 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: A Cognitive Load Framework for Mapping the Capability Boundaries of Tool-use Agents
Jan 28, 2026The ability of Large Language Models (LLMs) to use external tools unlocks powerful real-world interactions, making rigorous evaluation essential. However, current benchmarks primarily report final accuracy, revealing what models can do but obscuring the cognitive bottlenecks that define their true capability boundaries. To move from simple performance scoring to a diagnostic tool, we introduce a framework grounded in Cognitive Load Theory. Our framework deconstructs task complexity into two quantifiable components: Intrinsic Load, the inherent structural complexity of the solution path, formalized with a novel Tool Interaction Graph; and Extraneous Load, the difficulty arising from ambiguous task presentation. To enable controlled experiments, we construct ToolLoad-Bench, the first benchmark with parametrically adjustable cognitive load. Our evaluation reveals distinct performance cliffs as cognitive load increases, allowing us to precisely map each model's capability boundary. We validate that our framework's predictions are highly calibrated with empirical results, establishing a principled methodology for understanding an agent's limits and a practical foundation for building more efficient systems.
Missing Target-Relevant Information Prediction with World Model for Accurate Zero-Shot Composed Image Retrieval
Mar 21, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) involves diverse tasks with a broad range of visual content manipulation intent across domain, scene, object, and attribute. The key challenge for ZS-CIR tasks is to modify a reference image according to manipulation text to accurately retrieve a target image, especially when the reference image is missing essential target content. In this paper, we propose a novel prediction-based mapping network, named PrediCIR, to adaptively predict the missing target visual content in reference images in the latent space before mapping for accurate ZS-CIR. Specifically, a world view generation module first constructs a source view by omitting certain visual content of a target view, coupled with an action that includes the manipulation intent derived from existing image-caption pairs. Then, a target content prediction module trains a world model as a predictor to adaptively predict the missing visual information guided by user intention in manipulating text at the latent space. The two modules map an image with the predicted relevant information to a pseudo-word token without extra supervision. Our model shows strong generalization ability on six ZS-CIR tasks. It obtains consistent and significant performance boosts ranging from 1.73% to 4.45% over the best methods and achieves new state-of-the-art results on ZS-CIR. Our code is available at https://github.com/Pter61/predicir.
Reason-before-Retrieve: One-Stage Reflective Chain-of-Thoughts for Training-Free Zero-Shot Composed Image Retrieval
Dec 15, 2024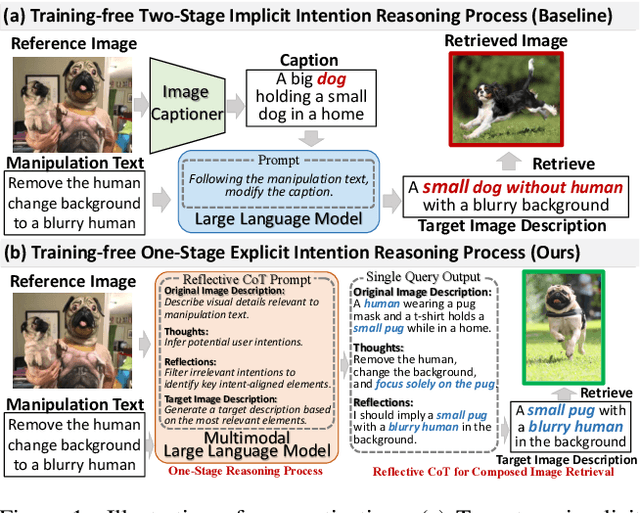
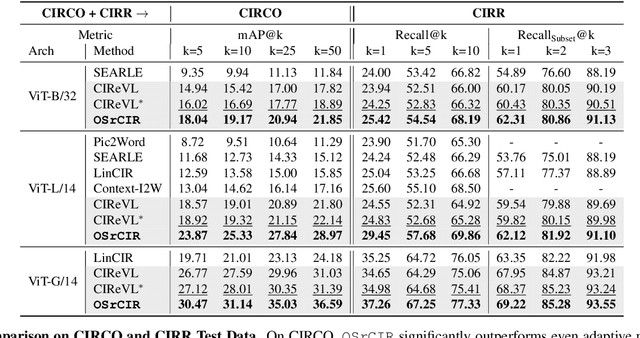
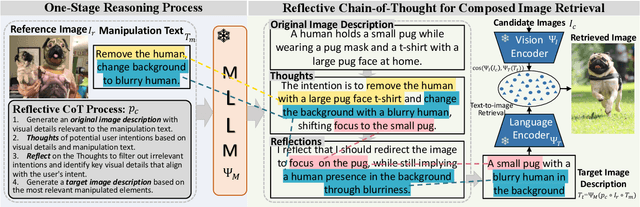
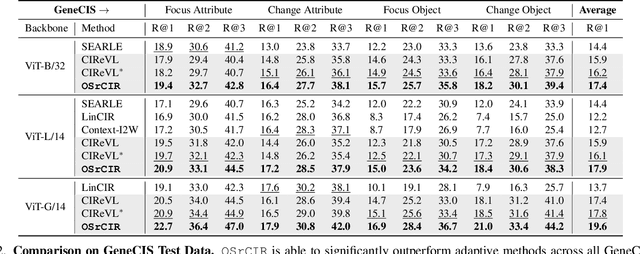
Composed Image Retrieval (CIR) aims to retrieve target images that closely resemble a reference image while integrating user-specified textual modifications, thereby capturing user intent more precisely. Existing training-free zero-shot CIR (ZS-CIR) methods often employ a two-stage process: they first generate a caption for the reference image and then use Large Language Models for reasoning to obtain a target description. However, these methods suffer from missing critical visual details and limited reasoning capabilities, leading to suboptimal retrieval performance. To address these challenges, we propose a novel, training-free one-stage method, One-Stage Reflective Chain-of-Thought Reasoning for ZS-CIR (OSrCIR), which employs Multimodal Large Language Models to retain essential visual information in a single-stage reasoning process, eliminating the information loss seen in two-stage methods. Our Reflective Chain-of-Thought framework further improves interpretative accuracy by aligning manipulation intent with contextual cues from reference images. OSrCIR achieves performance gains of 1.80% to 6.44% over existing training-free methods across multiple tasks, setting new state-of-the-art results in ZS-CIR and enhancing its utility in vision-language applications. Our code will be available at https://github.com/Pter61/osrcir2024/.
Denoise-I2W: Mapping Images to Denoising Words for Accurate Zero-Shot Composed Image Retrieval
Oct 22, 2024



Zero-Shot Composed Image Retrieval (ZS-CIR) supports diverse tasks with a broad range of visual content manipulation intentions that can be related to domain, scene, object, and attribute. A key challenge for ZS-CIR is to accurately map image representation to a pseudo-word token that captures the manipulation intention relevant image information for generalized CIR. However, existing methods between the retrieval and pre-training stages lead to significant redundancy in the pseudo-word tokens. In this paper, we propose a novel denoising image-to-word mapping approach, named Denoise-I2W, for mapping images into denoising pseudo-word tokens that, without intention-irrelevant visual information, enhance accurate ZS-CIR. Specifically, a pseudo triplet construction module first automatically constructs pseudo triples (\textit{i.e.,} a pseudo-reference image, a pseudo-manipulation text, and a target image) for pre-training the denoising mapping network. Then, a pseudo-composed mapping module maps the pseudo-reference image to a pseudo-word token and combines it with the pseudo-manipulation text with manipulation intention. This combination aligns with the target image, facilitating denoising intention-irrelevant visual information for mapping. Our proposed Denoise-I2W is a model-agnostic and annotation-free approach. It demonstrates strong generalization capabilities across three state-of-the-art ZS-CIR models on four benchmark datasets. By integrating Denoise-I2W with existing best models, we obtain consistent and significant performance boosts ranging from 1.45\% to 4.17\% over the best methods without increasing inference costs. and achieve new state-of-the-art results on ZS-CIR. Our code is available at \url{https://github.com/Pter61/denoise-i2w-tmm}.
Visual-Semantic Decomposition and Partial Alignment for Document-based Zero-Shot Learning
Jul 23, 2024
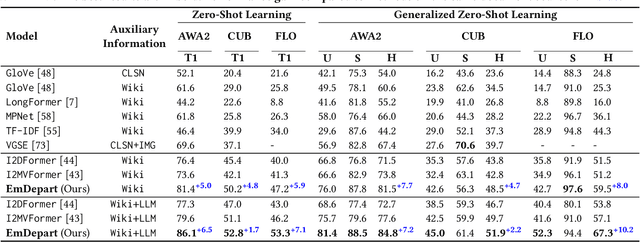
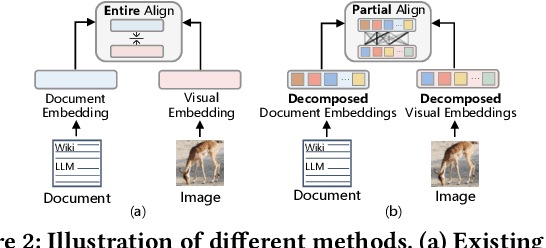
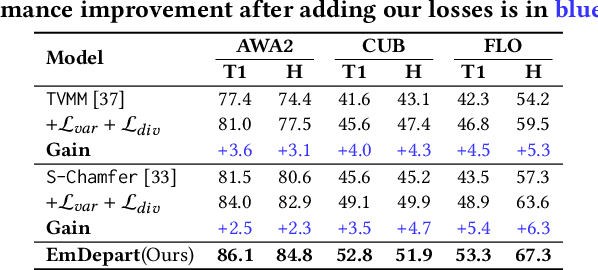
Recent work shows that documents from encyclopedias serve as helpful auxiliary information for zero-shot learning. Existing methods align the entire semantics of a document with corresponding images to transfer knowledge. However, they disregard that semantic information is not equivalent between them, resulting in a suboptimal alignment. In this work, we propose a novel network to extract multi-view semantic concepts from documents and images and align the matching rather than entire concepts. Specifically, we propose a semantic decomposition module to generate multi-view semantic embeddings from visual and textual sides, providing the basic concepts for partial alignment. To alleviate the issue of information redundancy among embeddings, we propose the local-to-semantic variance loss to capture distinct local details and multiple semantic diversity loss to enforce orthogonality among embeddings. Subsequently, two losses are introduced to partially align visual-semantic embedding pairs according to their semantic relevance at the view and word-to-patch levels. Consequently, we consistently outperform state-of-the-art methods under two document sources in three standard benchmarks for document-based zero-shot learning. Qualitatively, we show that our model learns the interpretable partial association.
Watermarking Vision-Language Pre-trained Models for Multi-modal Embedding as a Service
Nov 10, 2023



Recent advances in vision-language pre-trained models (VLPs) have significantly increased visual understanding and cross-modal analysis capabilities. Companies have emerged to provide multi-modal Embedding as a Service (EaaS) based on VLPs (e.g., CLIP-based VLPs), which cost a large amount of training data and resources for high-performance service. However, existing studies indicate that EaaS is vulnerable to model extraction attacks that induce great loss for the owners of VLPs. Protecting the intellectual property and commercial ownership of VLPs is increasingly crucial yet challenging. A major solution of watermarking model for EaaS implants a backdoor in the model by inserting verifiable trigger embeddings into texts, but it is only applicable for large language models and is unrealistic due to data and model privacy. In this paper, we propose a safe and robust backdoor-based embedding watermarking method for VLPs called VLPMarker. VLPMarker utilizes embedding orthogonal transformation to effectively inject triggers into the VLPs without interfering with the model parameters, which achieves high-quality copyright verification and minimal impact on model performance. To enhance the watermark robustness, we further propose a collaborative copyright verification strategy based on both backdoor trigger and embedding distribution, enhancing resilience against various attacks. We increase the watermark practicality via an out-of-distribution trigger selection approach, removing access to the model training data and thus making it possible for many real-world scenarios. Our extensive experiments on various datasets indicate that the proposed watermarking approach is effective and safe for verifying the copyright of VLPs for multi-modal EaaS and robust against model extraction attacks. Our code is available at https://github.com/Pter61/vlpmarker.
Align before Search: Aligning Ads Image to Text for Accurate Cross-Modal Sponsored Search
Sep 28, 2023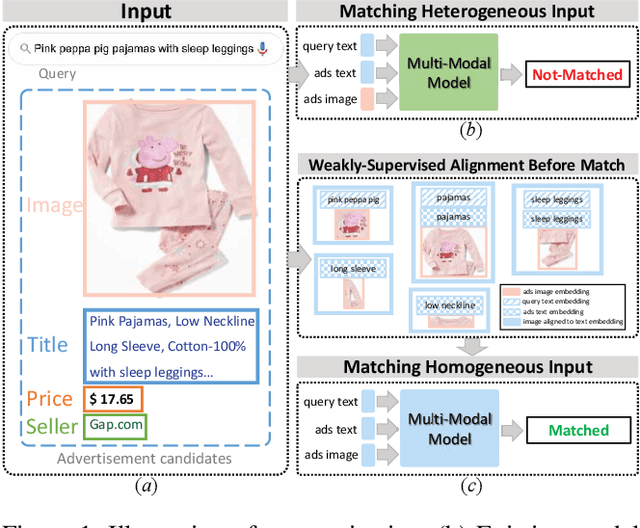
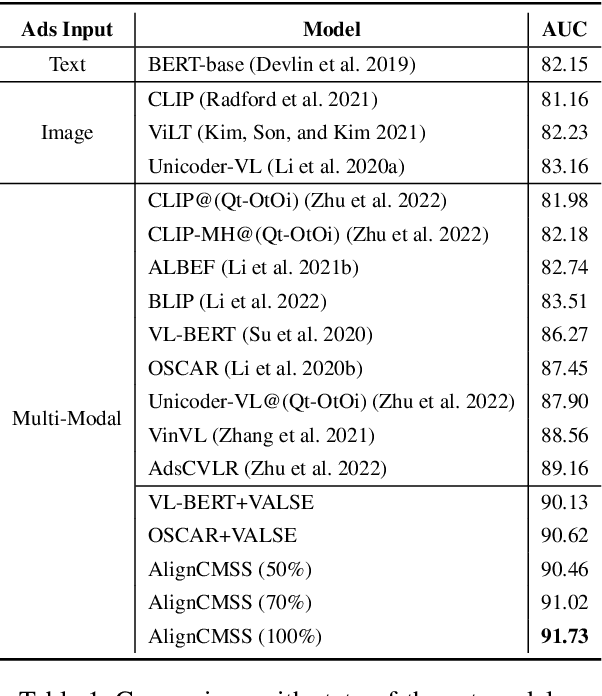
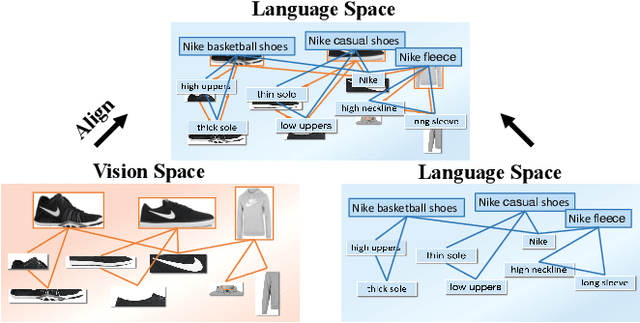
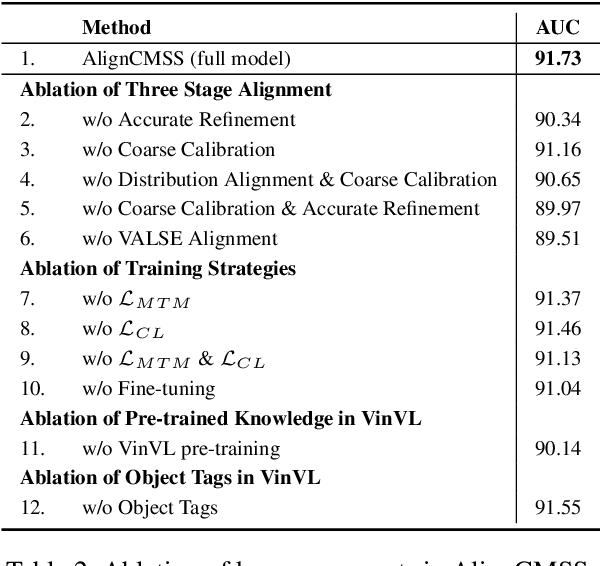
Cross-Modal sponsored search displays multi-modal advertisements (ads) when consumers look for desired products by natural language queries in search engines. Since multi-modal ads bring complementary details for query-ads matching, the ability to align ads-specific information in both images and texts is crucial for accurate and flexible sponsored search. Conventional research mainly studies from the view of modeling the implicit correlations between images and texts for query-ads matching, ignoring the alignment of detailed product information and resulting in suboptimal search performance.In this work, we propose a simple alignment network for explicitly mapping fine-grained visual parts in ads images to the corresponding text, which leverages the co-occurrence structure consistency between vision and language spaces without requiring expensive labeled training data. Moreover, we propose a novel model for cross-modal sponsored search that effectively conducts the cross-modal alignment and query-ads matching in two separate processes. In this way, the model matches the multi-modal input in the same language space, resulting in a superior performance with merely half of the training data. Our model outperforms the state-of-the-art models by 2.57% on a large commercial dataset. Besides sponsored search, our alignment method is applicable for general cross-modal search. We study a typical cross-modal retrieval task on the MSCOCO dataset, which achieves consistent performance improvement and proves the generalization ability of our method. Our code is available at https://github.com/Pter61/AlignCMSS/
Context-I2W: Mapping Images to Context-dependent Words for Accurate Zero-Shot Composed Image Retrieval
Sep 28, 2023Different from Composed Image Retrieval task that requires expensive labels for training task-specific models, Zero-Shot Composed Image Retrieval (ZS-CIR) involves diverse tasks with a broad range of visual content manipulation intent that could be related to domain, scene, object, and attribute. The key challenge for ZS-CIR tasks is to learn a more accurate image representation that has adaptive attention to the reference image for various manipulation descriptions. In this paper, we propose a novel context-dependent mapping network, named Context-I2W, for adaptively converting description-relevant Image information into a pseudo-word token composed of the description for accurate ZS-CIR. Specifically, an Intent View Selector first dynamically learns a rotation rule to map the identical image to a task-specific manipulation view. Then a Visual Target Extractor further captures local information covering the main targets in ZS-CIR tasks under the guidance of multiple learnable queries. The two complementary modules work together to map an image to a context-dependent pseudo-word token without extra supervision. Our model shows strong generalization ability on four ZS-CIR tasks, including domain conversion, object composition, object manipulation, and attribute manipulation. It obtains consistent and significant performance boosts ranging from 1.88% to 3.60% over the best methods and achieves new state-of-the-art results on ZS-CIR. Our code is available at https://github.com/Pter61/context_i2w.