 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Chunk-Local Extraction: Cross-Chunk Graph Augmentation for GraphRAG
May 27, 2026GraphRAG extends retrieval-augmented generation by organizing corpora as explicit knowledge graphs, enabling graph-based retrieval for complex question answering. However, existing frameworks extract entities and relations within individual chunks, leaving cross-chunk relations -- those whose evidence spans multiple passages -- systematically absent from the index. Exhaustive LLM-based recovery of such relations is impractical due to the combinatorial explosion of chunk combinations. We present CrossAug, a GNN-guided CROSS-Chunk Graph AUGmentation method that enriches GraphRAG indices with cross-chunk relational structure as an offline step before query-time retrieval. CrossAug derives training supervision through self-supervised graph corruption, uses a topology-aware GNN to score subgraphs for missingness, and applies evidence-grounded LLM completion only to selected high-scoring regions. Experiments on three LLM-based GraphRAG frameworks across four multi-hop and long-document QA benchmarks demonstrate that CrossAug consistently improves performance, confirming the benefit of cross-chunk graph augmentation for retrieval-based question answering. Our code is available at https://github.com/DonFinliani/CrossAug.
CrossCult-KIBench: A Benchmark for Cross-Cultural Knowledge Insertion in MLLMs
May 07, 2026Multimodal Large Language Models (MLLMs), trained primarily on English-centric data, frequently generate culturally inappropriate or misaligned responses in cross-cultural settings. To mitigate this, we introduce the task of cross-cultural knowledge insertion, which focuses on adapting models to specific cultural contexts while preserving their original behavior in other cultures. To facilitate research in this area, we introduce CrossCult-KIBench, a comprehensive evaluation benchmark for assessing both the effectiveness of knowledge insertion and its unintended side effects on non-target cultures. The benchmark includes 9,800 image-grounded cases covering 49 culturally relevant visual scenarios across English, Chinese, and Arabic language-culture groups. It supports evaluation in both single-insert and sequential-insert settings. We also propose Memory-Conditioned Knowledge Insertion (MCKI) as a baseline method. MCKI retrieves relevant cultural knowledge from an external memory using frozen MLLM representations, prepending matched entries as conditional prompts when applicable. Extensive experiments on CrossCult-KIBench reveal that current approaches struggle to balance effective cultural adaptation with behavioral preservation, highlighting a key challenge in developing culturally-aware MLLMs. Our work thus underscores an important research direction for developing more culturally adaptive and responsible MLLMs.
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Apr 06, 2026Current document parsing methods compete primarily on model architecture innovation, while systematic engineering of training data remains underexplored. Yet SOTA models of different architectures and parameter scales exhibit highly consistent failure patterns on the same set of hard samples, suggesting that the performance bottleneck stems from shared deficiencies in training data rather than architecture itself. Building on this finding, we present \minerupro, which advances the state of the art solely through data engineering and training strategy optimization while keeping the 1.2B-parameter architecture of \mineru completely fixed. At its core is a Data Engine co-designed around coverage, informativeness, and annotation accuracy: Diversity-and-Difficulty-Aware Sampling expands training data from under 10M to 65.5M samples while correcting distribution shift; Cross-Model Consistency Verification leverages output agreement among heterogeneous models to assess sample difficulty and generate reliable annotations; the Judge-and-Refine pipeline improves annotation quality for hard samples through render-then-verify iterative correction. A three-stage progressive training strategy -- large-scale pre-training, hard sample fine-tuning, and GRPO alignment -- sequentially exploits these data at different quality tiers. On the evaluation front, we fix element-matching biases in OmniDocBench~v1.5 and introduce a Hard subset, establishing the more discriminative OmniDocBench~v1.6 protocol. Without any architectural modification, \minerupro achieves 95.69 on OmniDocBench~v1.6, improving over the same-architecture baseline by 2.71 points and surpassing all existing methods including models with over 200$\times$ more parameters.
Achieving $\widetilde{O}(1/ε)$ Sample Complexity for Bilinear Systems Identification under Bounded Noises
Mar 21, 2026This paper studies finite-sample set-membership identification for discrete-time bilinear systems under bounded symmetric log-concave disturbances. Compared with existing finite-sample results for linear systems and related analyses under stronger noise assumptions, we consider the more challenging bilinear setting with trajectory-dependent regressors and allow marginally stable dynamics with polynomial mean-square state growth. Under these conditions, we prove that the diameter of the feasible parameter set shrinks with sample complexity $\widetilde{O}(1/ε)$. Simulation supports the theory and illustrates the advantage of the proposed estimator for uncertainty quantification.
ALIEN: Analytic Latent Watermarking for Controllable Generation
Feb 05, 2026Watermarking is a technical alternative to safeguarding intellectual property and reducing misuse. Existing methods focus on optimizing watermarked latent variables to balance watermark robustness and fidelity, as Latent diffusion models (LDMs) are considered a powerful tool for generative tasks. However, reliance on computationally intensive heuristic optimization for iterative signal refinement results in high training overhead and local optima entrapment.To address these issues, we propose an \underline{A}na\underline{l}ytical Watermark\underline{i}ng Framework for Controllabl\underline{e} Generatio\underline{n} (ALIEN). We develop the first analytical derivation of the time-dependent modulation coefficient that guides the diffusion of watermark residuals to achieve controllable watermark embedding pattern.Experimental results show that ALIEN-Q outperforms the state-of-the-art by 33.1\% across 5 quality metrics, and ALIEN-R demonstrates 14.0\% improved robustness against generative variant and stability threats compared to the state-of-the-art across 15 distinct conditions. Code can be available at https://anonymous.4open.science/r/ALIEN/.
YOLO-DS: Fine-Grained Feature Decoupling via Dual-Statistic Synergy Operator for Object Detection
Jan 26, 2026One-stage object detection, particularly the YOLO series, strikes a favorable balance between accuracy and efficiency. However, existing YOLO detectors lack explicit modeling of heterogeneous object responses within shared feature channels, which limits further performance gains. To address this, we propose YOLO-DS, a framework built around a novel Dual-Statistic Synergy Operator (DSO). The DSO decouples object features by jointly modeling the channel-wise mean and the peak-to-mean difference. Building upon the DSO, we design two lightweight gating modules: the Dual-Statistic Synergy Gating (DSG) module for adaptive channel-wise feature selection, and the Multi-Path Segmented Gating (MSG) module for depth-wise feature weighting. On the MS-COCO benchmark, YOLO-DS consistently outperforms YOLOv8 across five model scales (N, S, M, L, X), achieving AP gains of 1.1% to 1.7% with only a minimal increase in inference latency. Extensive visualization, ablation, and comparative studies validate the effectiveness of our approach, demonstrating its superior capability in discriminating heterogeneous objects with high efficiency.
A Comprehensive Evaluation of LLM Reasoning: From Single-Model to Multi-Agent Paradigms
Jan 19, 2026Large Language Models (LLMs) are increasingly deployed as reasoning systems, where reasoning paradigms - such as Chain-of-Thought (CoT) and multi-agent systems (MAS) - play a critical role, yet their relative effectiveness and cost-accuracy trade-offs remain poorly understood. In this work, we conduct a comprehensive and unified evaluation of reasoning paradigms, spanning direct single-model generation, CoT-augmented single-model reasoning, and representative MAS workflows, characterizing their reasoning performance across a diverse suite of closed-form benchmarks. Beyond overall performance, we probe role-specific capability demands in MAS using targeted role isolation analyses, and analyze cost-accuracy trade-offs to identify which MAS workflows offer a favorable balance between cost and accuracy, and which incur prohibitive overhead for marginal gains. We further introduce MIMeBench, a new open-ended benchmark that targets two foundational yet underexplored semantic capabilities - semantic abstraction and contrastive discrimination - thereby providing an alternative evaluation axis beyond closed-form accuracy and enabling fine-grained assessment of semantic competence that is difficult to capture with existing benchmarks. Our results show that increased structural complexity does not consistently lead to improved reasoning performance, with its benefits being highly dependent on the properties and suitability of the reasoning paradigm itself. The codes are released at https://gitcode.com/HIT1920/OpenLLMBench.
APEX: Academic Poster Editing Agentic Expert
Jan 08, 2026Designing academic posters is a labor-intensive process requiring the precise balance of high-density content and sophisticated layout. While existing paper-to-poster generation methods automate initial drafting, they are typically single-pass and non-interactive, often fail to align with complex, subjective user intent. To bridge this gap, we propose APEX (Academic Poster Editing agentic eXpert), the first agentic framework for interactive academic poster editing, supporting fine-grained control with robust multi-level API-based editing and a review-and-adjustment Mechanism. In addition, we introduce APEX-Bench, the first systematic benchmark comprising 514 academic poster editing instructions, categorized by a multi-dimensional taxonomy including operation type, difficulty, and abstraction level, constructed via reference-guided and reference-free strategies to ensure realism and diversity. We further establish a multi-dimensional VLM-as-a-judge evaluation protocol to assess instruction fulfillment, modification scope, and visual consistency & harmony. Experimental results demonstrate that APEX significantly outperforms baseline methods. Our implementation is available at https://github.com/Breesiu/APEX.
ClinDEF: A Dynamic Evaluation Framework for Large Language Models in Clinical Reasoning
Dec 29, 2025Clinical diagnosis begins with doctor-patient interaction, during which physicians iteratively gather information, determine examination and refine differential diagnosis through patients' response. This dynamic clinical-reasoning process is poorly represented by existing LLM benchmarks that focus on static question-answering. To mitigate these gaps, recent methods explore dynamic medical frameworks involving interactive clinical dialogues. Although effective, they often rely on limited, contamination-prone datasets and lack granular, multi-level evaluation. In this work, we propose ClinDEF, a dynamic framework for assessing clinical reasoning in LLMs through simulated diagnostic dialogues. Grounded in a disease knowledge graph, our method dynamically generates patient cases and facilitates multi-turn interactions between an LLM-based doctor and an automated patient agent. Our evaluation protocol goes beyond diagnostic accuracy by incorporating fine-grained efficiency analysis and rubric-based assessment of diagnostic quality. Experiments show that ClinDEF effectively exposes critical clinical reasoning gaps in state-of-the-art LLMs, offering a more nuanced and clinically meaningful evaluation paradigm.
RecGPT-V2 Technical Report
Dec 16, 2025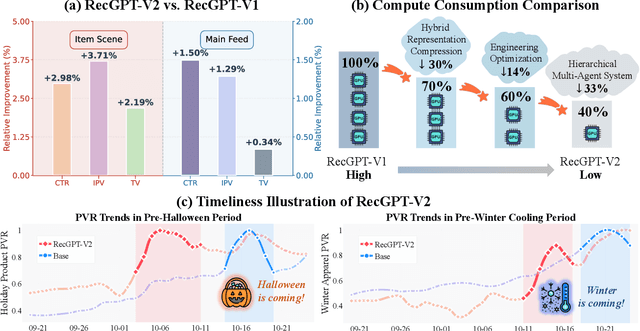
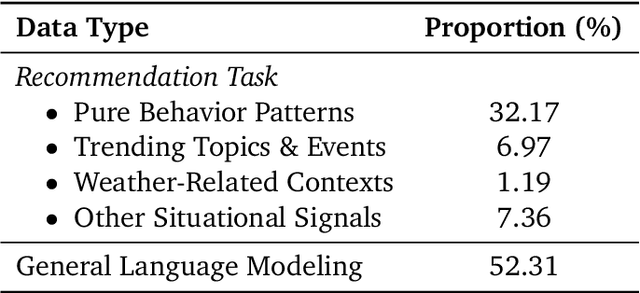
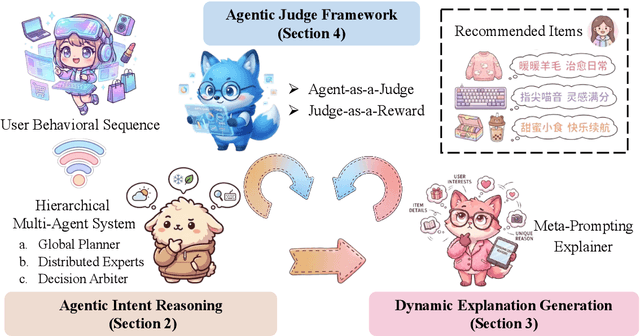

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.