 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Look Spatial Reasoning for Dense Surgical Instrument Counting
Feb 11, 2026Accurate counting of surgical instruments in Operating Rooms (OR) is a critical prerequisite for ensuring patient safety during surgery. Despite recent progress of large visual-language models and agentic AI, accurately counting such instruments remains highly challenging, particularly in dense scenarios where instruments are tightly clustered. To address this problem, we introduce Chain-of-Look, a novel visual reasoning framework that mimics the sequential human counting process by enforcing a structured visual chain, rather than relying on classic object detection which is unordered. This visual chain guides the model to count along a coherent spatial trajectory, improving accuracy in complex scenes. To further enforce the physical plausibility of the visual chain, we introduce the neighboring loss function, which explicitly models the spatial constraints inherent to densely packed surgical instruments. We also present SurgCount-HD, a new dataset comprising 1,464 high-density surgical instrument images. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches for counting (e.g., CountGD, REC) as well as Multimodality Large Language Models (e.g., Qwen, ChatGPT) in the challenging task of dense surgical instrument counting.
Language-Guided Transformer Tokenizer for Human Motion Generation
Feb 09, 2026In this paper, we focus on motion discrete tokenization, which converts raw motion into compact discrete tokens--a process proven crucial for efficient motion generation. In this paradigm, increasing the number of tokens is a common approach to improving motion reconstruction quality, but more tokens make it more difficult for generative models to learn. To maintain high reconstruction quality while reducing generation complexity, we propose leveraging language to achieve efficient motion tokenization, which we term Language-Guided Tokenization (LG-Tok). LG-Tok aligns natural language with motion at the tokenization stage, yielding compact, high-level semantic representations. This approach not only strengthens both tokenization and detokenization but also simplifies the learning of generative models. Furthermore, existing tokenizers predominantly adopt convolutional architectures, whose local receptive fields struggle to support global language guidance. To this end, we propose a Transformer-based Tokenizer that leverages attention mechanisms to enable effective alignment between language and motion. Additionally, we design a language-drop scheme, in which language conditions are randomly removed during training, enabling the detokenizer to support language-free guidance during generation. On the HumanML3D and Motion-X generation benchmarks, LG-Tok achieves Top-1 scores of 0.542 and 0.582, outperforming state-of-the-art methods (MARDM: 0.500 and 0.528), and with FID scores of 0.057 and 0.088, respectively, versus 0.114 and 0.147. LG-Tok-mini uses only half the tokens while maintaining competitive performance (Top-1: 0.521/0.588, FID: 0.085/0.071), validating the efficiency of our semantic representations.
CamReasoner: Reinforcing Camera Movement Understanding via Structured Spatial Reasoning
Jan 30, 2026Understanding camera dynamics is a fundamental pillar of video spatial intelligence. However, existing multimodal models predominantly treat this task as a black-box classification, often confusing physically distinct motions by relying on superficial visual patterns rather than geometric cues. We present CamReasoner, a framework that reformulates camera movement understanding as a structured inference process to bridge the gap between perception and cinematic logic. Our approach centers on the Observation-Thinking-Answer (O-T-A) paradigm, which compels the model to decode spatio-temporal cues such as trajectories and view frustums within an explicit reasoning block. To instill this capability, we construct a Large-scale Inference Trajectory Suite comprising 18k SFT reasoning chains and 38k RL feedback samples. Notably, we are the first to employ RL for logical alignment in this domain, ensuring motion inferences are grounded in physical geometry rather than contextual guesswork. By applying Reinforcement Learning to the Observation-Think-Answer (O-T-A) reasoning paradigm, CamReasoner effectively suppresses hallucinations and achieves state-of-the-art performance across multiple benchmarks.
PoseMoE: Mixture-of-Experts Network for Monocular 3D Human Pose Estimation
Dec 18, 2025The lifting-based methods have dominated monocular 3D human pose estimation by leveraging detected 2D poses as intermediate representations. The 2D component of the final 3D human pose benefits from the detected 2D poses, whereas its depth counterpart must be estimated from scratch. The lifting-based methods encode the detected 2D pose and unknown depth in an entangled feature space, explicitly introducing depth uncertainty to the detected 2D pose, thereby limiting overall estimation accuracy. This work reveals that the depth representation is pivotal for the estimation process. Specifically, when depth is in an initial, completely unknown state, jointly encoding depth features with 2D pose features is detrimental to the estimation process. In contrast, when depth is initially refined to a more dependable state via network-based estimation, encoding it together with 2D pose information is beneficial. To address this limitation, we present a Mixture-of-Experts network for monocular 3D pose estimation named PoseMoE. Our approach introduces: (1) A mixture-of-experts network where specialized expert modules refine the well-detected 2D pose features and learn the depth features. This mixture-of-experts design disentangles the feature encoding process for 2D pose and depth, therefore reducing the explicit influence of uncertain depth features on 2D pose features. (2) A cross-expert knowledge aggregation module is proposed to aggregate cross-expert spatio-temporal contextual information. This step enhances features through bidirectional mapping between 2D pose and depth. Extensive experiments show that our proposed PoseMoE outperforms the conventional lifting-based methods on three widely used datasets: Human3.6M, MPI-INF-3DHP, and 3DPW.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025


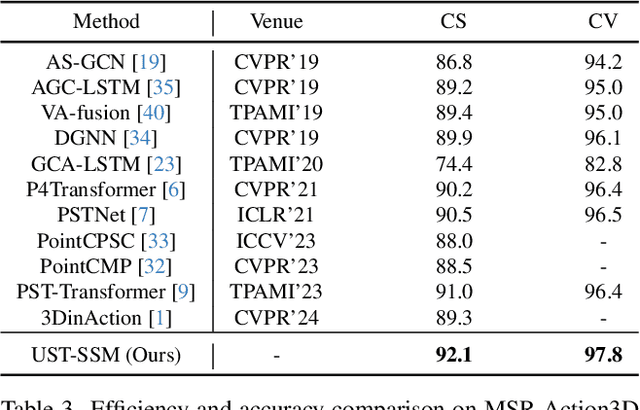
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.
PP-Motion: Physical-Perceptual Fidelity Evaluation for Human Motion Generation
Aug 11, 2025Human motion generation has found widespread applications in AR/VR, film, sports, and medical rehabilitation, offering a cost-effective alternative to traditional motion capture systems. However, evaluating the fidelity of such generated motions is a crucial, multifaceted task. Although previous approaches have attempted at motion fidelity evaluation using human perception or physical constraints, there remains an inherent gap between human-perceived fidelity and physical feasibility. Moreover, the subjective and coarse binary labeling of human perception further undermines the development of a robust data-driven metric. We address these issues by introducing a physical labeling method. This method evaluates motion fidelity by calculating the minimum modifications needed for a motion to align with physical laws. With this approach, we are able to produce fine-grained, continuous physical alignment annotations that serve as objective ground truth. With these annotations, we propose PP-Motion, a novel data-driven metric to evaluate both physical and perceptual fidelity of human motion. To effectively capture underlying physical priors, we employ Pearson's correlation loss for the training of our metric. Additionally, by incorporating a human-based perceptual fidelity loss, our metric can capture fidelity that simultaneously considers both human perception and physical alignment. Experimental results demonstrate that our metric, PP-Motion, not only aligns with physical laws but also aligns better with human perception of motion fidelity than previous work.
Recognizing Actions from Robotic View for Natural Human-Robot Interaction
Jul 30, 2025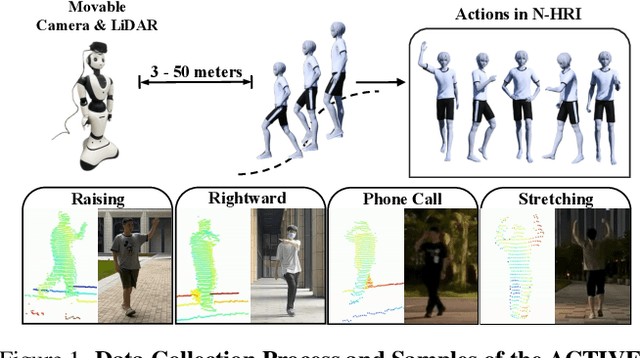
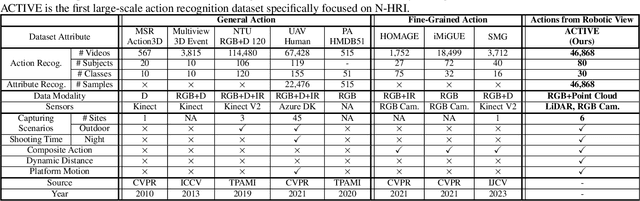

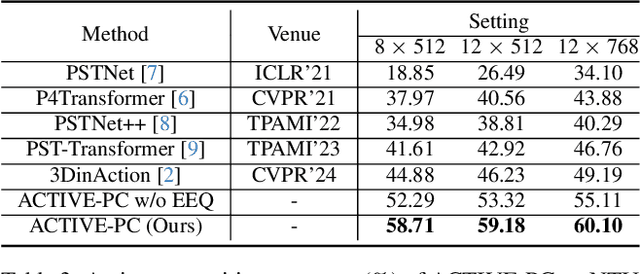
Natural Human-Robot Interaction (N-HRI) requires robots to recognize human actions at varying distances and states, regardless of whether the robot itself is in motion or stationary. This setup is more flexible and practical than conventional human action recognition tasks. However, existing benchmarks designed for traditional action recognition fail to address the unique complexities in N-HRI due to limited data, modalities, task categories, and diversity of subjects and environments. To address these challenges, we introduce ACTIVE (Action from Robotic View), a large-scale dataset tailored specifically for perception-centric robotic views prevalent in mobile service robots. ACTIVE comprises 30 composite action categories, 80 participants, and 46,868 annotated video instances, covering both RGB and point cloud modalities. Participants performed various human actions in diverse environments at distances ranging from 3m to 50m, while the camera platform was also mobile, simulating real-world scenarios of robot perception with varying camera heights due to uneven ground. This comprehensive and challenging benchmark aims to advance action and attribute recognition research in N-HRI. Furthermore, we propose ACTIVE-PC, a method that accurately perceives human actions at long distances using Multilevel Neighborhood Sampling, Layered Recognizers, Elastic Ellipse Query, and precise decoupling of kinematic interference from human actions. Experimental results demonstrate the effectiveness of ACTIVE-PC. Our code is available at: https://github.com/wangzy01/ACTIVE-Action-from-Robotic-View.
$A^2R^2$: Advancing Img2LaTeX Conversion via Visual Reasoning with Attention-Guided Refinement
Jul 28, 2025Img2LaTeX is a practically significant task that involves converting mathematical expressions or tabular data from images into LaTeX code. In recent years, vision-language models (VLMs) have demonstrated strong performance across a variety of visual understanding tasks, owing to their generalization capabilities. While some studies have explored the use of VLMs for the Img2LaTeX task, their performance often falls short of expectations. Empirically, VLMs sometimes struggle with fine-grained visual elements, leading to inaccurate LaTeX predictions. To address this challenge, we propose $A^2R^2$: Advancing Img2LaTeX Conversion via Visual Reasoning with Attention-Guided Refinement, a framework that effectively integrates attention localization and iterative refinement within a visual reasoning framework, enabling VLMs to perform self-correction and progressively improve prediction quality. For effective evaluation, we introduce a new dataset, Img2LaTex-Hard-1K, consisting of 1,100 carefully curated and challenging examples designed to rigorously evaluate the capabilities of VLMs within this task domain. Extensive experimental results demonstrate that: (1) $A^2R^2$ significantly improves model performance across six evaluation metrics spanning both textual and visual levels, consistently outperforming other baseline methods; (2) Increasing the number of inference rounds yields notable performance gains, underscoring the potential of $A^2R^2$ in test-time scaling scenarios; (3) Ablation studies and human evaluations validate the practical effectiveness of our approach, as well as the strong synergy among its core components during inference.
Anomaly Detection and Generation with Diffusion Models: A Survey
Jun 11, 2025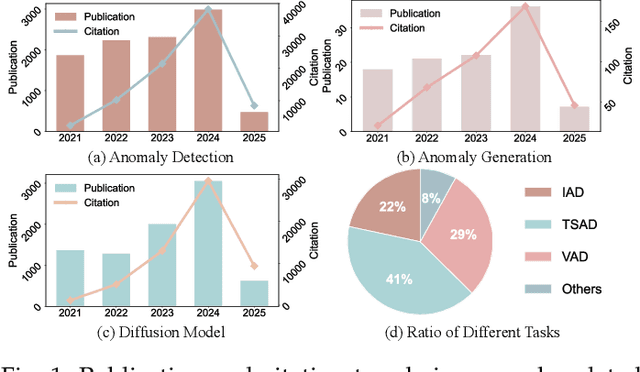

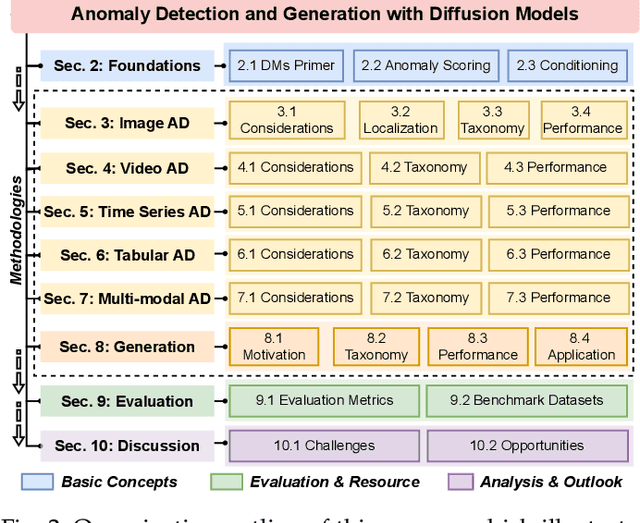

Anomaly detection (AD) plays a pivotal role across diverse domains, including cybersecurity, finance, healthcare, and industrial manufacturing, by identifying unexpected patterns that deviate from established norms in real-world data. Recent advancements in deep learning, specifically diffusion models (DMs), have sparked significant interest due to their ability to learn complex data distributions and generate high-fidelity samples, offering a robust framework for unsupervised AD. In this survey, we comprehensively review anomaly detection and generation with diffusion models (ADGDM), presenting a tutorial-style analysis of the theoretical foundations and practical implementations and spanning images, videos, time series, tabular, and multimodal data. Crucially, unlike existing surveys that often treat anomaly detection and generation as separate problems, we highlight their inherent synergistic relationship. We reveal how DMs enable a reinforcing cycle where generation techniques directly address the fundamental challenge of anomaly data scarcity, while detection methods provide critical feedback to improve generation fidelity and relevance, advancing both capabilities beyond their individual potential. A detailed taxonomy categorizes ADGDM methods based on anomaly scoring mechanisms, conditioning strategies, and architectural designs, analyzing their strengths and limitations. We final discuss key challenges including scalability and computational efficiency, and outline promising future directions such as efficient architectures, conditioning strategies, and integration with foundation models (e.g., visual-language models and large language models). By synthesizing recent advances and outlining open research questions, this survey aims to guide researchers and practitioners in leveraging DMs for innovative AD solutions across diverse applications.
Texture or Semantics? Vision-Language Models Get Lost in Font Recognition
Mar 31, 2025Modern Vision-Language Models (VLMs) exhibit remarkable visual and linguistic capabilities, achieving impressive performance in various tasks such as image recognition and object localization. However, their effectiveness in fine-grained tasks remains an open question. In everyday scenarios, individuals encountering design materials, such as magazines, typography tutorials, research papers, or branding content, may wish to identify aesthetically pleasing fonts used in the text. Given their multimodal capabilities and free accessibility, many VLMs are often considered potential tools for font recognition. This raises a fundamental question: Do VLMs truly possess the capability to recognize fonts? To investigate this, we introduce the Font Recognition Benchmark (FRB), a compact and well-structured dataset comprising 15 commonly used fonts. FRB includes two versions: (i) an easy version, where 10 sentences are rendered in different fonts, and (ii) a hard version, where each text sample consists of the names of the 15 fonts themselves, introducing a stroop effect that challenges model perception. Through extensive evaluation of various VLMs on font recognition tasks, we arrive at the following key findings: (i) Current VLMs exhibit limited font recognition capabilities, with many state-of-the-art models failing to achieve satisfactory performance. (ii) Few-shot learning and Chain-of-Thought (CoT) prompting provide minimal benefits in improving font recognition accuracy across different VLMs. (iii) Attention analysis sheds light on the inherent limitations of VLMs in capturing semantic features.