 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMG-Avatar: One-shot Multi-LOD Gaussian Head Avatar
Mar 02, 2026We propose OMG-Avatar, a novel One-shot method that leverages a Multi-LOD (Level-of-Detail) Gaussian representation for animatable 3D head reconstruction from a single image in 0.2s. Our method enables LOD head avatar modeling using a unified model that accommodates diverse hardware capabilities and inference speed requirements. To capture both global and local facial characteristics, we employ a transformer-based architecture for global feature extraction and projection-based sampling for local feature acquisition. These features are effectively fused under the guidance of a depth buffer, ensuring occlusion plausibility. We further introduce a coarse-to-fine learning paradigm to support Level-of-Detail functionality and enhance the perception of hierarchical details. To address the limitations of 3DMMs in modeling non-head regions such as the shoulders, we introduce a multi-region decomposition scheme in which the head and shoulders are predicted separately and then integrated through cross-region combination. Extensive experiments demonstrate that OMG-Avatar outperforms state-of-the-art methods in reconstruction quality, reenactment performance, and computational efficiency.
Mitigating Error Accumulation in Co-Speech Motion Generation via Global Rotation Diffusion and Multi-Level Constraints
Nov 13, 2025Reliable co-speech motion generation requires precise motion representation and consistent structural priors across all joints. Existing generative methods typically operate on local joint rotations, which are defined hierarchically based on the skeleton structure. This leads to cumulative errors during generation, manifesting as unstable and implausible motions at end-effectors. In this work, we propose GlobalDiff, a diffusion-based framework that operates directly in the space of global joint rotations for the first time, fundamentally decoupling each joint's prediction from upstream dependencies and alleviating hierarchical error accumulation. To compensate for the absence of structural priors in global rotation space, we introduce a multi-level constraint scheme. Specifically, a joint structure constraint introduces virtual anchor points around each joint to better capture fine-grained orientation. A skeleton structure constraint enforces angular consistency across bones to maintain structural integrity. A temporal structure constraint utilizes a multi-scale variational encoder to align the generated motion with ground-truth temporal patterns. These constraints jointly regularize the global diffusion process and reinforce structural awareness. Extensive evaluations on standard co-speech benchmarks show that GlobalDiff generates smooth and accurate motions, improving the performance by 46.0 % compared to the current SOTA under multiple speaker identities.
* AAAI 2026
CartoonAlive: Towards Expressive Live2D Modeling from Single Portraits
Jul 23, 2025With the rapid advancement of large foundation models, AIGC, cloud rendering, and real-time motion capture technologies, digital humans are now capable of achieving synchronized facial expressions and body movements, engaging in intelligent dialogues driven by natural language, and enabling the fast creation of personalized avatars. While current mainstream approaches to digital humans primarily focus on 3D models and 2D video-based representations, interactive 2D cartoon-style digital humans have received relatively less attention. Compared to 3D digital humans that require complex modeling and high rendering costs, and 2D video-based solutions that lack flexibility and real-time interactivity, 2D cartoon-style Live2D models offer a more efficient and expressive alternative. By simulating 3D-like motion through layered segmentation without the need for traditional 3D modeling, Live2D enables dynamic and real-time manipulation. In this technical report, we present CartoonAlive, an innovative method for generating high-quality Live2D digital humans from a single input portrait image. CartoonAlive leverages the shape basis concept commonly used in 3D face modeling to construct facial blendshapes suitable for Live2D. It then infers the corresponding blendshape weights based on facial keypoints detected from the input image. This approach allows for the rapid generation of a highly expressive and visually accurate Live2D model that closely resembles the input portrait, within less than half a minute. Our work provides a practical and scalable solution for creating interactive 2D cartoon characters, opening new possibilities in digital content creation and virtual character animation. The project homepage is https://human3daigc.github.io/CartoonAlive_webpage/.
EchoMask: Speech-Queried Attention-based Mask Modeling for Holistic Co-Speech Motion Generation
Apr 15, 2025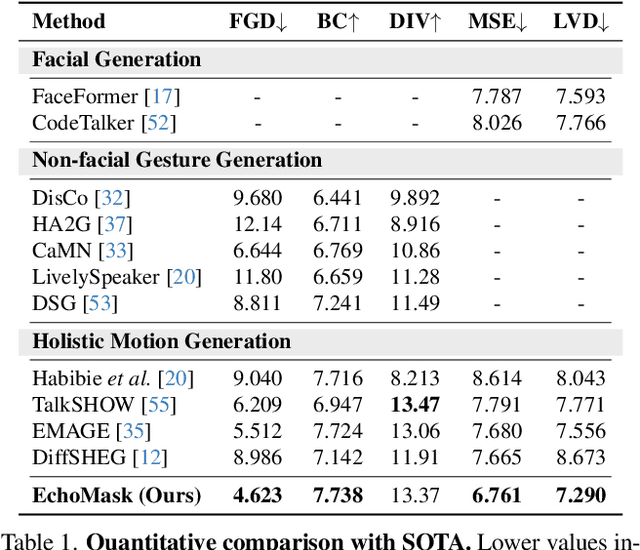
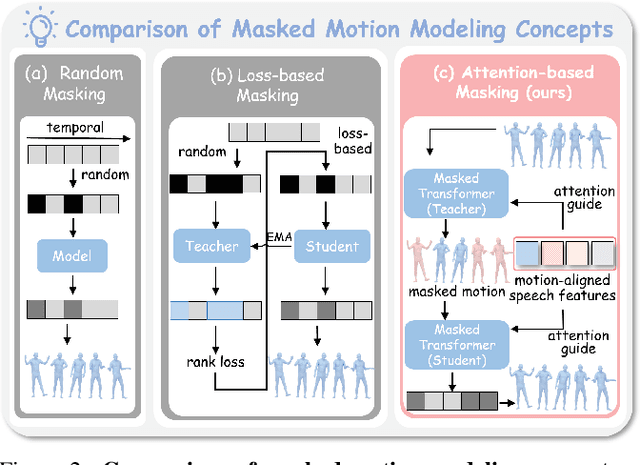
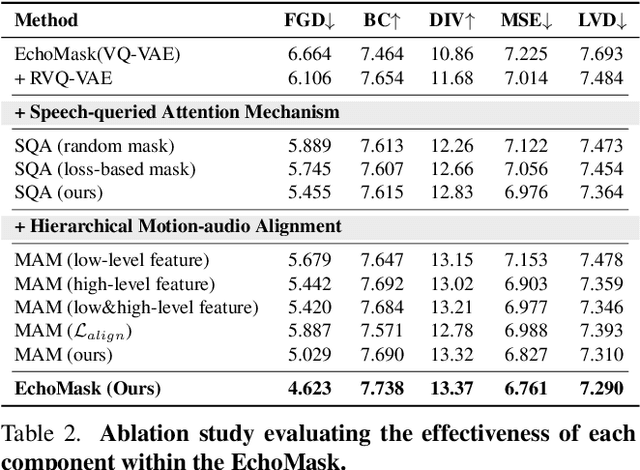
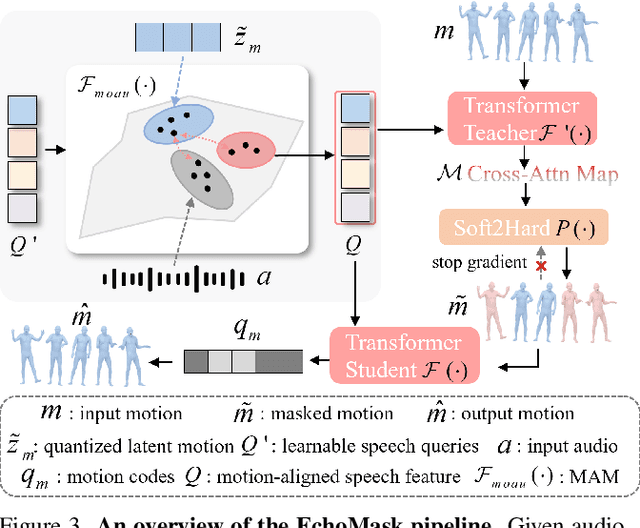
Masked modeling framework has shown promise in co-speech motion generation. However, it struggles to identify semantically significant frames for effective motion masking. In this work, we propose a speech-queried attention-based mask modeling framework for co-speech motion generation. Our key insight is to leverage motion-aligned speech features to guide the masked motion modeling process, selectively masking rhythm-related and semantically expressive motion frames. Specifically, we first propose a motion-audio alignment module (MAM) to construct a latent motion-audio joint space. In this space, both low-level and high-level speech features are projected, enabling motion-aligned speech representation using learnable speech queries. Then, a speech-queried attention mechanism (SQA) is introduced to compute frame-level attention scores through interactions between motion keys and speech queries, guiding selective masking toward motion frames with high attention scores. Finally, the motion-aligned speech features are also injected into the generation network to facilitate co-speech motion generation. Qualitative and quantitative evaluations confirm that our method outperforms existing state-of-the-art approaches, successfully producing high-quality co-speech motion.
Textoon: Generating Vivid 2D Cartoon Characters from Text Descriptions
Jan 17, 2025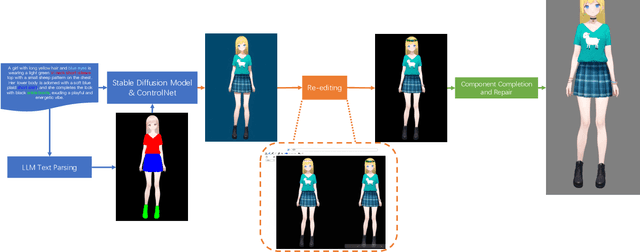
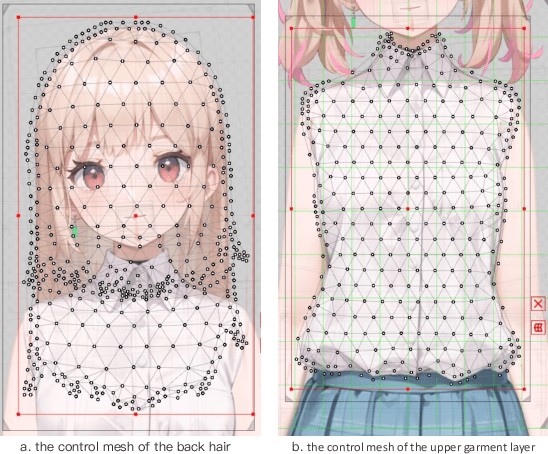
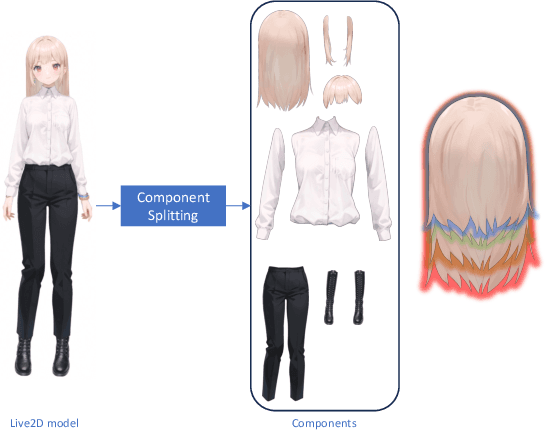

The 2D cartoon style is a prominent art form in digital character creation, particularly popular among younger audiences. While advancements in digital human technology have spurred extensive research into photorealistic digital humans and 3D characters, interactive 2D cartoon characters have received comparatively less attention. Unlike 3D counterparts, which require sophisticated construction and resource-intensive rendering, Live2D, a widely-used format for 2D cartoon characters, offers a more efficient alternative, which allows to animate 2D characters in a manner that simulates 3D movement without the necessity of building a complete 3D model. Furthermore, Live2D employs lightweight HTML5 (H5) rendering, improving both accessibility and efficiency. In this technical report, we introduce Textoon, an innovative method for generating diverse 2D cartoon characters in the Live2D format based on text descriptions. The Textoon leverages cutting-edge language and vision models to comprehend textual intentions and generate 2D appearance, capable of creating a wide variety of stunning and interactive 2D characters within one minute. The project homepage is https://human3daigc.github.io/Textoon_webpage/.
Make-A-Character 2: Animatable 3D Character Generation From a Single Image
Jan 15, 2025



This report introduces Make-A-Character 2, an advanced system for generating high-quality 3D characters from single portrait photographs, ideal for game development and digital human applications. Make-A-Character 2 builds upon its predecessor by incorporating several significant improvements for image-based head generation. We utilize the IC-Light method to correct non-ideal illumination in input photos and apply neural network-based color correction to harmonize skin tones between the photos and game engine renders. We also employ the Hierarchical Representation Network to capture high-frequency facial structures and conduct adaptive skeleton calibration for accurate and expressive facial animations. The entire image-to-3D-character generation process takes less than 2 minutes. Furthermore, we leverage transformer architecture to generate co-speech facial and gesture actions, enabling real-time conversation with the generated character. These technologies have been integrated into our conversational AI avatar products.
SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis
Dec 21, 2024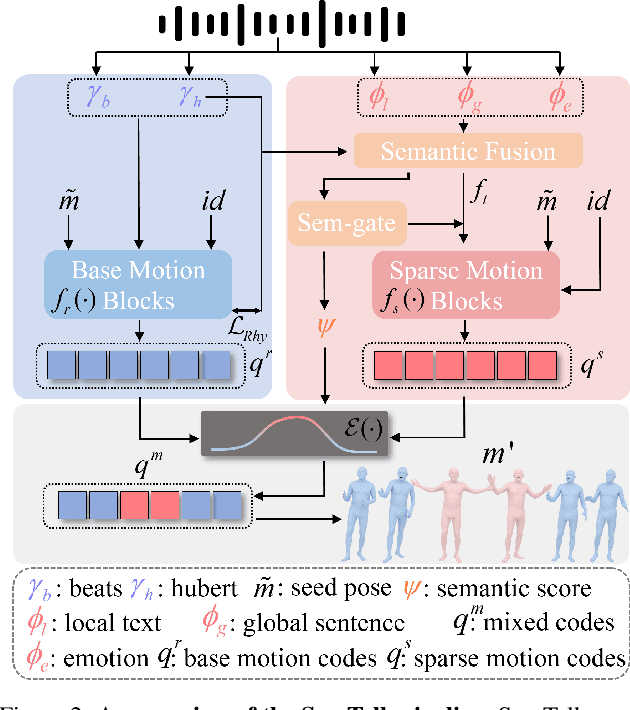
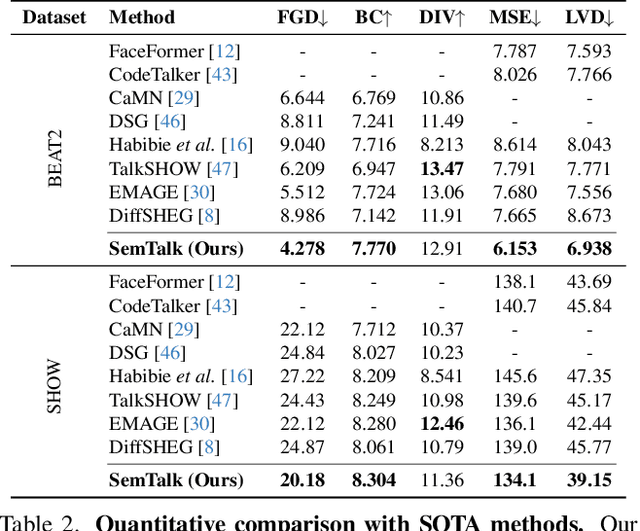
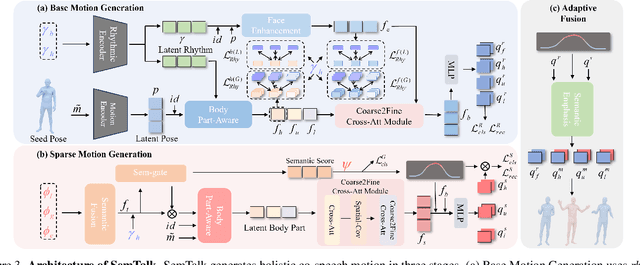

A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn general motions and sparse motions, and then adaptively fuse them. In particular, rhythmic consistency learning is explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, textit{semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion.
Make-A-Character: High Quality Text-to-3D Character Generation within Minutes
Dec 24, 2023



There is a growing demand for customized and expressive 3D characters with the emergence of AI agents and Metaverse, but creating 3D characters using traditional computer graphics tools is a complex and time-consuming task. To address these challenges, we propose a user-friendly framework named Make-A-Character (Mach) to create lifelike 3D avatars from text descriptions. The framework leverages the power of large language and vision models for textual intention understanding and intermediate image generation, followed by a series of human-oriented visual perception and 3D generation modules. Our system offers an intuitive approach for users to craft controllable, realistic, fully-realized 3D characters that meet their expectations within 2 minutes, while also enabling easy integration with existing CG pipeline for dynamic expressiveness. For more information, please visit the project page at https://human3daigc.github.io/MACH/.
A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
Feb 28, 2023Limited by the nature of the low-dimensional representational capacity of 3DMM, most of the 3DMM-based face reconstruction (FR) methods fail to recover high-frequency facial details, such as wrinkles, dimples, etc. Some attempt to solve the problem by introducing detail maps or non-linear operations, however, the results are still not vivid. To this end, we in this paper present a novel hierarchical representation network (HRN) to achieve accurate and detailed face reconstruction from a single image. Specifically, we implement the geometry disentanglement and introduce the hierarchical representation to fulfill detailed face modeling. Meanwhile, 3D priors of facial details are incorporated to enhance the accuracy and authenticity of the reconstruction results. We also propose a de-retouching module to achieve better decoupling of the geometry and appearance. It is noteworthy that our framework can be extended to a multi-view fashion by considering detail consistency of different views. Extensive experiments on two single-view and two multi-view FR benchmarks demonstrate that our method outperforms the existing methods in both reconstruction accuracy and visual effects. Finally, we introduce a high-quality 3D face dataset FaceHD-100 to boost the research of high-fidelity face reconstruction.
Structure-Aware Flow Generation for Human Body Reshaping
Mar 11, 2022
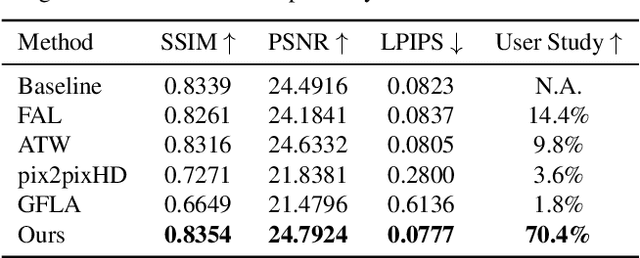
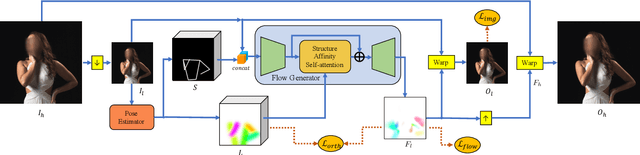

Body reshaping is an important procedure in portrait photo retouching. Due to the complicated structure and multifarious appearance of human bodies, existing methods either fall back on the 3D domain via body morphable model or resort to keypoint-based image deformation, leading to inefficiency and unsatisfied visual quality. In this paper, we address these limitations by formulating an end-to-end flow generation architecture under the guidance of body structural priors, including skeletons and Part Affinity Fields, and achieve unprecedentedly controllable performance under arbitrary poses and garments. A compositional attention mechanism is introduced for capturing both visual perceptual correlations and structural associations of the human body to reinforce the manipulation consistency among related parts. For a comprehensive evaluation, we construct the first large-scale body reshaping dataset, namely BR-5K, which contains 5,000 portrait photos as well as professionally retouched targets. Extensive experiments demonstrate that our approach significantly outperforms existing state-of-the-art methods in terms of visual performance, controllability, and efficiency. The dataset is available at our website: https://github.com/JianqiangRen/FlowBasedBodyReshaping.