 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Natural Language Environment: Understanding Seamless Natural-Language-Based Human-Multi-Robot Interactions
Jan 19, 2026As multiple robots are expected to coexist in future households, natural language is increasingly envisioned as a primary medium for human-robot and robot-robot communication. This paper introduces the concept of a Natural Language Environment (NLE), defined as an interaction space in which humans and multiple heterogeneous robots coordinate primarily through natural language. Rather than proposing a deployable system, this work aims to explore the design space of such environments. We first synthesize prior work on language-based human-robot interaction to derive a preliminary design space for NLEs. We then conduct a role-playing study in virtual reality to investigate how people conceptualize, negotiate, and coordinate human-multi-robot interactions within this imagined environment. Based on qualitative and quantitative analysis, we refine the preliminary design space and derive design implications that highlight key tensions and opportunities around task coordination dominance, robot autonomy, and robot personality in Natural Language Environments.
LongVideoAgent: Multi-Agent Reasoning with Long Videos
Dec 23, 2025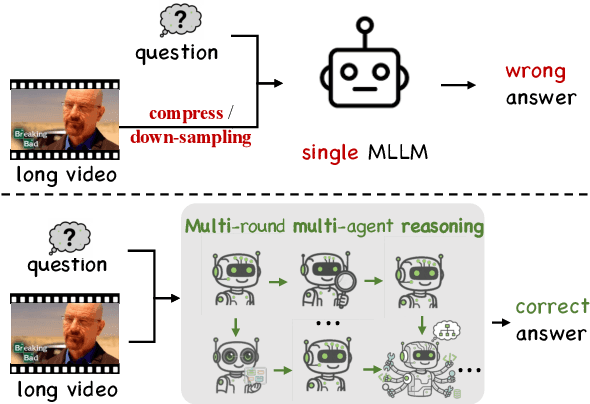


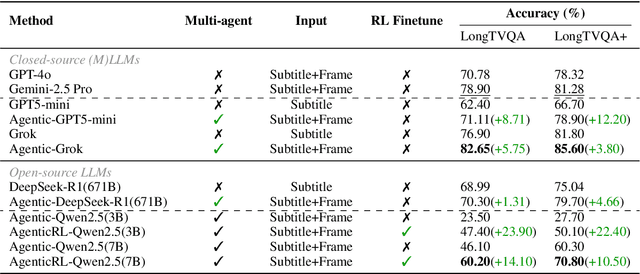
Recent advances in multimodal LLMs and systems that use tools for long-video QA point to the promise of reasoning over hour-long episodes. However, many methods still compress content into lossy summaries or rely on limited toolsets, weakening temporal grounding and missing fine-grained cues. We propose a multi-agent framework in which a master LLM coordinates a grounding agent to localize question-relevant segments and a vision agent to extract targeted textual observations. The master agent plans with a step limit, and is trained with reinforcement learning to encourage concise, correct, and efficient multi-agent cooperation. This design helps the master agent focus on relevant clips via grounding, complements subtitles with visual detail, and yields interpretable trajectories. On our proposed LongTVQA and LongTVQA+ which are episode-level datasets aggregated from TVQA/TVQA+, our multi-agent system significantly outperforms strong non-agent baselines. Experiments also show reinforcement learning further strengthens reasoning and planning for the trained agent. Code and data will be shared at https://longvideoagent.github.io/.
Generative AI for Misalignment-Resistant Virtual Staining to Accelerate Histopathology Workflows
Sep 17, 2025Accurate histopathological diagnosis often requires multiple differently stained tissue sections, a process that is time-consuming, labor-intensive, and environmentally taxing due to the use of multiple chemical stains. Recently, virtual staining has emerged as a promising alternative that is faster, tissue-conserving, and environmentally friendly. However, existing virtual staining methods face significant challenges in clinical applications, primarily due to their reliance on well-aligned paired data. Obtaining such data is inherently difficult because chemical staining processes can distort tissue structures, and a single tissue section cannot undergo multiple staining procedures without damage or loss of information. As a result, most available virtual staining datasets are either unpaired or roughly paired, making it difficult for existing methods to achieve accurate pixel-level supervision. To address this challenge, we propose a robust virtual staining framework featuring cascaded registration mechanisms to resolve spatial mismatches between generated outputs and their corresponding ground truth. Experimental results demonstrate that our method significantly outperforms state-of-the-art models across five datasets, achieving an average improvement of 3.2% on internal datasets and 10.1% on external datasets. Moreover, in datasets with substantial misalignment, our approach achieves a remarkable 23.8% improvement in peak signal-to-noise ratio compared to baseline models. The exceptional robustness of the proposed method across diverse datasets simplifies the data acquisition process for virtual staining and offers new insights for advancing its development.
A Segmentation Framework for Accurate Diagnosis of Amyloid Positivity without Structural Images
Jul 30, 2025



This study proposes a deep learning-based framework for automated segmentation of brain regions and classification of amyloid positivity using positron emission tomography (PET) images alone, without the need for structural MRI or CT. A 3D U-Net architecture with four layers of depth was trained and validated on a dataset of 200 F18-florbetapir amyloid-PET scans, with an 130/20/50 train/validation/test split. Segmentation performance was evaluated using Dice similarity coefficients across 30 brain regions, with scores ranging from 0.45 to 0.88, demonstrating high anatomical accuracy, particularly in subcortical structures. Quantitative fidelity of PET uptake within clinically relevant regions. Precuneus, prefrontal cortex, gyrus rectus, and lateral temporal cortex was assessed using normalized root mean square error, achieving values as low as 0.0011. Furthermore, the model achieved a classification accuracy of 0.98 for amyloid positivity based on regional uptake quantification, with an area under the ROC curve (AUC) of 0.99. These results highlight the model's potential for integration into PET only diagnostic pipelines, particularly in settings where structural imaging is not available. This approach reduces dependence on coregistration and manual delineation, enabling scalable, reliable, and reproducible analysis in clinical and research applications. Future work will focus on clinical validation and extension to diverse PET tracers including C11 PiB and other F18 labeled compounds.
A Versatile Pathology Co-pilot via Reasoning Enhanced Multimodal Large Language Model
Jul 23, 2025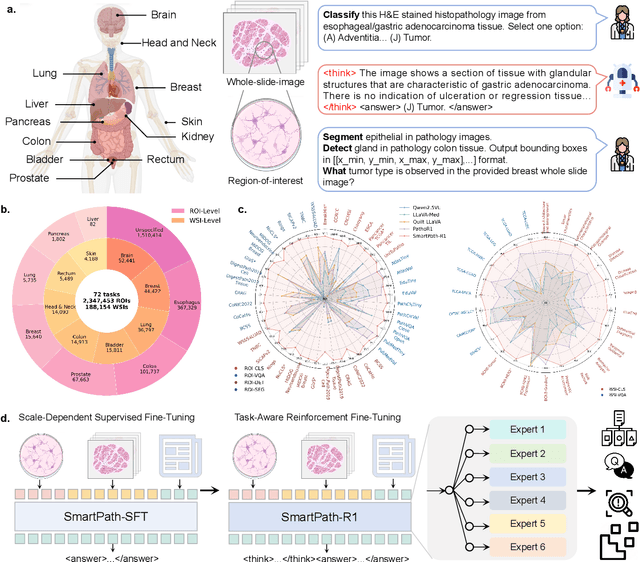
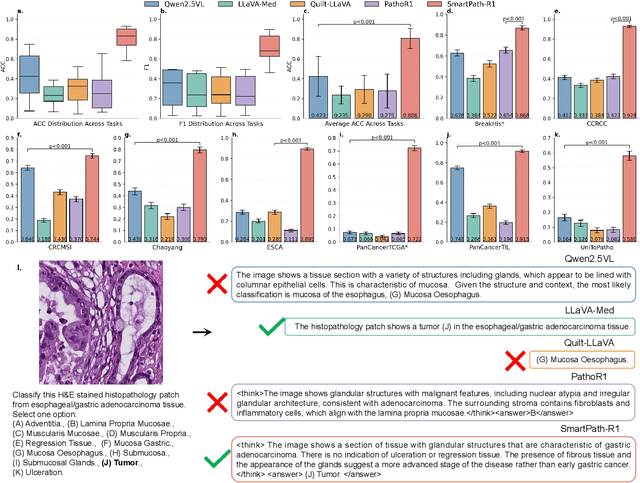
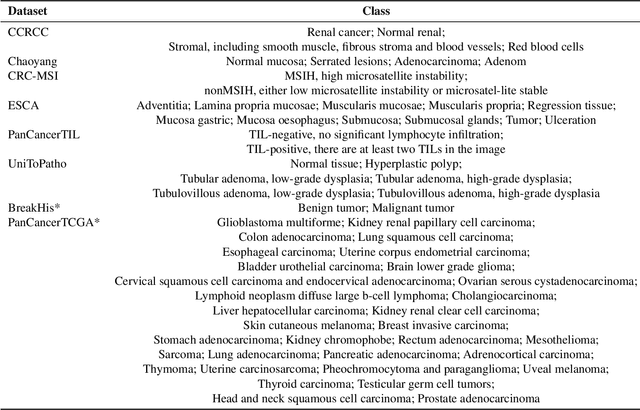
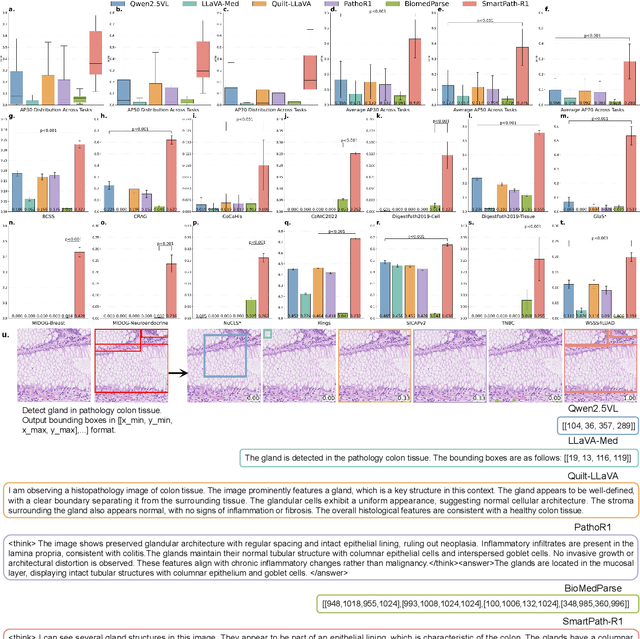
Multimodal large language models (MLLMs) have emerged as powerful tools for computational pathology, offering unprecedented opportunities to integrate pathological images with language context for comprehensive diagnostic analysis. These models hold particular promise for automating complex tasks that traditionally require expert interpretation of pathologists. However, current MLLM approaches in pathology demonstrate significantly constrained reasoning capabilities, primarily due to their reliance on expensive chain-of-thought annotations. Additionally, existing methods remain limited to simplex application of visual question answering (VQA) at region-of-interest (ROI) level, failing to address the full spectrum of diagnostic needs such as ROI classification, detection, segmentation, whole-slide-image (WSI) classification and VQA in clinical practice. In this study, we present SmartPath-R1, a versatile MLLM capable of simultaneously addressing both ROI-level and WSI-level tasks while demonstrating robust pathological reasoning capability. Our framework combines scale-dependent supervised fine-tuning and task-aware reinforcement fine-tuning, which circumvents the requirement for chain-of-thought supervision by leveraging the intrinsic knowledge within MLLM. Furthermore, SmartPath-R1 integrates multiscale and multitask analysis through a mixture-of-experts mechanism, enabling dynamic processing for diverse tasks. We curate a large-scale dataset comprising 2.3M ROI samples and 188K WSI samples for training and evaluation. Extensive experiments across 72 tasks validate the effectiveness and superiority of the proposed approach. This work represents a significant step toward developing versatile, reasoning-enhanced AI systems for precision pathology.
Discovering Pathology Rationale and Token Allocation for Efficient Multimodal Pathology Reasoning
May 21, 2025Multimodal pathological image understanding has garnered widespread interest due to its potential to improve diagnostic accuracy and enable personalized treatment through integrated visual and textual data. However, existing methods exhibit limited reasoning capabilities, which hamper their ability to handle complex diagnostic scenarios. Additionally, the enormous size of pathological images leads to severe computational burdens, further restricting their practical deployment. To address these limitations, we introduce a novel bilateral reinforcement learning framework comprising two synergistic branches. One reinforcement branch enhances the reasoning capability by enabling the model to learn task-specific decision processes, i.e., pathology rationales, directly from labels without explicit reasoning supervision. While the other branch dynamically allocates a tailored number of tokens to different images based on both their visual content and task context, thereby optimizing computational efficiency. We apply our method to various pathological tasks such as visual question answering, cancer subtyping, and lesion detection. Extensive experiments show an average +41.7 absolute performance improvement with 70.3% lower inference costs over the base models, achieving both reasoning accuracy and computational efficiency.
Fine-Grained ECG-Text Contrastive Learning via Waveform Understanding Enhancement
May 17, 2025Electrocardiograms (ECGs) are essential for diagnosing cardiovascular diseases. While previous ECG-text contrastive learning methods have shown promising results, they often overlook the incompleteness of the reports. Given an ECG, the report is generated by first identifying key waveform features and then inferring the final diagnosis through these features. Despite their importance, these waveform features are often not recorded in the report as intermediate results. Aligning ECGs with such incomplete reports impedes the model's ability to capture the ECG's waveform features and limits its understanding of diagnostic reasoning based on those features. To address this, we propose FG-CLEP (Fine-Grained Contrastive Language ECG Pre-training), which aims to recover these waveform features from incomplete reports with the help of large language models (LLMs), under the challenges of hallucinations and the non-bijective relationship between waveform features and diagnoses. Additionally, considering the frequent false negatives due to the prevalence of common diagnoses in ECGs, we introduce a semantic similarity matrix to guide contrastive learning. Furthermore, we adopt a sigmoid-based loss function to accommodate the multi-label nature of ECG-related tasks. Experiments on six datasets demonstrate that FG-CLEP outperforms state-of-the-art methods in both zero-shot prediction and linear probing across these datasets.
Improving Random Forests by Smoothing
May 11, 2025



Gaussian process regression is a popular model in the small data regime due to its sound uncertainty quantification and the exploitation of the smoothness of the regression function that is encountered in a wide range of practical problems. However, Gaussian processes perform sub-optimally when the degree of smoothness is non-homogeneous across the input domain. Random forest regression partially addresses this issue by providing local basis functions of variable support set sizes that are chosen in a data-driven way. However, they do so at the expense of forgoing any degree of smoothness, which often results in poor performance in the small data regime. Here, we aim to combine the advantages of both models by applying a kernel-based smoothing mechanism to a learned random forest or any other piecewise constant prediction function. As we demonstrate empirically, the resulting model consistently improves the predictive performance of the underlying random forests and, in almost all test cases, also improves the log loss of the usual uncertainty quantification based on inter-tree variance. The latter advantage can be attributed to the ability of the smoothing model to take into account the uncertainty over the exact tree-splitting locations.
Bridge the Gap: From Weak to Full Supervision for Temporal Action Localization with PseudoFormer
Apr 21, 2025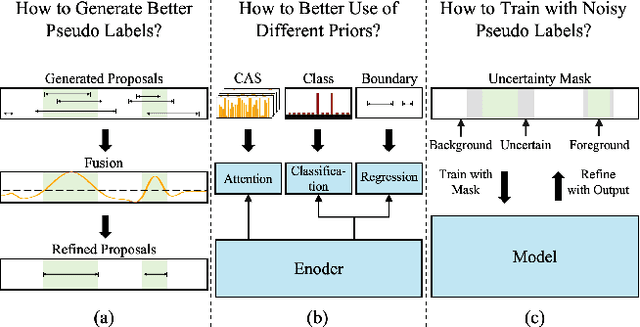
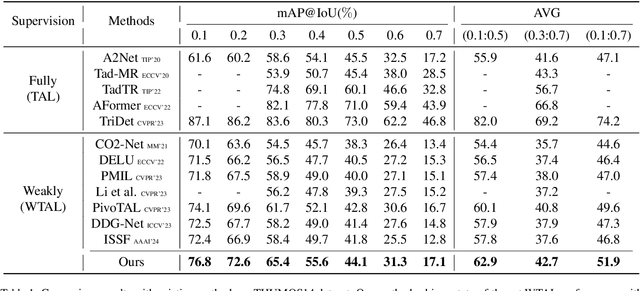
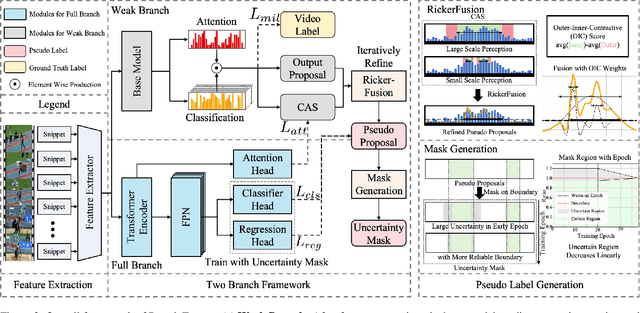
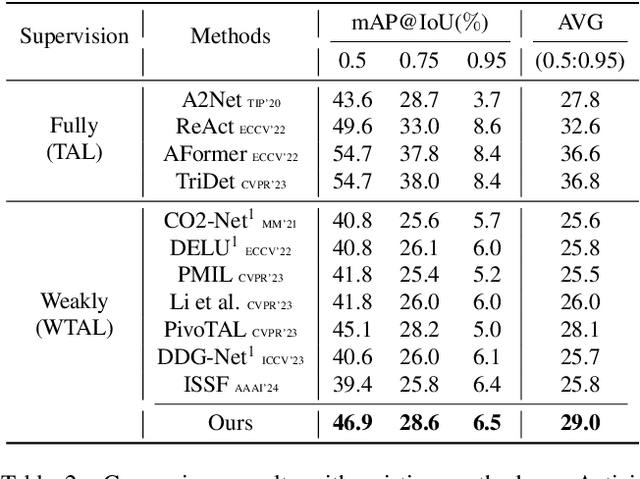
Weakly-supervised Temporal Action Localization (WTAL) has achieved notable success but still suffers from a lack of temporal annotations, leading to a performance and framework gap compared with fully-supervised methods. While recent approaches employ pseudo labels for training, three key challenges: generating high-quality pseudo labels, making full use of different priors, and optimizing training methods with noisy labels remain unresolved. Due to these perspectives, we propose PseudoFormer, a novel two-branch framework that bridges the gap between weakly and fully-supervised Temporal Action Localization (TAL). We first introduce RickerFusion, which maps all predicted action proposals to a global shared space to generate pseudo labels with better quality. Subsequently, we leverage both snippet-level and proposal-level labels with different priors from the weak branch to train the regression-based model in the full branch. Finally, the uncertainty mask and iterative refinement mechanism are applied for training with noisy pseudo labels. PseudoFormer achieves state-of-the-art WTAL results on the two commonly used benchmarks, THUMOS14 and ActivityNet1.3. Besides, extensive ablation studies demonstrate the contribution of each component of our method.
Can LLMs Grasp Implicit Cultural Values? Benchmarking LLMs' Metacognitive Cultural Intelligence with CQ-Bench
Apr 01, 2025Cultural Intelligence (CQ) refers to the ability to understand unfamiliar cultural contexts-a crucial skill for large language models (LLMs) to effectively engage with globally diverse users. While existing research often focuses on explicitly stated cultural norms, such approaches fail to capture the subtle, implicit values that underlie real-world conversations. To address this gap, we introduce CQ-Bench, a benchmark specifically designed to assess LLMs' capability to infer implicit cultural values from natural conversational contexts. We generate a multi-character conversation-based stories dataset using values from the World Value Survey and GlobalOpinions datasets, with topics including ethical, religious, social, and political. Our dataset construction pipeline includes rigorous validation procedures-incorporation, consistency, and implicitness checks-using GPT-4o, with 98.2% human-model agreement in the final validation. Our benchmark consists of three tasks of increasing complexity: attitude detection, value selection, and value extraction. We find that while o1 and Deepseek-R1 models reach human-level performance in value selection (0.809 and 0.814), they still fall short in nuanced attitude detection, with F1 scores of 0.622 and 0.635, respectively. In the value extraction task, GPT-4o-mini and o3-mini score 0.602 and 0.598, highlighting the difficulty of open-ended cultural reasoning. Notably, fine-tuning smaller models (e.g., LLaMA-3.2-3B) on only 500 culturally rich examples improves performance by over 10%, even outperforming stronger baselines (o3-mini) in some cases. Using CQ-Bench, we provide insights into the current challenges in LLMs' CQ research and suggest practical pathways for enhancing LLMs' cross-cultural reasoning abilities.