 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Diffusion Vision-Language Models for Temporal Action Localization
May 28, 2026Temporal action localization (TAL) requires recognizing the target event and localizing its start and end times precisely in untrimmed videos. Recent vision-language formulations improve semantic reasoning and support language-conditioned outputs, but their autoregressive decoders still generate tokens from left to right, preventing later semantic evidence from revising earlier timestamp predictions. We adapt masked diffusion vision-language models (MDVLMs) to TAL so that semantic tokens and boundary tokens remain editable throughout iterative denoising with bidirectional attention, allowing temporal boundaries and semantic content to be refined jointly. Direct adaptation, however, creates two TAL-specific mismatches: standard masked diffusion training corrupts all positions uniformly at random, but the time tokens are more reliable when enough semantic context is available; and token-level cross-entropy does not reflect temporal IoU. To address these mismatches, we introduce a Planned Training Objective that uses boundary-aware masking and step-weighted reconstruction to rehearse the late recovery of time tokens, together with a Step-Level IoU Reward that provides overlap-aware supervision during denoising. A standard sequence-level cross-entropy term provides the base reconstruction signal. Experiments on ActivityNet-RTL, ActivityNet-1.3, and THUMOS-14 show that MDVLM-TAL improves both temporal reasoning and boundary localization over autoregressive vision-language baselines, with especially strong gains under stricter temporal IoU criteria.
Leveraging Text-to-Image Diffusion Models for Unsupervised Visual Object Tracking
May 26, 2026Unsupervised visual object tracking is a challenging task that requires following arbitrary targets in videos without training on ground-truth annotations. Despite considerable progress, existing state-of-the-art unsupervised trackers often struggle in scenarios that demand fine-grained understanding of semantic and visual structural information within video frames. Text-to-image diffusion models are well known for their ability to generate images that accurately reflect the semantics and structures described in the input prompt, demonstrating a strong grasp of visual semantics and structures. Building on this capability, we approach the unsupervised tracking from a new perspective by exploiting the rich semantic knowledge encoded in pretrained text-to-image diffusion models. To adapt the diffusion models, which are originally developed for image generation, to the tracking task, we reinterpret the models as a bridge between text and image modalities. This connection is realized through the cross-attention mechanism: when both text and an image are input into the models, they highlight the regions of the image that are semantically aligned with the text in the cross-attention maps. We therefore learn a prompt that represents the tracking target and activates its corresponding region in the cross-attention map for each frame, which enables object tracking with the diffusion model. Specifically, our method Diff-Tracking is composed of two main components: an initial prompt learner and an online prompt updater. The initial prompt learner generates a prompt that captures the target object in the first frame, allowing the diffusion model to identify the target. The online prompt updater refines the prompt based on motion information, enabling consistent tracking across video frames. We evaluate our approach on six challenging tracking datasets demonstrate the effectiveness of our approach.
UAV-OVO: Out-of-Viewpoint Generalization in UAV Action Recognition
May 25, 2026UAV action recognition faces a deployment shift that standard benchmarks often obscure: a model trained on UAV footage captured from low-depression viewpoints may be required to recognize the same action classes from high-depression viewpoints. While the action labels remain unchanged, this shift alters body visibility, motion projection, and scene context, encouraging models to rely on viewpoint-specific shortcuts. We introduce UAV-OVO, an Out-of-Viewpoint generalization benchmark for UAV action recognition. UAV-OVO derives view scores from uncalibrated videos, uses a view-isolation band to assign low-depression videos to the training and in-distribution test splits while reserving high-depression videos for out-of-distribution testing, and constructs ID/OOD test sets matched by class distribution so that performance differences reflect viewpoint shift rather than label imbalance. Across representative video recognizers, UAV-OVO reveals a substantial ID/OOD gap: models that fit the low-depression training distribution well often fail to transfer to held-out high-depression views, exposing viewpoint shortcuts hidden by aggregate accuracy. We further propose LATER, LoRA-Anchored Test-time Re-centering, which first adapts the recognizer with Low-Rank Adaptation (LoRA) and then uses the learned LoRA subspace as a semantic anchor for online feature re-centering. Specifically, LATER projects target-domain displacement onto the orthogonal complement of the LoRA subspace before re-centering features, reducing viewpoint-induced drift while preserving task-relevant semantics. Together, UAV-OVO and LATER provide a controlled testbed and a practical adaptation method for viewpoint-robust UAV video understanding.
Visual-Advantage On-Policy Distillation for Vision-Language Models
May 21, 2026On-policy knowledge distillation has proven effective for language models, yet its application to vision-language models (VLMs) remains underexplored. We observe that standard on-policy distillation can improve a student's output quality while failing to strengthen its reliance on visual input: on vision-critical tokens, the student's predictions remain largely unchanged whether or not fine-grained visual detail is present, even though the teacher's predictions depend heavily on it.To make this difference observable, we introduce visual advantage (VA), the token-level log-probability difference when the teacher scores a student-generated rollout with versus without access to fine-grained visual detail. VA is concentrated in a small minority of tokens, and these high-VA tokens are the ones that actually carry the visual supervision signal. This motivates a distillation objective that treats them differently from language scaffolding, so their contribution is not diluted by the abundant surrounding language tokens.We propose Visual-Advantage On-Policy Distillation (VA-OPD), which uses VA at two granularities: rollout-level reweighting by trajectory-averaged VA, and token-level KL averaged within high-VA and low-VA groups separately. We train on two math datasets (Geometry3K and ViRL39K) and evaluate on eight benchmarks covering both mathematical reasoning and visual understanding, across three teacher sizes (4B, 8B, and 32B) on the Qwen3-VL family. VA-OPD improves over standard on-policy distillation on every benchmark, with the gain growing monotonically along both the teacher-size and data-scale axes, suggesting that these factors compound consistently.
Frequency-Enhanced Diffusion Models: Curriculum-Guided Semantic Alignment for Zero-Shot Skeleton Action Recognition
Apr 10, 2026Human action recognition is pivotal in computer vision, with applications ranging from surveillance to human-robot interaction. Despite the effectiveness of supervised skeleton-based methods, their reliance on exhaustive annotation limits generalization to novel actions. Zero-Shot Skeleton Action Recognition (ZSAR) emerges as a promising paradigm, yet it faces challenges due to the spectral bias of diffusion models, which oversmooth high-frequency dynamics. Here, we propose Frequency-Aware Diffusion for Skeleton-Text Matching (FDSM), integrating a Semantic-Guided Spectral Residual Module, a Timestep-Adaptive Spectral Loss, and Curriculum-based Semantic Abstraction to address these challenges. Our approach effectively recovers fine-grained motion details, achieving state-of-the-art performance on NTU RGB+D, PKU-MMD, and Kinetics-skeleton datasets. Code has been made available at https://github.com/yuzhi535/FDSM. Project homepage: https://yuzhi535.github.io/FDSM.github.io/
VisBrowse-Bench: Benchmarking Visual-Native Search for Multimodal Browsing Agents
Mar 17, 2026The rapid advancement of Multimodal Large Language Models (MLLMs) has enabled browsing agents to acquire and reason over multimodal information in the real world. But existing benchmarks suffer from two limitations: insufficient evaluation of visual reasoning ability and the neglect of native visual information of web pages in the reasoning chains. To address these challenges, we introduce a new benchmark for visual-native search, VisBrowse-Bench. It contains 169 VQA instances covering multiple domains and evaluates the models' visual reasoning capabilities during the search process through multimodal evidence cross-validation via text-image retrieval and joint reasoning. These data were constructed by human experts using a multi-stage pipeline and underwent rigorous manual verification. We additionally propose an agent workflow that can effectively drive the browsing agent to actively collect and reason over visual information during the search process. We comprehensively evaluated both open-source and closed-source models in this workflow. Experimental results show that even the best-performing model, Claude-4.6-Opus only achieves an accuracy of 47.6%, while the proprietary Deep Research model, o3-deep-research only achieves an accuracy of 41.1%. The code and data can be accessed at: https://github.com/ZhengboZhang/VisBrowse-Bench
DSFC-Net: A Dual-Encoder Spatial and Frequency Co-Awareness Network for Rural Road Extraction
Feb 01, 2026Accurate extraction of rural roads from high-resolution remote sensing imagery is essential for infrastructure planning and sustainable development. However, this task presents unique challenges in rural settings due to several factors. These include high intra-class variability and low inter-class separability from diverse surface materials, frequent vegetation occlusions that disrupt spatial continuity, and narrow road widths that exacerbate detection difficulties. Existing methods, primarily optimized for structured urban environments, often underperform in these scenarios as they overlook such distinctive characteristics. To address these challenges, we propose DSFC-Net, a dual-encoder framework that synergistically fuses spatial and frequency-domain information. Specifically, a CNN branch is employed to capture fine-grained local road boundaries and short-range continuity, while a novel Spatial-Frequency Hybrid Transformer (SFT) is introduced to robustly model global topological dependencies against vegetation occlusions. Distinct from standard attention mechanisms that suffer from frequency bias, the SFT incorporates a Cross-Frequency Interaction Attention (CFIA) module that explicitly decouples high- and low-frequency information via a Laplacian Pyramid strategy. This design enables the dynamic interaction between spatial details and frequency-aware global contexts, effectively preserving the connectivity of narrow roads. Furthermore, a Channel Feature Fusion Module (CFFM) is proposed to bridge the two branches by adaptively recalibrating channel-wise feature responses, seamlessly integrating local textures with global semantics for accurate segmentation. Comprehensive experiments on the WHU-RuR+, DeepGlobe, and Massachusetts datasets validate the superiority of DSFC-Net over state-of-the-art approaches.
Beyond Artifacts: Real-Centric Envelope Modeling for Reliable AI-Generated Image Detection
Dec 24, 2025The rapid progress of generative models has intensified the need for reliable and robust detection under real-world conditions. However, existing detectors often overfit to generator-specific artifacts and remain highly sensitive to real-world degradations. As generative architectures evolve and images undergo multi-round cross-platform sharing and post-processing (chain degradations), these artifact cues become obsolete and harder to detect. To address this, we propose Real-centric Envelope Modeling (REM), a new paradigm that shifts detection from learning generator artifacts to modeling the robust distribution of real images. REM introduces feature-level perturbations in self-reconstruction to generate near-real samples, and employs an envelope estimator with cross-domain consistency to learn a boundary enclosing the real image manifold. We further build RealChain, a comprehensive benchmark covering both open-source and commercial generators with simulated real-world degradation. Across eight benchmark evaluations, REM achieves an average improvement of 7.5% over state-of-the-art methods, and notably maintains exceptional generalization on the severely degraded RealChain benchmark, establishing a solid foundation for synthetic image detection under real-world conditions. The code and the RealChain benchmark will be made publicly available upon acceptance of the paper.
A Novel Modeling Framework and Data Product for Extended VIIRS-like Artificial Nighttime Light Image Reconstruction (1986-2024)
Aug 01, 2025
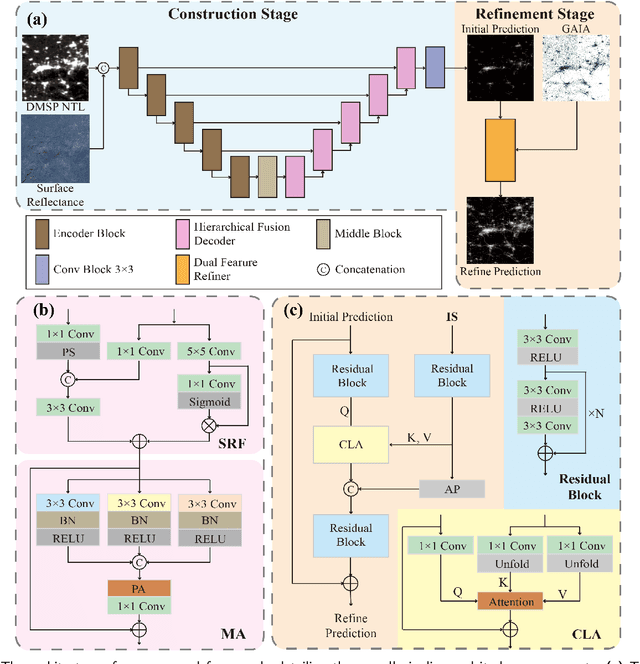
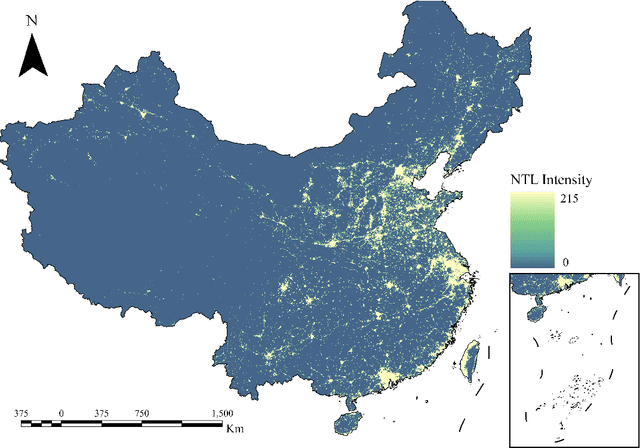

Artificial Night-Time Light (NTL) remote sensing is a vital proxy for quantifying the intensity and spatial distribution of human activities. Although the NPP-VIIRS sensor provides high-quality NTL observations, its temporal coverage, which begins in 2012, restricts long-term time-series studies that extend to earlier periods. Despite the progress in extending VIIRS-like NTL time-series, current methods still suffer from two significant shortcomings: the underestimation of light intensity and the structural omission. To overcome these limitations, we propose a novel reconstruction framework consisting of a two-stage process: construction and refinement. The construction stage features a Hierarchical Fusion Decoder (HFD) designed to enhance the fidelity of the initial reconstruction. The refinement stage employs a Dual Feature Refiner (DFR), which leverages high-resolution impervious surface masks to guide and enhance fine-grained structural details. Based on this framework, we developed the Extended VIIRS-like Artificial Nighttime Light (EVAL) product for China, extending the standard data record backwards by 26 years to begin in 1986. Quantitative evaluation shows that EVAL significantly outperforms existing state-of-the-art products, boosting the $\text{R}^2$ from 0.68 to 0.80 while lowering the RMSE from 1.27 to 0.99. Furthermore, EVAL exhibits excellent temporal consistency and maintains a high correlation with socioeconomic parameters, confirming its reliability for long-term analysis. The resulting EVAL dataset provides a valuable new resource for the research community and is publicly available at https://doi.org/10.11888/HumanNat.tpdc.302930.
InstaInpaint: Instant 3D-Scene Inpainting with Masked Large Reconstruction Model
Jun 12, 2025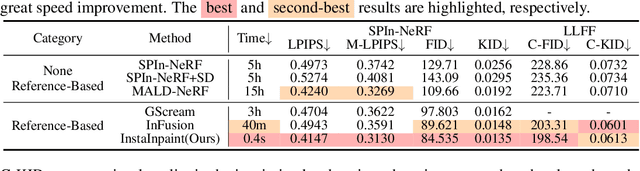


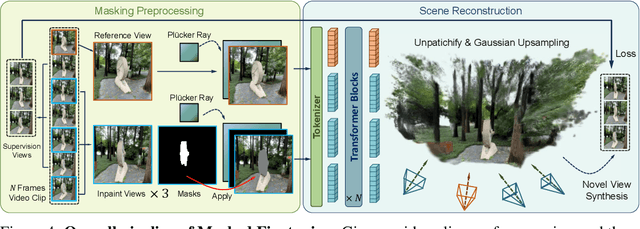
Recent advances in 3D scene reconstruction enable real-time viewing in virtual and augmented reality. To support interactive operations for better immersiveness, such as moving or editing objects, 3D scene inpainting methods are proposed to repair or complete the altered geometry. However, current approaches rely on lengthy and computationally intensive optimization, making them impractical for real-time or online applications. We propose InstaInpaint, a reference-based feed-forward framework that produces 3D-scene inpainting from a 2D inpainting proposal within 0.4 seconds. We develop a self-supervised masked-finetuning strategy to enable training of our custom large reconstruction model (LRM) on the large-scale dataset. Through extensive experiments, we analyze and identify several key designs that improve generalization, textural consistency, and geometric correctness. InstaInpaint achieves a 1000x speed-up from prior methods while maintaining a state-of-the-art performance across two standard benchmarks. Moreover, we show that InstaInpaint generalizes well to flexible downstream applications such as object insertion and multi-region inpainting. More video results are available at our project page: https://dhmbb2.github.io/InstaInpaint_page/.