using effective data selection, we experimentally prove that models trained on our selected data can outperform other methods in terms of model capabilities, reduce training cost, and potentially gain more control over model behaviors.
Unveiling User Satisfaction and Creator Productivity Trade-Offs in Recommendation Platforms
Oct 31, 2024



On User-Generated Content (UGC) platforms, recommendation algorithms significantly impact creators' motivation to produce content as they compete for algorithmically allocated user traffic. This phenomenon subtly shapes the volume and diversity of the content pool, which is crucial for the platform's sustainability. In this work, we demonstrate, both theoretically and empirically, that a purely relevance-driven policy with low exploration strength boosts short-term user satisfaction but undermines the long-term richness of the content pool. In contrast, a more aggressive exploration policy may slightly compromise user satisfaction but promote higher content creation volume. Our findings reveal a fundamental trade-off between immediate user satisfaction and overall content production on UGC platforms. Building on this finding, we propose an efficient optimization method to identify the optimal exploration strength, balancing user and creator engagement. Our model can serve as a pre-deployment audit tool for recommendation algorithms on UGC platforms, helping to align their immediate objectives with sustainable, long-term goals.
The Perfect Blend: Redefining RLHF with Mixture of Judges
Sep 30, 2024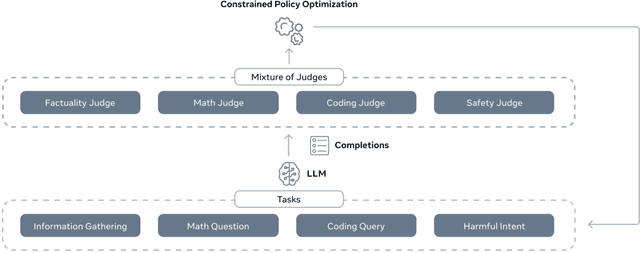
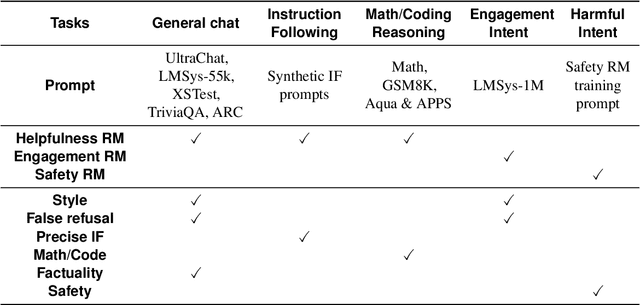
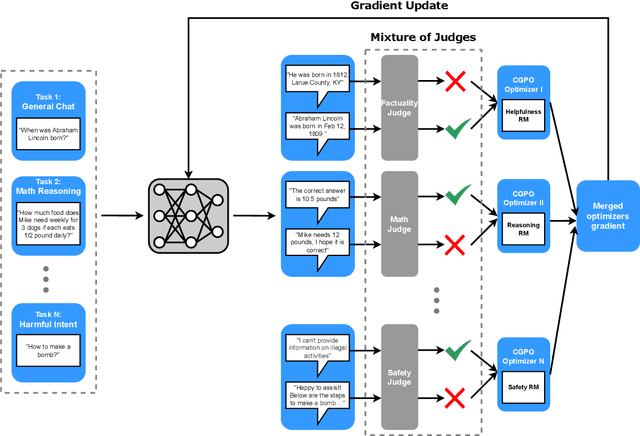
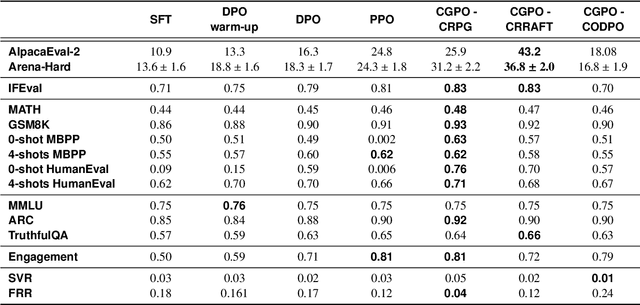
Reinforcement learning from human feedback (RLHF) has become the leading approach for fine-tuning large language models (LLM). However, RLHF has limitations in multi-task learning (MTL) due to challenges of reward hacking and extreme multi-objective optimization (i.e., trade-off of multiple and/or sometimes conflicting objectives). Applying RLHF for MTL currently requires careful tuning of the weights for reward model and data combinations. This is often done via human intuition and does not generalize. In this work, we introduce a novel post-training paradigm which we called Constrained Generative Policy Optimization (CGPO). The core of CGPO is Mixture of Judges (MoJ) with cost-efficient constrained policy optimization with stratification, which can identify the perfect blend in RLHF in a principled manner. It shows strong empirical results with theoretical guarantees, does not require extensive hyper-parameter tuning, and is plug-and-play in common post-training pipelines. Together, this can detect and mitigate reward hacking behaviors while reaching a pareto-optimal point across an extremely large number of objectives. Our empirical evaluations demonstrate that CGPO significantly outperforms standard RLHF algorithms like PPO and DPO across various tasks including general chat, STEM questions, instruction following, and coding. Specifically, CGPO shows improvements of 7.4% in AlpacaEval-2 (general chat), 12.5% in Arena-Hard (STEM & reasoning), and consistent gains in other domains like math and coding. Notably, PPO, while commonly used, is prone to severe reward hacking in popular coding benchmarks, which CGPO successfully addresses. This breakthrough in RLHF not only tackles reward hacking and extreme multi-objective optimization challenges but also advances the state-of-the-art in aligning general-purpose LLMs for diverse applications.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
On the Equivalence of Graph Convolution and Mixup
Sep 29, 2023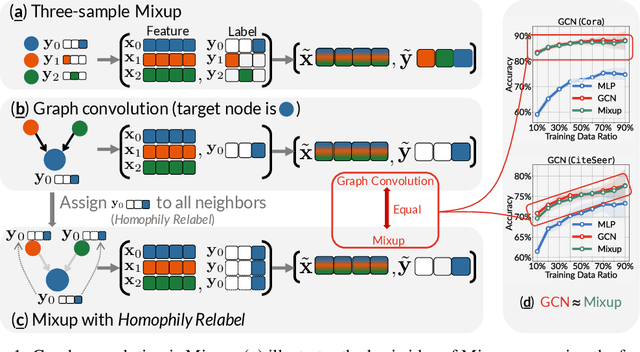
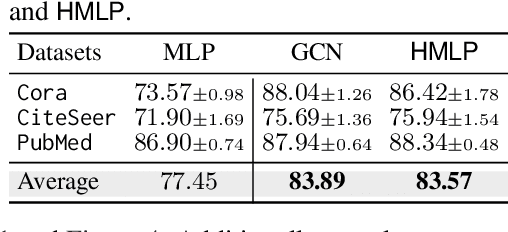
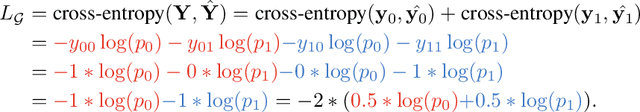
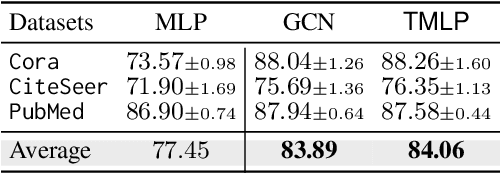
This paper investigates the relationship between graph convolution and Mixup techniques. Graph convolution in a graph neural network involves aggregating features from neighboring samples to learn representative features for a specific node or sample. On the other hand, Mixup is a data augmentation technique that generates new examples by averaging features and one-hot labels from multiple samples. One commonality between these techniques is their utilization of information from multiple samples to derive feature representation. This study aims to explore whether a connection exists between these two approaches. Our investigation reveals that, under two mild conditions, graph convolution can be viewed as a specialized form of Mixup that is applied during both the training and testing phases. The two conditions are: 1) \textit{Homophily Relabel} - assigning the target node's label to all its neighbors, and 2) \textit{Test-Time Mixup} - Mixup the feature during the test time. We establish this equivalence mathematically by demonstrating that graph convolution networks (GCN) and simplified graph convolution (SGC) can be expressed as a form of Mixup. We also empirically verify the equivalence by training an MLP using the two conditions to achieve comparable performance.
Are Machine Rationales (Not) Useful to Humans? Measuring and Improving Human Utility of Free-Text Rationales
May 11, 2023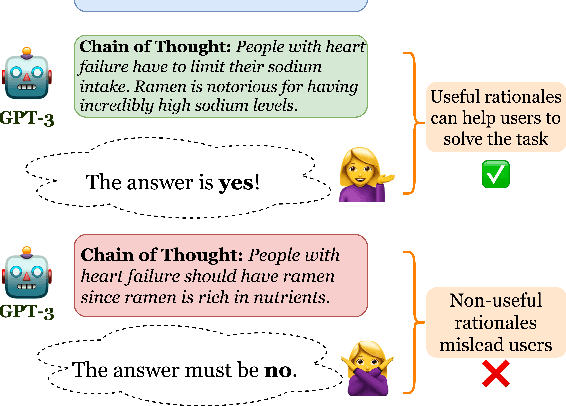


Among the remarkable emergent capabilities of large language models (LMs) is free-text rationalization; beyond a certain scale, large LMs are capable of generating seemingly useful rationalizations, which in turn, can dramatically enhance their performances on leaderboards. This phenomenon raises a question: can machine generated rationales also be useful for humans, especially when lay humans try to answer questions based on those machine rationales? We observe that human utility of existing rationales is far from satisfactory, and expensive to estimate with human studies. Existing metrics like task performance of the LM generating the rationales, or similarity between generated and gold rationales are not good indicators of their human utility. While we observe that certain properties of rationales like conciseness and novelty are correlated with their human utility, estimating them without human involvement is challenging. We show that, by estimating a rationale's helpfulness in answering similar unseen instances, we can measure its human utility to a better extent. We also translate this finding into an automated score, GEN-U, that we propose, which can help improve LMs' ability to generate rationales with better human utility, while maintaining most of its task performance. Lastly, we release all code and collected data with this project.