 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Machine Rationales (Not) Useful to Humans? Measuring and Improving Human Utility of Free-Text Rationales
Paper and Code
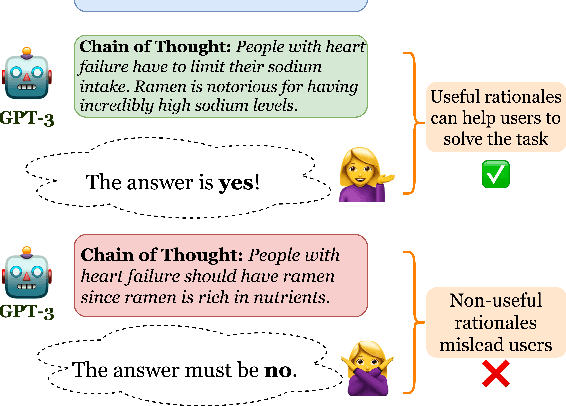


Among the remarkable emergent capabilities of large language models (LMs) is free-text rationalization; beyond a certain scale, large LMs are capable of generating seemingly useful rationalizations, which in turn, can dramatically enhance their performances on leaderboards. This phenomenon raises a question: can machine generated rationales also be useful for humans, especially when lay humans try to answer questions based on those machine rationales? We observe that human utility of existing rationales is far from satisfactory, and expensive to estimate with human studies. Existing metrics like task performance of the LM generating the rationales, or similarity between generated and gold rationales are not good indicators of their human utility. While we observe that certain properties of rationales like conciseness and novelty are correlated with their human utility, estimating them without human involvement is challenging. We show that, by estimating a rationale's helpfulness in answering similar unseen instances, we can measure its human utility to a better extent. We also translate this finding into an automated score, GEN-U, that we propose, which can help improve LMs' ability to generate rationales with better human utility, while maintaining most of its task performance. Lastly, we release all code and collected data with this project.