 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Human Body Reshaping with Adaptive Affinity-Graph Network
Apr 22, 2024Given a source portrait, the automatic human body reshaping task aims at editing it to an aesthetic body shape. As the technology has been widely used in media, several methods have been proposed mainly focusing on generating optical flow to warp the body shape. However, those previous works only consider the local transformation of different body parts (arms, torso, and legs), ignoring the global affinity, and limiting the capacity to ensure consistency and quality across the entire body. In this paper, we propose a novel Adaptive Affinity-Graph Network (AAGN), which extracts the global affinity between different body parts to enhance the quality of the generated optical flow. Specifically, our AAGN primarily introduces the following designs: (1) we propose an Adaptive Affinity-Graph (AAG) Block that leverages the characteristic of a fully connected graph. AAG represents different body parts as nodes in an adaptive fully connected graph and captures all the affinities between nodes to obtain a global affinity map. The design could better improve the consistency between body parts. (2) Besides, for high-frequency details are crucial for photo aesthetics, a Body Shape Discriminator (BSD) is designed to extract information from both high-frequency and spatial domain. Particularly, an SRM filter is utilized to extract high-frequency details, which are combined with spatial features as input to the BSD. With this design, BSD guides the Flow Generator (FG) to pay attention to various fine details rather than rigid pixel-level fitting. Extensive experiments conducted on the BR-5K dataset demonstrate that our framework significantly enhances the aesthetic appeal of reshaped photos, marginally surpassing all previous work to achieve state-of-the-art in all evaluation metrics.
STAT: Towards Generalizable Temporal Action Localization
Apr 20, 2024



Weakly-supervised temporal action localization (WTAL) aims to recognize and localize action instances with only video-level labels. Despite the significant progress, existing methods suffer from severe performance degradation when transferring to different distributions and thus may hardly adapt to real-world scenarios . To address this problem, we propose the Generalizable Temporal Action Localization task (GTAL), which focuses on improving the generalizability of action localization methods. We observed that the performance decline can be primarily attributed to the lack of generalizability to different action scales. To address this problem, we propose STAT (Self-supervised Temporal Adaptive Teacher), which leverages a teacher-student structure for iterative refinement. Our STAT features a refinement module and an alignment module. The former iteratively refines the model's output by leveraging contextual information and helps adapt to the target scale. The latter improves the refinement process by promoting a consensus between student and teacher models. We conduct extensive experiments on three datasets, THUMOS14, ActivityNet1.2, and HACS, and the results show that our method significantly improves the Baseline methods under the cross-distribution evaluation setting, even approaching the same-distribution evaluation performance.
Simultaneous Detection and Interaction Reasoning for Object-Centric Action Recognition
Apr 18, 2024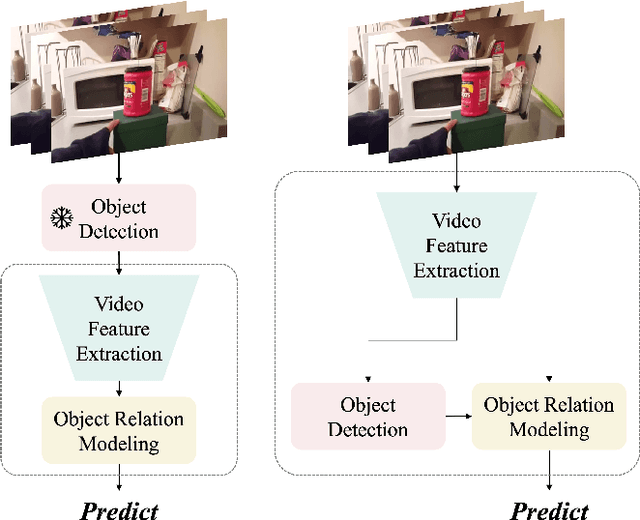
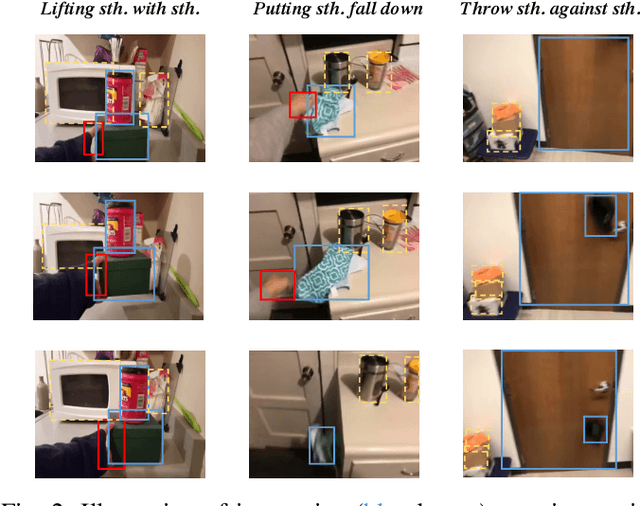
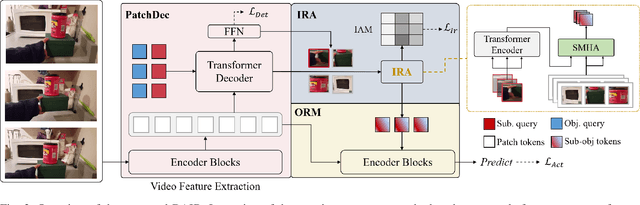

The interactions between human and objects are important for recognizing object-centric actions. Existing methods usually adopt a two-stage pipeline, where object proposals are first detected using a pretrained detector, and then are fed to an action recognition model for extracting video features and learning the object relations for action recognition. However, since the action prior is unknown in the object detection stage, important objects could be easily overlooked, leading to inferior action recognition performance. In this paper, we propose an end-to-end object-centric action recognition framework that simultaneously performs Detection And Interaction Reasoning in one stage. Particularly, after extracting video features with a base network, we create three modules for concurrent object detection and interaction reasoning. First, a Patch-based Object Decoder generates proposals from video patch tokens. Then, an Interactive Object Refining and Aggregation identifies important objects for action recognition, adjusts proposal scores based on position and appearance, and aggregates object-level info into a global video representation. Lastly, an Object Relation Modeling module encodes object relations. These three modules together with the video feature extractor can be trained jointly in an end-to-end fashion, thus avoiding the heavy reliance on an off-the-shelf object detector, and reducing the multi-stage training burden. We conduct experiments on two datasets, Something-Else and Ikea-Assembly, to evaluate the performance of our proposed approach on conventional, compositional, and few-shot action recognition tasks. Through in-depth experimental analysis, we show the crucial role of interactive objects in learning for action recognition, and we can outperform state-of-the-art methods on both datasets.