 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Diffusion Vision-Language Models for Temporal Action Localization
May 28, 2026Temporal action localization (TAL) requires recognizing the target event and localizing its start and end times precisely in untrimmed videos. Recent vision-language formulations improve semantic reasoning and support language-conditioned outputs, but their autoregressive decoders still generate tokens from left to right, preventing later semantic evidence from revising earlier timestamp predictions. We adapt masked diffusion vision-language models (MDVLMs) to TAL so that semantic tokens and boundary tokens remain editable throughout iterative denoising with bidirectional attention, allowing temporal boundaries and semantic content to be refined jointly. Direct adaptation, however, creates two TAL-specific mismatches: standard masked diffusion training corrupts all positions uniformly at random, but the time tokens are more reliable when enough semantic context is available; and token-level cross-entropy does not reflect temporal IoU. To address these mismatches, we introduce a Planned Training Objective that uses boundary-aware masking and step-weighted reconstruction to rehearse the late recovery of time tokens, together with a Step-Level IoU Reward that provides overlap-aware supervision during denoising. A standard sequence-level cross-entropy term provides the base reconstruction signal. Experiments on ActivityNet-RTL, ActivityNet-1.3, and THUMOS-14 show that MDVLM-TAL improves both temporal reasoning and boundary localization over autoregressive vision-language baselines, with especially strong gains under stricter temporal IoU criteria.
Leveraging Text-to-Image Diffusion Models for Unsupervised Visual Object Tracking
May 26, 2026Unsupervised visual object tracking is a challenging task that requires following arbitrary targets in videos without training on ground-truth annotations. Despite considerable progress, existing state-of-the-art unsupervised trackers often struggle in scenarios that demand fine-grained understanding of semantic and visual structural information within video frames. Text-to-image diffusion models are well known for their ability to generate images that accurately reflect the semantics and structures described in the input prompt, demonstrating a strong grasp of visual semantics and structures. Building on this capability, we approach the unsupervised tracking from a new perspective by exploiting the rich semantic knowledge encoded in pretrained text-to-image diffusion models. To adapt the diffusion models, which are originally developed for image generation, to the tracking task, we reinterpret the models as a bridge between text and image modalities. This connection is realized through the cross-attention mechanism: when both text and an image are input into the models, they highlight the regions of the image that are semantically aligned with the text in the cross-attention maps. We therefore learn a prompt that represents the tracking target and activates its corresponding region in the cross-attention map for each frame, which enables object tracking with the diffusion model. Specifically, our method Diff-Tracking is composed of two main components: an initial prompt learner and an online prompt updater. The initial prompt learner generates a prompt that captures the target object in the first frame, allowing the diffusion model to identify the target. The online prompt updater refines the prompt based on motion information, enabling consistent tracking across video frames. We evaluate our approach on six challenging tracking datasets demonstrate the effectiveness of our approach.
UAV-OVO: Out-of-Viewpoint Generalization in UAV Action Recognition
May 25, 2026UAV action recognition faces a deployment shift that standard benchmarks often obscure: a model trained on UAV footage captured from low-depression viewpoints may be required to recognize the same action classes from high-depression viewpoints. While the action labels remain unchanged, this shift alters body visibility, motion projection, and scene context, encouraging models to rely on viewpoint-specific shortcuts. We introduce UAV-OVO, an Out-of-Viewpoint generalization benchmark for UAV action recognition. UAV-OVO derives view scores from uncalibrated videos, uses a view-isolation band to assign low-depression videos to the training and in-distribution test splits while reserving high-depression videos for out-of-distribution testing, and constructs ID/OOD test sets matched by class distribution so that performance differences reflect viewpoint shift rather than label imbalance. Across representative video recognizers, UAV-OVO reveals a substantial ID/OOD gap: models that fit the low-depression training distribution well often fail to transfer to held-out high-depression views, exposing viewpoint shortcuts hidden by aggregate accuracy. We further propose LATER, LoRA-Anchored Test-time Re-centering, which first adapts the recognizer with Low-Rank Adaptation (LoRA) and then uses the learned LoRA subspace as a semantic anchor for online feature re-centering. Specifically, LATER projects target-domain displacement onto the orthogonal complement of the LoRA subspace before re-centering features, reducing viewpoint-induced drift while preserving task-relevant semantics. Together, UAV-OVO and LATER provide a controlled testbed and a practical adaptation method for viewpoint-robust UAV video understanding.
Frequency-Enhanced Diffusion Models: Curriculum-Guided Semantic Alignment for Zero-Shot Skeleton Action Recognition
Apr 10, 2026Human action recognition is pivotal in computer vision, with applications ranging from surveillance to human-robot interaction. Despite the effectiveness of supervised skeleton-based methods, their reliance on exhaustive annotation limits generalization to novel actions. Zero-Shot Skeleton Action Recognition (ZSAR) emerges as a promising paradigm, yet it faces challenges due to the spectral bias of diffusion models, which oversmooth high-frequency dynamics. Here, we propose Frequency-Aware Diffusion for Skeleton-Text Matching (FDSM), integrating a Semantic-Guided Spectral Residual Module, a Timestep-Adaptive Spectral Loss, and Curriculum-based Semantic Abstraction to address these challenges. Our approach effectively recovers fine-grained motion details, achieving state-of-the-art performance on NTU RGB+D, PKU-MMD, and Kinetics-skeleton datasets. Code has been made available at https://github.com/yuzhi535/FDSM. Project homepage: https://yuzhi535.github.io/FDSM.github.io/
EFSI-DETR: Efficient Frequency-Semantic Integration for Real-Time Small Object Detection in UAV Imagery
Jan 26, 2026Real-time small object detection in Unmanned Aerial Vehicle (UAV) imagery remains challenging due to limited feature representation and ineffective multi-scale fusion. Existing methods underutilize frequency information and rely on static convolutional operations, which constrain the capacity to obtain rich feature representations and hinder the effective exploitation of deep semantic features. To address these issues, we propose EFSI-DETR, a novel detection framework that integrates efficient semantic feature enhancement with dynamic frequency-spatial guidance. EFSI-DETR comprises two main components: (1) a Dynamic Frequency-Spatial Unified Synergy Network (DyFusNet) that jointly exploits frequency and spatial cues for robust multi-scale feature fusion, (2) an Efficient Semantic Feature Concentrator (ESFC) that enables deep semantic extraction with minimal computational cost. Furthermore, a Fine-grained Feature Retention (FFR) strategy is adopted to incorporate spatially rich shallow features during fusion to preserve fine-grained details, crucial for small object detection in UAV imagery. Extensive experiments on VisDrone and CODrone benchmarks demonstrate that our EFSI-DETR achieves the state-of-the-art performance with real-time efficiency, yielding improvement of \textbf{1.6}\% and \textbf{5.8}\% in AP and AP$_{s}$ on VisDrone, while obtaining \textbf{188} FPS inference speed on a single RTX 4090 GPU.
DreamDance: Animating Character Art via Inpainting Stable Gaussian Worlds
May 30, 2025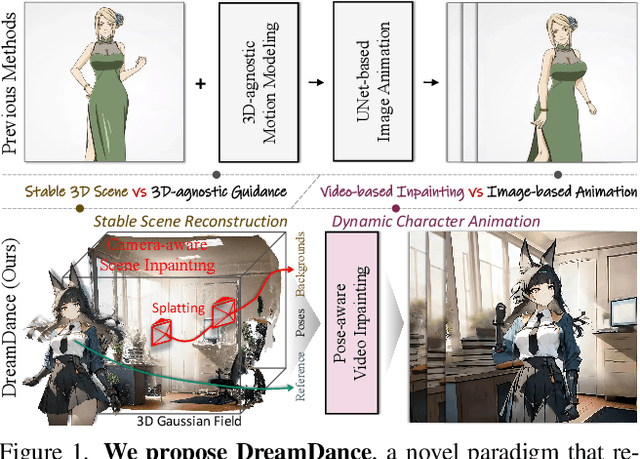

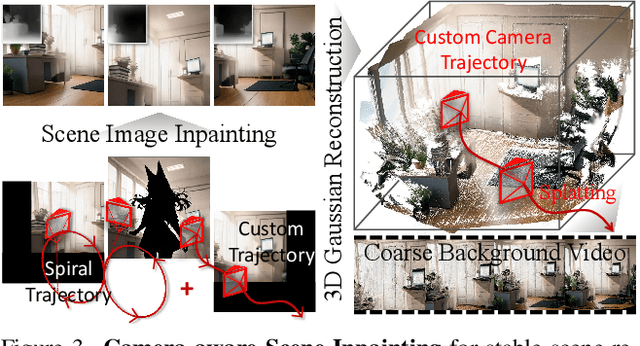
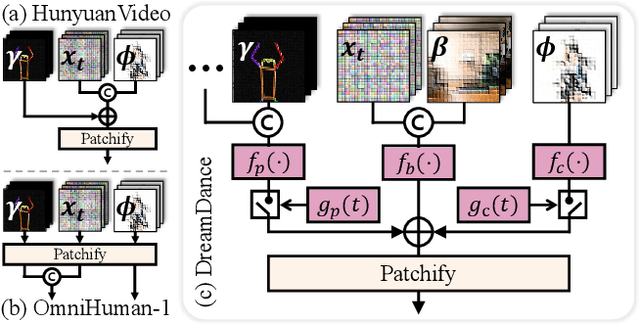
This paper presents DreamDance, a novel character art animation framework capable of producing stable, consistent character and scene motion conditioned on precise camera trajectories. To achieve this, we re-formulate the animation task as two inpainting-based steps: Camera-aware Scene Inpainting and Pose-aware Video Inpainting. The first step leverages a pre-trained image inpainting model to generate multi-view scene images from the reference art and optimizes a stable large-scale Gaussian field, which enables coarse background video rendering with camera trajectories. However, the rendered video is rough and only conveys scene motion. To resolve this, the second step trains a pose-aware video inpainting model that injects the dynamic character into the scene video while enhancing background quality. Specifically, this model is a DiT-based video generation model with a gating strategy that adaptively integrates the character's appearance and pose information into the base background video. Through extensive experiments, we demonstrate the effectiveness and generalizability of DreamDance, producing high-quality and consistent character animations with remarkable camera dynamics.
Visual Prompting for One-shot Controllable Video Editing without Inversion
Apr 19, 2025



One-shot controllable video editing (OCVE) is an important yet challenging task, aiming to propagate user edits that are made -- using any image editing tool -- on the first frame of a video to all subsequent frames, while ensuring content consistency between edited frames and source frames. To achieve this, prior methods employ DDIM inversion to transform source frames into latent noise, which is then fed into a pre-trained diffusion model, conditioned on the user-edited first frame, to generate the edited video. However, the DDIM inversion process accumulates errors, which hinder the latent noise from accurately reconstructing the source frames, ultimately compromising content consistency in the generated edited frames. To overcome it, our method eliminates the need for DDIM inversion by performing OCVE through a novel perspective based on visual prompting. Furthermore, inspired by consistency models that can perform multi-step consistency sampling to generate a sequence of content-consistent images, we propose a content consistency sampling (CCS) to ensure content consistency between the generated edited frames and the source frames. Moreover, we introduce a temporal-content consistency sampling (TCS) based on Stein Variational Gradient Descent to ensure temporal consistency across the edited frames. Extensive experiments validate the effectiveness of our approach.
EchoMask: Speech-Queried Attention-based Mask Modeling for Holistic Co-Speech Motion Generation
Apr 15, 2025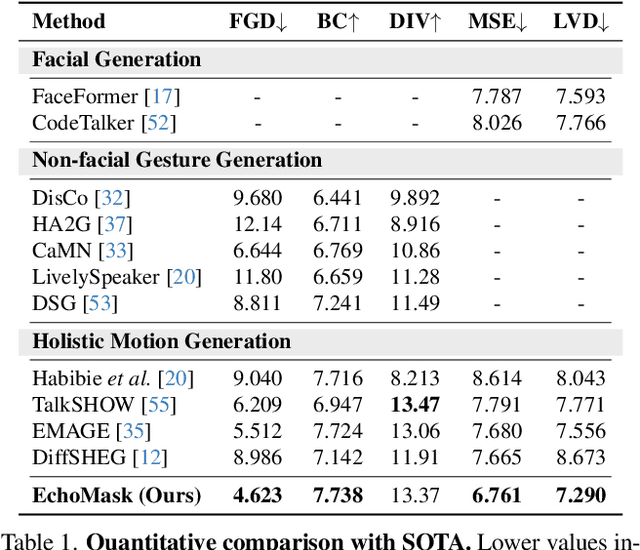
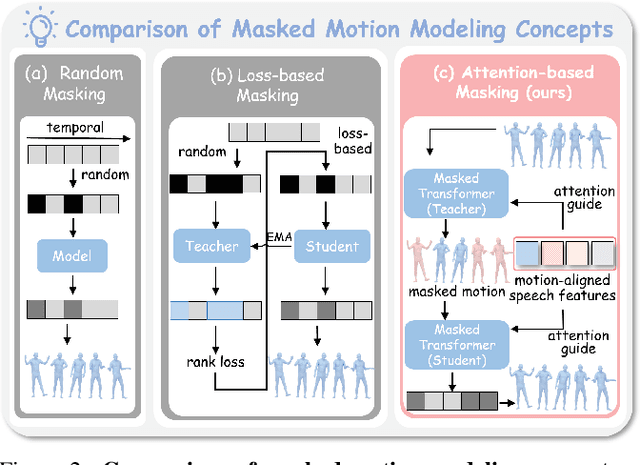
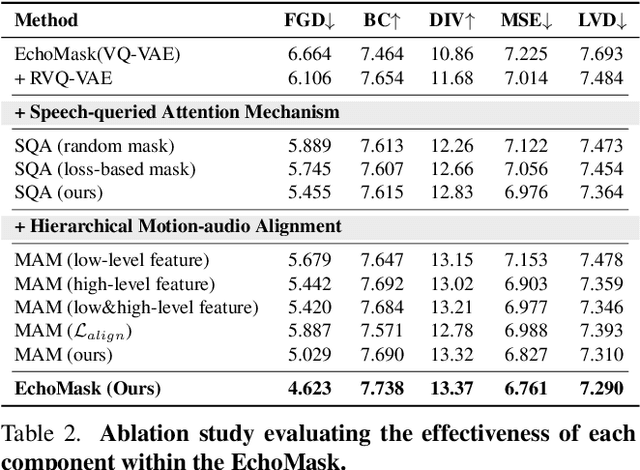
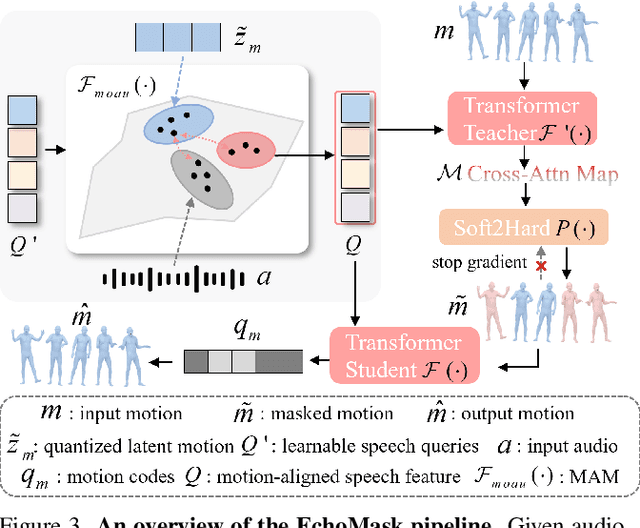
Masked modeling framework has shown promise in co-speech motion generation. However, it struggles to identify semantically significant frames for effective motion masking. In this work, we propose a speech-queried attention-based mask modeling framework for co-speech motion generation. Our key insight is to leverage motion-aligned speech features to guide the masked motion modeling process, selectively masking rhythm-related and semantically expressive motion frames. Specifically, we first propose a motion-audio alignment module (MAM) to construct a latent motion-audio joint space. In this space, both low-level and high-level speech features are projected, enabling motion-aligned speech representation using learnable speech queries. Then, a speech-queried attention mechanism (SQA) is introduced to compute frame-level attention scores through interactions between motion keys and speech queries, guiding selective masking toward motion frames with high attention scores. Finally, the motion-aligned speech features are also injected into the generation network to facilitate co-speech motion generation. Qualitative and quantitative evaluations confirm that our method outperforms existing state-of-the-art approaches, successfully producing high-quality co-speech motion.
EMO-X: Efficient Multi-Person Pose and Shape Estimation in One-Stage
Apr 11, 2025Expressive Human Pose and Shape Estimation (EHPS) aims to jointly estimate human pose, hand gesture, and facial expression from monocular images. Existing methods predominantly rely on Transformer-based architectures, which suffer from quadratic complexity in self-attention, leading to substantial computational overhead, especially in multi-person scenarios. Recently, Mamba has emerged as a promising alternative to Transformers due to its efficient global modeling capability. However, it remains limited in capturing fine-grained local dependencies, which are essential for precise EHPS. To address these issues, we propose EMO-X, the Efficient Multi-person One-stage model for multi-person EHPS. Specifically, we explore a Scan-based Global-Local Decoder (SGLD) that integrates global context with skeleton-aware local features to iteratively enhance human tokens. Our EMO-X leverages the superior global modeling capability of Mamba and designs a local bidirectional scan mechanism for skeleton-aware local refinement. Comprehensive experiments demonstrate that EMO-X strikes an excellent balance between efficiency and accuracy. Notably, it achieves a significant reduction in computational complexity, requiring 69.8% less inference time compared to state-of-the-art (SOTA) methods, while outperforming most of them in accuracy.
OwlSight: A Robust Illumination Adaptation Framework for Dark Video Human Action Recognition
Mar 30, 2025Human action recognition in low-light environments is crucial for various real-world applications. However, the existing approaches overlook the full utilization of brightness information throughout the training phase, leading to suboptimal performance. To address this limitation, we propose OwlSight, a biomimetic-inspired framework with whole-stage illumination enhancement to interact with action classification for accurate dark video human action recognition. Specifically, OwlSight incorporates a Time-Consistency Module (TCM) to capture shallow spatiotemporal features meanwhile maintaining temporal coherence, which are then processed by a Luminance Adaptation Module (LAM) to dynamically adjust the brightness based on the input luminance distribution. Furthermore, a Reflect Augmentation Module (RAM) is presented to maximize illumination utilization and simultaneously enhance action recognition via two interactive paths. Additionally, we build Dark-101, a large-scale dataset comprising 18,310 dark videos across 101 action categories, significantly surpassing existing datasets (e.g., ARID1.5 and Dark-48) in scale and diversity. Extensive experiments demonstrate that the proposed OwlSight achieves state-of-the-art performance across four low-light action recognition benchmarks. Notably, it outperforms previous best approaches by 5.36% on ARID1.5 and 1.72% on Dark-101, highlighting its effectiveness in challenging dark environments.