 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalRAG: A Retrieval-Augmented LLM Framework for Open-set Malicious Traffic Identification
Nov 18, 2025Fine-grained identification of IDS-flagged suspicious traffic is crucial in cybersecurity. In practice, cyber threats evolve continuously, making the discovery of novel malicious traffic a critical necessity as well as the identification of known classes. Recent studies have advanced this goal with deep models, but they often rely on task-specific architectures that limit transferability and require per-dataset tuning. In this paper we introduce MalRAG, the first LLM driven retrieval-augmented framework for open-set malicious traffic identification. MalRAG freezes the LLM and operates via comprehensive traffic knowledge construction, adaptive retrieval, and prompt engineering. Concretely, we construct a multi-view traffic database by mining prior malicious traffic from content, structural, and temporal perspectives. Furthermore, we introduce a Coverage-Enhanced Retrieval Algorithm that queries across these views to assemble the most probable candidates, thereby improving the inclusion of correct evidence. We then employ Traffic-Aware Adaptive Pruning to select a variable subset of these candidates based on traffic-aware similarity scores, suppressing incorrect matches and yielding reliable retrieved evidence. Moreover, we develop a suite of guidance prompts where task instruction, evidence referencing, and decision guidance are integrated with the retrieved evidence to improve LLM performance. Across diverse real-world datasets and settings, MalRAG delivers state-of-the-art results in both fine-grained identification of known classes and novel malicious traffic discovery. Ablation and deep-dive analyses further show that MalRAG effective leverages LLM capabilities yet achieves open-set malicious traffic identification without relying on a specific LLM.
T2VParser: Adaptive Decomposition Tokens for Partial Alignment in Text to Video Retrieval
Jul 28, 2025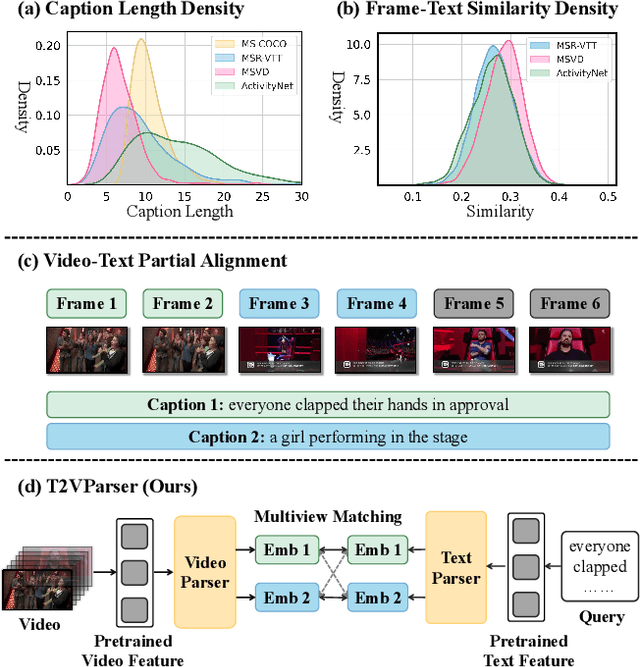
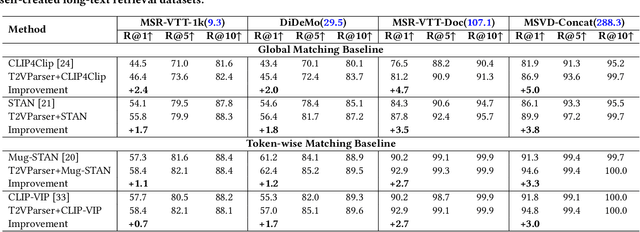
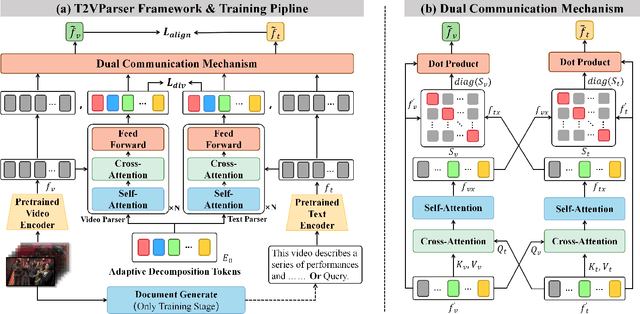
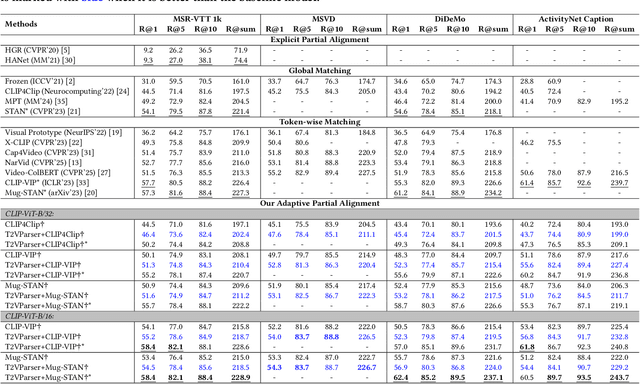
Text-to-video retrieval essentially aims to train models to align visual content with textual descriptions accurately. Due to the impressive general multimodal knowledge demonstrated by image-text pretrained models such as CLIP, existing work has primarily focused on extending CLIP knowledge for video-text tasks. However, videos typically contain richer information than images. In current video-text datasets, textual descriptions can only reflect a portion of the video content, leading to partial misalignment in video-text matching. Therefore, directly aligning text representations with video representations can result in incorrect supervision, ignoring the inequivalence of information. In this work, we propose T2VParser to extract multiview semantic representations from text and video, achieving adaptive semantic alignment rather than aligning the entire representation. To extract corresponding representations from different modalities, we introduce Adaptive Decomposition Tokens, which consist of a set of learnable tokens shared across modalities. The goal of T2VParser is to emphasize precise alignment between text and video while retaining the knowledge of pretrained models. Experimental results demonstrate that T2VParser achieves accurate partial alignment through effective cross-modal content decomposition. The code is available at https://github.com/Lilidamowang/T2VParser.
Respond to Change with Constancy: Instruction-tuning with LLM for Non-I.I.D. Network Traffic Classification
May 27, 2025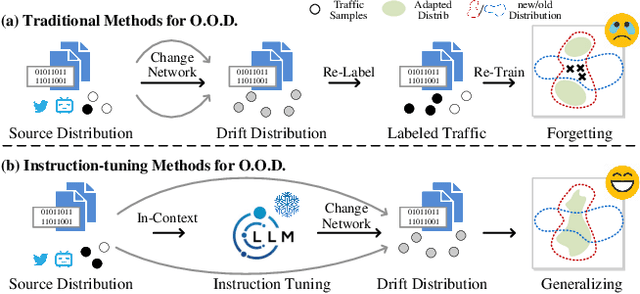
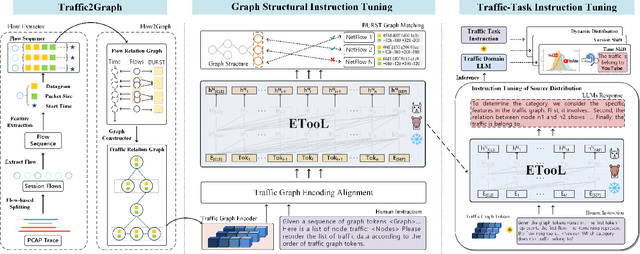
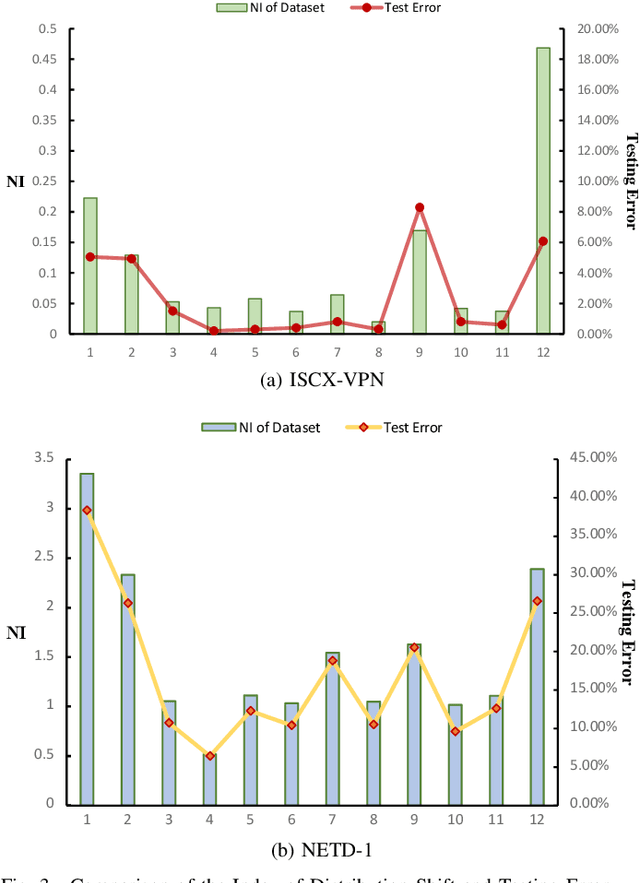
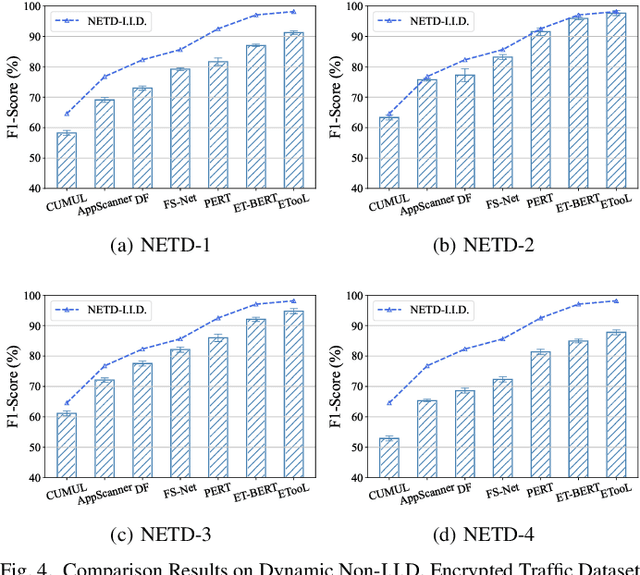
Encrypted traffic classification is highly challenging in network security due to the need for extracting robust features from content-agnostic traffic data. Existing approaches face critical issues: (i) Distribution drift, caused by reliance on the closedworld assumption, limits adaptability to realworld, shifting patterns; (ii) Dependence on labeled data restricts applicability where such data is scarce or unavailable. Large language models (LLMs) have demonstrated remarkable potential in offering generalizable solutions across a wide range of tasks, achieving notable success in various specialized fields. However, their effectiveness in traffic analysis remains constrained by challenges in adapting to the unique requirements of the traffic domain. In this paper, we introduce a novel traffic representation model named Encrypted Traffic Out-of-Distribution Instruction Tuning with LLM (ETooL), which integrates LLMs with knowledge of traffic structures through a self-supervised instruction tuning paradigm. This framework establishes connections between textual information and traffic interactions. ETooL demonstrates more robust classification performance and superior generalization in both supervised and zero-shot traffic classification tasks. Notably, it achieves significant improvements in F1 scores: APP53 (I.I.D.) to 93.19%(6.62%) and 92.11%(4.19%), APP53 (O.O.D.) to 74.88%(18.17%) and 72.13%(15.15%), and ISCX-Botnet (O.O.D.) to 95.03%(9.16%) and 81.95%(12.08%). Additionally, we construct NETD, a traffic dataset designed to support dynamic distributional shifts, and use it to validate ETooL's effectiveness under varying distributional conditions. Furthermore, we evaluate the efficiency gains achieved through ETooL's instruction tuning approach.
Feasibility-Aware Pessimistic Estimation: Toward Long-Horizon Safety in Offline RL
May 13, 2025Offline safe reinforcement learning(OSRL) derives constraint-satisfying policies from pre-collected datasets, offers a promising avenue for deploying RL in safety-critical real-world domains such as robotics. However, the majority of existing approaches emphasize only short-term safety, neglecting long-horizon considerations. Consequently, they may violate safety constraints and fail to ensure sustained protection during online deployment. Moreover, the learned policies often struggle to handle states and actions that are not present or out-of-distribution(OOD) from the offline dataset, and exhibit limited sample efficiency. To address these challenges, we propose a novel framework Feasibility-Aware offline Safe Reinforcement Learning with CVAE-based Pessimism (FASP). First, we employ Hamilton-Jacobi (H-J) reachability analysis to generate reliable safety labels, which serve as supervisory signals for training both a conditional variational autoencoder (CVAE) and a safety classifier. This approach not only ensures high sampling efficiency but also provides rigorous long-horizon safety guarantees. Furthermore, we utilize pessimistic estimation methods to estimate the Q-value of reward and cost, which mitigates the extrapolation errors induces by OOD actions, and penalize unsafe actions to enabled the agent to proactively avoid high-risk behaviors. Moreover, we theoretically prove the validity of this pessimistic estimation. Extensive experiments on DSRL benchmarks demonstrate that FASP algorithm achieves competitive performance across multiple experimental tasks, particularly outperforming state-of-the-art algorithms in terms of safety.
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
Apr 21, 2025



Process reward models (PRMs) have proven effective for test-time scaling of Large Language Models (LLMs) on challenging reasoning tasks. However, reward hacking issues with PRMs limit their successful application in reinforcement fine-tuning. In this paper, we identify the main cause of PRM-induced reward hacking: the canonical summation-form credit assignment in reinforcement learning (RL), which defines the value as cumulative gamma-decayed future rewards, easily induces LLMs to hack steps with high rewards. To address this, we propose PURE: Process sUpervised Reinforcement lEarning. The key innovation of PURE is a min-form credit assignment that formulates the value function as the minimum of future rewards. This method significantly alleviates reward hacking by limiting the value function range and distributing advantages more reasonably. Through extensive experiments on 3 base models, we show that PRM-based approaches enabling min-form credit assignment achieve comparable reasoning performance to verifiable reward-based methods within only 30% steps. In contrast, the canonical sum-form credit assignment collapses training even at the beginning! Additionally, when we supplement PRM-based fine-tuning with just 10% verifiable rewards, we further alleviate reward hacking and produce the best fine-tuned model based on Qwen2.5-Math-7B in our experiments, achieving 82.5% accuracy on AMC23 and 53.3% average accuracy across 5 benchmarks. Moreover, we summarize the observed reward hacking cases and analyze the causes of training collapse. Code and models are available at https://github.com/CJReinforce/PURE.
Missing Target-Relevant Information Prediction with World Model for Accurate Zero-Shot Composed Image Retrieval
Mar 21, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) involves diverse tasks with a broad range of visual content manipulation intent across domain, scene, object, and attribute. The key challenge for ZS-CIR tasks is to modify a reference image according to manipulation text to accurately retrieve a target image, especially when the reference image is missing essential target content. In this paper, we propose a novel prediction-based mapping network, named PrediCIR, to adaptively predict the missing target visual content in reference images in the latent space before mapping for accurate ZS-CIR. Specifically, a world view generation module first constructs a source view by omitting certain visual content of a target view, coupled with an action that includes the manipulation intent derived from existing image-caption pairs. Then, a target content prediction module trains a world model as a predictor to adaptively predict the missing visual information guided by user intention in manipulating text at the latent space. The two modules map an image with the predicted relevant information to a pseudo-word token without extra supervision. Our model shows strong generalization ability on six ZS-CIR tasks. It obtains consistent and significant performance boosts ranging from 1.73% to 4.45% over the best methods and achieves new state-of-the-art results on ZS-CIR. Our code is available at https://github.com/Pter61/predicir.
MADS: Multi-Attribute Document Supervision for Zero-Shot Image Classification
Mar 10, 2025Zero-shot learning (ZSL) aims to train a model on seen classes and recognize unseen classes by knowledge transfer through shared auxiliary information. Recent studies reveal that documents from encyclopedias provide helpful auxiliary information. However, existing methods align noisy documents, entangled in visual and non-visual descriptions, with image regions, yet solely depend on implicit learning. These models fail to filter non-visual noise reliably and incorrectly align non-visual words to image regions, which is harmful to knowledge transfer. In this work, we propose a novel multi-attribute document supervision framework to remove noises at both document collection and model learning stages. With the help of large language models, we introduce a novel prompt algorithm that automatically removes non-visual descriptions and enriches less-described documents in multiple attribute views. Our proposed model, MADS, extracts multi-view transferable knowledge with information decoupling and semantic interactions for semantic alignment at local and global levels. Besides, we introduce a model-agnostic focus loss to explicitly enhance attention to visually discriminative information during training, also improving existing methods without additional parameters. With comparable computation costs, MADS consistently outperforms the SOTA by 7.2% and 8.2% on average in three benchmarks for document-based ZSL and GZSL settings, respectively. Moreover, we qualitatively offer interpretable predictions from multiple attribute views.
ProAPO: Progressively Automatic Prompt Optimization for Visual Classification
Feb 27, 2025
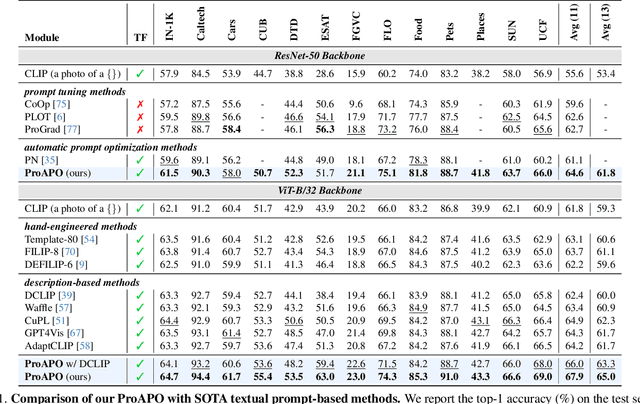
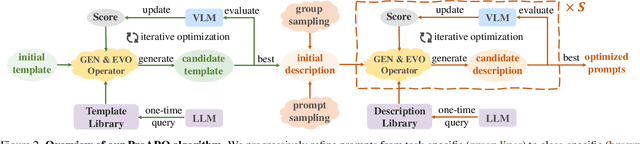
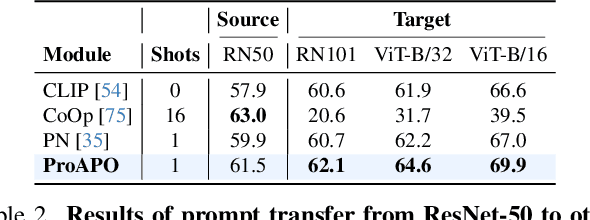
Vision-language models (VLMs) have made significant progress in image classification by training with large-scale paired image-text data. Their performances largely depend on the prompt quality. While recent methods show that visual descriptions generated by large language models (LLMs) enhance the generalization of VLMs, class-specific prompts may be inaccurate or lack discrimination due to the hallucination in LLMs. In this paper, we aim to find visually discriminative prompts for fine-grained categories with minimal supervision and no human-in-the-loop. An evolution-based algorithm is proposed to progressively optimize language prompts from task-specific templates to class-specific descriptions. Unlike optimizing templates, the search space shows an explosion in class-specific candidate prompts. This increases prompt generation costs, iterative times, and the overfitting problem. To this end, we first introduce several simple yet effective edit-based and evolution-based operations to generate diverse candidate prompts by one-time query of LLMs. Then, two sampling strategies are proposed to find a better initial search point and reduce traversed categories, saving iteration costs. Moreover, we apply a novel fitness score with entropy constraints to mitigate overfitting. In a challenging one-shot image classification setting, our method outperforms existing textual prompt-based methods and improves LLM-generated description methods across 13 datasets. Meanwhile, we demonstrate that our optimal prompts improve adapter-based methods and transfer effectively across different backbones.
Reason-before-Retrieve: One-Stage Reflective Chain-of-Thoughts for Training-Free Zero-Shot Composed Image Retrieval
Dec 15, 2024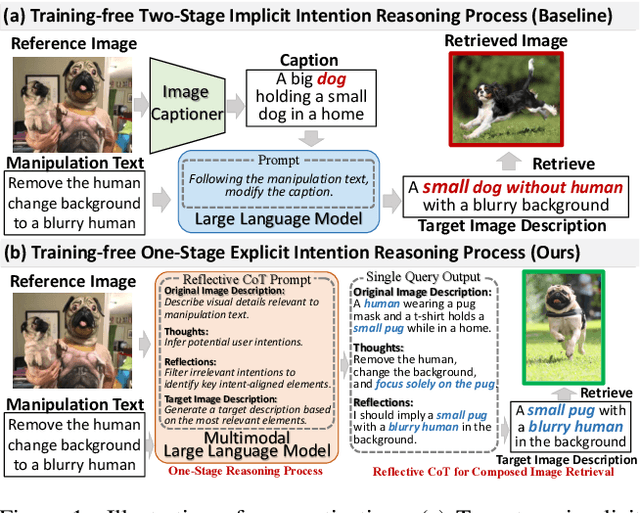
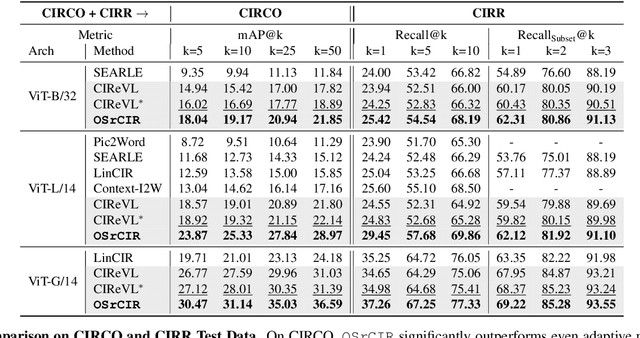
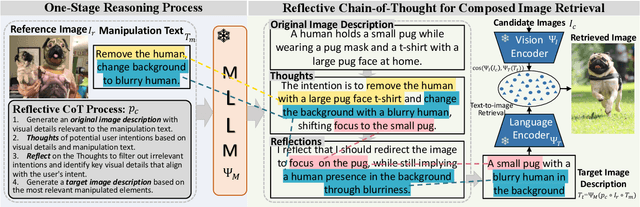
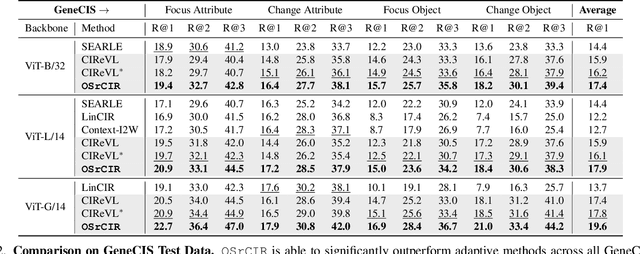
Composed Image Retrieval (CIR) aims to retrieve target images that closely resemble a reference image while integrating user-specified textual modifications, thereby capturing user intent more precisely. Existing training-free zero-shot CIR (ZS-CIR) methods often employ a two-stage process: they first generate a caption for the reference image and then use Large Language Models for reasoning to obtain a target description. However, these methods suffer from missing critical visual details and limited reasoning capabilities, leading to suboptimal retrieval performance. To address these challenges, we propose a novel, training-free one-stage method, One-Stage Reflective Chain-of-Thought Reasoning for ZS-CIR (OSrCIR), which employs Multimodal Large Language Models to retain essential visual information in a single-stage reasoning process, eliminating the information loss seen in two-stage methods. Our Reflective Chain-of-Thought framework further improves interpretative accuracy by aligning manipulation intent with contextual cues from reference images. OSrCIR achieves performance gains of 1.80% to 6.44% over existing training-free methods across multiple tasks, setting new state-of-the-art results in ZS-CIR and enhancing its utility in vision-language applications. Our code will be available at https://github.com/Pter61/osrcir2024/.
Denoise-I2W: Mapping Images to Denoising Words for Accurate Zero-Shot Composed Image Retrieval
Oct 22, 2024



Zero-Shot Composed Image Retrieval (ZS-CIR) supports diverse tasks with a broad range of visual content manipulation intentions that can be related to domain, scene, object, and attribute. A key challenge for ZS-CIR is to accurately map image representation to a pseudo-word token that captures the manipulation intention relevant image information for generalized CIR. However, existing methods between the retrieval and pre-training stages lead to significant redundancy in the pseudo-word tokens. In this paper, we propose a novel denoising image-to-word mapping approach, named Denoise-I2W, for mapping images into denoising pseudo-word tokens that, without intention-irrelevant visual information, enhance accurate ZS-CIR. Specifically, a pseudo triplet construction module first automatically constructs pseudo triples (\textit{i.e.,} a pseudo-reference image, a pseudo-manipulation text, and a target image) for pre-training the denoising mapping network. Then, a pseudo-composed mapping module maps the pseudo-reference image to a pseudo-word token and combines it with the pseudo-manipulation text with manipulation intention. This combination aligns with the target image, facilitating denoising intention-irrelevant visual information for mapping. Our proposed Denoise-I2W is a model-agnostic and annotation-free approach. It demonstrates strong generalization capabilities across three state-of-the-art ZS-CIR models on four benchmark datasets. By integrating Denoise-I2W with existing best models, we obtain consistent and significant performance boosts ranging from 1.45\% to 4.17\% over the best methods without increasing inference costs. and achieve new state-of-the-art results on ZS-CIR. Our code is available at \url{https://github.com/Pter61/denoise-i2w-tmm}.