 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuiYanEarth-SAR: A Foundation Model for High-Fidelity and Low-Cost Global Remote Sensing Imagery Generation
Apr 13, 2026Synthetic Aperture Radar (SAR) imagery generation is essential for deepening the study of scattering mechanisms, establishing trustworthy electromagnetic scene models, and fundamentally alleviating the data scarcity bottleneck that constrains development in this field. However, existing methods find it difficult to simultaneously ensure high fidelity in both global geospatial semantics and microscopic scattering mechanisms, resulting in severe challenges for global generation. To address this, we propose \textbf{HuiYanEarth-SAR}, the first foundational SAR imagery generation model based on AlphaEarth and integrated scattering mechanisms. By injecting geospatial priors to control macroscopic structures and utilizing implicit scattering characteristic modeling to ensure the authenticity of microscopic textures, we achieve the capability of generating high-fidelity SAR images for global locations solely based on geographic coordinates. This study not only constructs an efficient SAR scene simulator but also establishes a bridge connecting geography, scatter mechanism, and artificial intelligence from a methodological standpoint. It advances SAR research by expanding the paradigm from perception and understanding to simulation and creation, providing key technical support for constructing a high-confidence digital twin of the Earth.
Fifty Years of SAR Automatic Target Recognition: The Road Forward
Sep 26, 2025This paper provides the first comprehensive review of fifty years of synthetic aperture radar automatic target recognition (SAR ATR) development, tracing its evolution from inception to the present day. Central to our analysis is the inheritance and refinement of traditional methods, such as statistical modeling, scattering center analysis, and feature engineering, within modern deep learning frameworks. The survey clearly distinguishes long-standing challenges that have been substantially mitigated by deep learning from newly emerging obstacles. We synthesize recent advances in physics-guided deep learning and propose future directions toward more generalizable and physically-consistent SAR ATR. Additionally, we provide a systematically organized compilation of all publicly available SAR datasets, complete with direct links to support reproducibility and benchmarking. This work not only documents the technical evolution of the field but also offers practical resources and forward-looking insights for researchers and practitioners. A systematic summary of existing literature, code, and datasets are open-sourced at \href{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}.
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

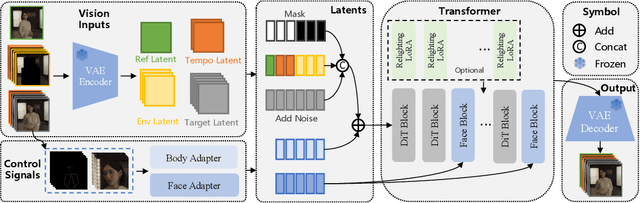
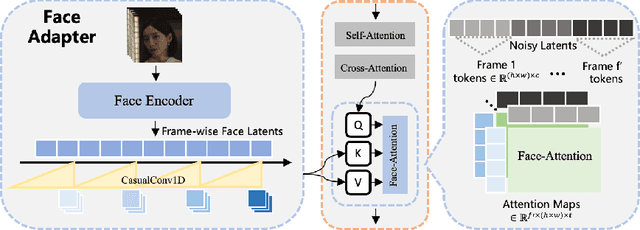
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Make-A-Character: High Quality Text-to-3D Character Generation within Minutes
Dec 24, 2023



There is a growing demand for customized and expressive 3D characters with the emergence of AI agents and Metaverse, but creating 3D characters using traditional computer graphics tools is a complex and time-consuming task. To address these challenges, we propose a user-friendly framework named Make-A-Character (Mach) to create lifelike 3D avatars from text descriptions. The framework leverages the power of large language and vision models for textual intention understanding and intermediate image generation, followed by a series of human-oriented visual perception and 3D generation modules. Our system offers an intuitive approach for users to craft controllable, realistic, fully-realized 3D characters that meet their expectations within 2 minutes, while also enabling easy integration with existing CG pipeline for dynamic expressiveness. For more information, please visit the project page at https://human3daigc.github.io/MACH/.
Reducing Shape-Radiance Ambiguity in Radiance Fields with a Closed-Form Color Estimation Method
Dec 20, 2023Neural radiance field (NeRF) enables the synthesis of cutting-edge realistic novel view images of a 3D scene. It includes density and color fields to model the shape and radiance of a scene, respectively. Supervised by the photometric loss in an end-to-end training manner, NeRF inherently suffers from the shape-radiance ambiguity problem, i.e., it can perfectly fit training views but does not guarantee decoupling the two fields correctly. To deal with this issue, existing works have incorporated prior knowledge to provide an independent supervision signal for the density field, including total variation loss, sparsity loss, distortion loss, etc. These losses are based on general assumptions about the density field, e.g., it should be smooth, sparse, or compact, which are not adaptive to a specific scene. In this paper, we propose a more adaptive method to reduce the shape-radiance ambiguity. The key is a rendering method that is only based on the density field. Specifically, we first estimate the color field based on the density field and posed images in a closed form. Then NeRF's rendering process can proceed. We address the problems in estimating the color field, including occlusion and non-uniformly distributed views. Afterward, it is applied to regularize NeRF's density field. As our regularization is guided by photometric loss, it is more adaptive compared to existing ones. Experimental results show that our method improves the density field of NeRF both qualitatively and quantitatively. Our code is available at https://github.com/qihangGH/Closed-form-color-field.
Masked Space-Time Hash Encoding for Efficient Dynamic Scene Reconstruction
Oct 26, 2023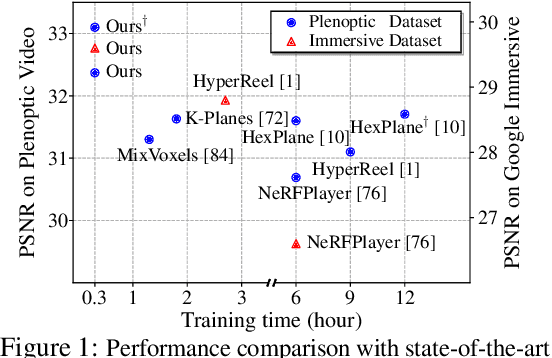
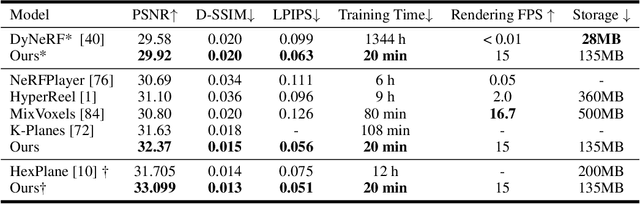


In this paper, we propose the Masked Space-Time Hash encoding (MSTH), a novel method for efficiently reconstructing dynamic 3D scenes from multi-view or monocular videos. Based on the observation that dynamic scenes often contain substantial static areas that result in redundancy in storage and computations, MSTH represents a dynamic scene as a weighted combination of a 3D hash encoding and a 4D hash encoding. The weights for the two components are represented by a learnable mask which is guided by an uncertainty-based objective to reflect the spatial and temporal importance of each 3D position. With this design, our method can reduce the hash collision rate by avoiding redundant queries and modifications on static areas, making it feasible to represent a large number of space-time voxels by hash tables with small size.Besides, without the requirements to fit the large numbers of temporally redundant features independently, our method is easier to optimize and converge rapidly with only twenty minutes of training for a 300-frame dynamic scene.As a result, MSTH obtains consistently better results than previous methods with only 20 minutes of training time and 130 MB of memory storage. Code is available at https://github.com/masked-spacetime-hashing/msth
Evaluate Geometry of Radiance Field with Low-frequency Color Prior
Apr 10, 2023Radiance field is an effective representation of 3D scenes, which has been widely adopted in novel-view synthesis and 3D reconstruction. It is still an open and challenging problem to evaluate the geometry, i.e., the density field, as the ground-truth is almost impossible to be obtained. One alternative indirect solution is to transform the density field into a point-cloud and compute its Chamfer Distance with the scanned ground-truth. However, many widely-used datasets have no point-cloud ground-truth since the scanning process along with the equipment is expensive and complicated. To this end, we propose a novel metric, named Inverse Mean Residual Color (IMRC), which can evaluate the geometry only with the observation images. Our key insight is that the better the geometry is, the lower-frequency the computed color field is. From this insight, given reconstructed density field and the observation images, we design a closed-form method to approximate the color field with low-frequency spherical harmonics and compute the inverse mean residual color. Then the higher the IMRC, the better the geometry. Qualitative and quantitative experimental results verify the effectiveness of our proposed IMRC metric. We also benchmark several state-of-the-art methods using IMRC to promote future related research.
SEKD: Self-Evolving Keypoint Detection and Description
Jun 09, 2020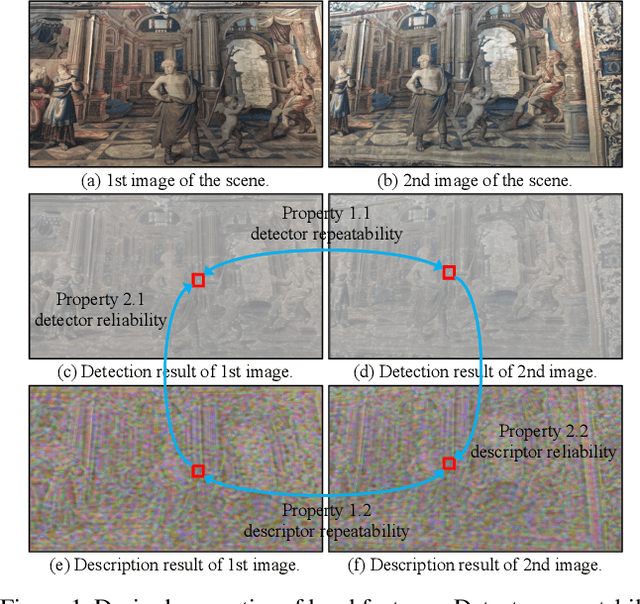
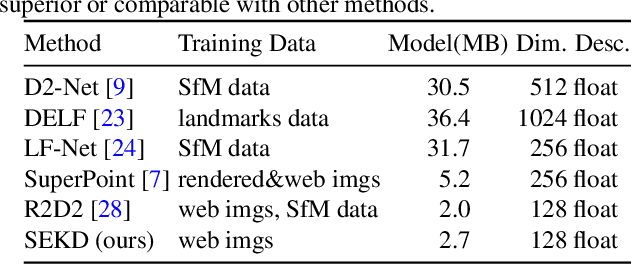
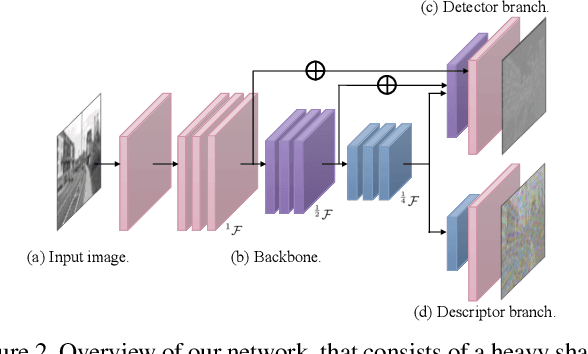
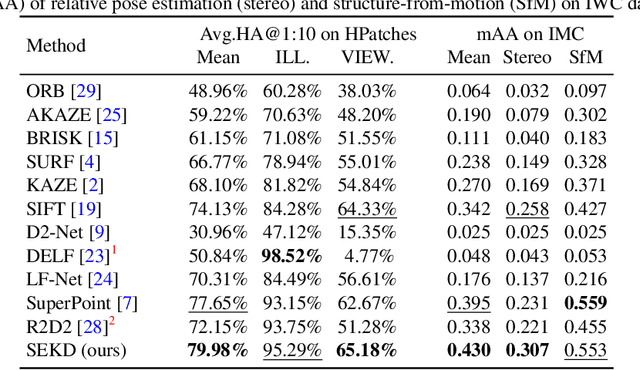
Researchers have attempted utilizing deep neural network (DNN) to learn novel local features from images inspired by its recent successes on a variety of vision tasks. However, existing DNN-based algorithms have not achieved such remarkable progress that could be partly attributed to insufficient utilization of the interactive characters between local feature detector and descriptor. To alleviate these difficulties, we emphasize two desired properties, i.e., repeatability and reliability, to simultaneously summarize the inherent and interactive characters of local feature detector and descriptor. Guided by these properties, a self-supervised framework, namely self-evolving keypoint detection and description (SEKD), is proposed to learn an advanced local feature model from unlabeled natural images. Additionally, to have performance guarantees, novel training strategies have also been dedicatedly designed to minimize the gap between the learned feature and its properties. We benchmark the proposed method on homography estimation, relative pose estimation, and structure-from-motion tasks. Extensive experimental results demonstrate that the proposed method outperforms popular hand-crafted and DNN-based methods by remarkable margins. Ablation studies also verify the effectiveness of each critical training strategy. We will release our code along with the trained model publicly.
Accelerating Neural Network Inference by Overflow Aware Quantization
May 27, 2020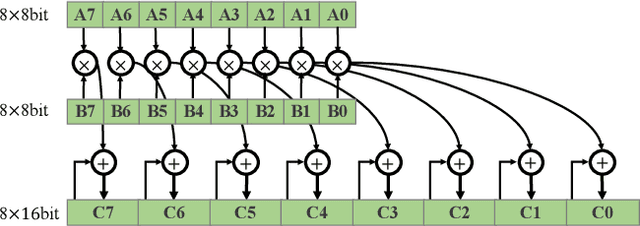
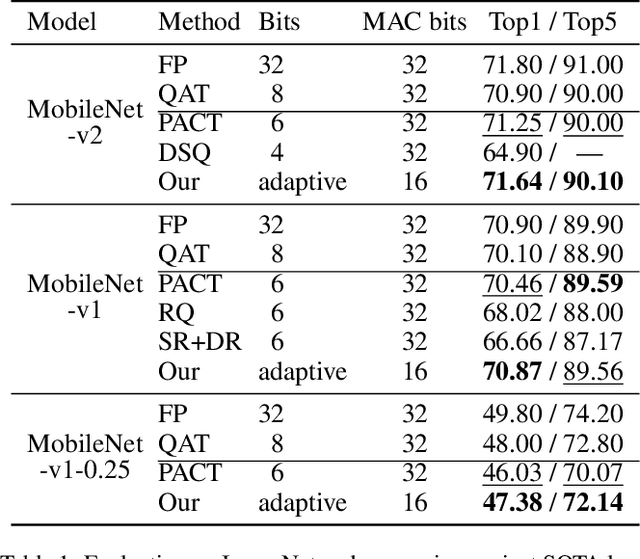
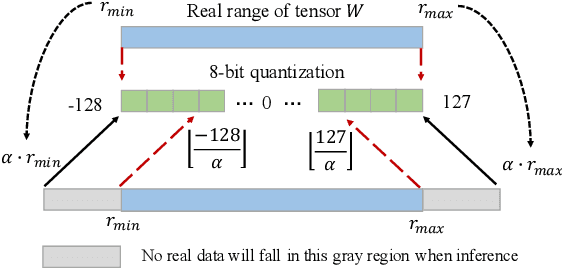
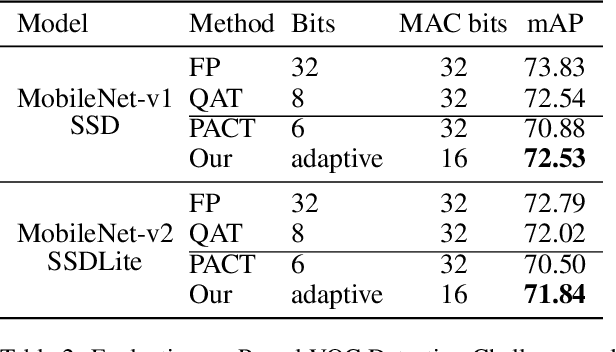
The inherent heavy computation of deep neural networks prevents their widespread applications. A widely used method for accelerating model inference is quantization, by replacing the input operands of a network using fixed-point values. Then the majority of computation costs focus on the integer matrix multiplication accumulation. In fact, high-bit accumulator leads to partially wasted computation and low-bit one typically suffers from numerical overflow. To address this problem, we propose an overflow aware quantization method by designing trainable adaptive fixed-point representation, to optimize the number of bits for each input tensor while prohibiting numeric overflow during the computation. With the proposed method, we are able to fully utilize the computing power to minimize the quantization loss and obtain optimized inference performance. To verify the effectiveness of our method, we conduct image classification, object detection, and semantic segmentation tasks on ImageNet, Pascal VOC, and COCO datasets, respectively. Experimental results demonstrate that the proposed method can achieve comparable performance with state-of-the-art quantization methods while accelerating the inference process by about 2 times.
Single Image Dehazing Using Ranking Convolutional Neural Network
Jan 15, 2020
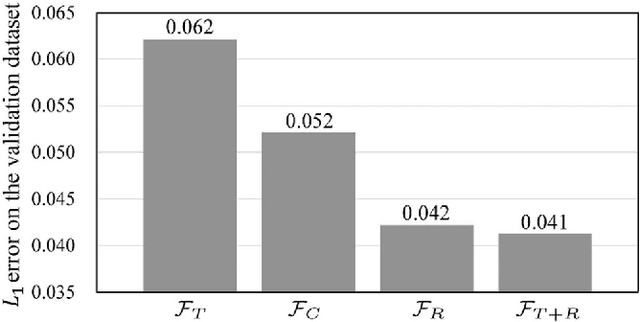
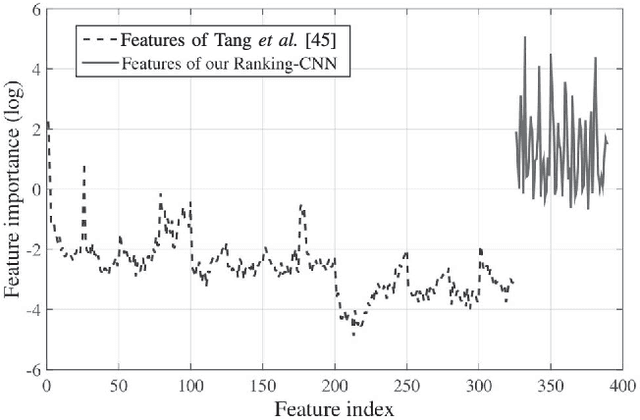
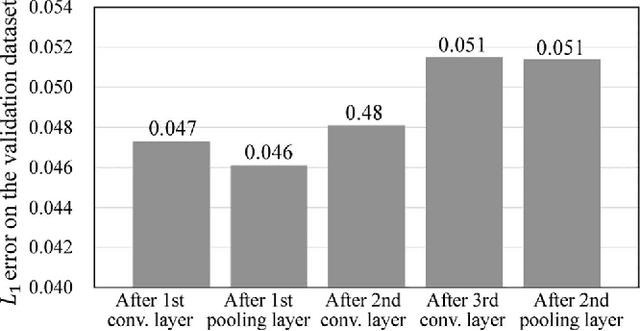
Single image dehazing, which aims to recover the clear image solely from an input hazy or foggy image, is a challenging ill-posed problem. Analysing existing approaches, the common key step is to estimate the haze density of each pixel. To this end, various approaches often heuristically designed haze-relevant features. Several recent works also automatically learn the features via directly exploiting Convolutional Neural Networks (CNN). However, it may be insufficient to fully capture the intrinsic attributes of hazy images. To obtain effective features for single image dehazing, this paper presents a novel Ranking Convolutional Neural Network (Ranking-CNN). In Ranking-CNN, a novel ranking layer is proposed to extend the structure of CNN so that the statistical and structural attributes of hazy images can be simultaneously captured. By training Ranking-CNN in a well-designed manner, powerful haze-relevant features can be automatically learned from massive hazy image patches. Based on these features, haze can be effectively removed by using a haze density prediction model trained through the random forest regression. Experimental results show that our approach outperforms several previous dehazing approaches on synthetic and real-world benchmark images. Comprehensive analyses are also conducted to interpret the proposed Ranking-CNN from both the theoretical and experimental aspects.