 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePandora: Leveraging Code-driven Knowledge Transfer for Unified Structured Knowledge Reasoning
Aug 25, 2025Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods rely on task-specific strategies or bespoke representations, which hinder their ability to dismantle barriers between different SKR tasks, thereby constraining their overall performance in cross-task scenarios. In this paper, we introduce \textsc{Pandora}, a novel USKR framework that addresses the limitations of existing methods by leveraging two key innovations. First, we propose a code-based unified knowledge representation using \textsc{Python}'s \textsc{Pandas} API, which aligns seamlessly with the pre-training of LLMs. This representation facilitates a cohesive approach to handling different structured knowledge sources. Building on this foundation, we employ knowledge transfer to bolster the unified reasoning process of LLMs by automatically building cross-task memory. By adaptively correcting reasoning using feedback from code execution, \textsc{Pandora} showcases impressive unified reasoning capabilities. Extensive experiments on six widely used benchmarks across three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified reasoning frameworks and competes effectively with task-specific methods.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
After Retrieval, Before Generation: Enhancing the Trustworthiness of Large Language Models in RAG
May 21, 2025



Retrieval-augmented generation (RAG) systems face critical challenges in balancing internal (parametric) and external (retrieved) knowledge, especially when these sources conflict or are unreliable. To analyze these scenarios comprehensively, we construct the Trustworthiness Response Dataset (TRD) with 36,266 questions spanning four RAG settings. We reveal that existing approaches address isolated scenarios-prioritizing one knowledge source, naively merging both, or refusing answers-but lack a unified framework to handle different real-world conditions simultaneously. Therefore, we propose the BRIDGE framework, which dynamically determines a comprehensive response strategy of large language models (LLMs). BRIDGE leverages an adaptive weighting mechanism named soft bias to guide knowledge collection, followed by a Maximum Soft-bias Decision Tree to evaluate knowledge and select optimal response strategies (trust internal/external knowledge, or refuse). Experiments show BRIDGE outperforms baselines by 5-15% in accuracy while maintaining balanced performance across all scenarios. Our work provides an effective solution for LLMs' trustworthy responses in real-world RAG applications.
Rethinking Stateful Tool Use in Multi-Turn Dialogues: Benchmarks and Challenges
May 19, 2025Existing benchmarks that assess Language Models (LMs) as Language Agents (LAs) for tool use primarily focus on stateless, single-turn interactions or partial evaluations, such as tool selection in a single turn, overlooking the inherent stateful nature of interactions in multi-turn applications. To fulfill this gap, we propose \texttt{DialogTool}, a multi-turn dialogue dataset with stateful tool interactions considering the whole life cycle of tool use, across six key tasks in three stages: 1) \textit{tool creation}; 2) \textit{tool utilization}: tool awareness, tool selection, tool execution; and 3) \textit{role-consistent response}: response generation and role play. Furthermore, we build \texttt{VirtualMobile} -- an embodied virtual mobile evaluation environment to simulate API calls and assess the robustness of the created APIs\footnote{We will use tools and APIs alternatively, there are no significant differences between them in this paper.}. Taking advantage of these artifacts, we conduct comprehensive evaluation on 13 distinct open- and closed-source LLMs and provide detailed analysis at each stage, revealing that the existing state-of-the-art LLMs still cannot perform well to use tools over long horizons.
Pandora: A Code-Driven Large Language Model Agent for Unified Reasoning Across Diverse Structured Knowledge
Apr 17, 2025



Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions (NLQs) by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods either rely on employing task-specific strategies or custom-defined representations, which struggle to leverage the knowledge transfer between different SKR tasks or align with the prior of LLMs, thereby limiting their performance. This paper proposes a novel USKR framework named \textsc{Pandora}, which takes advantage of \textsc{Python}'s \textsc{Pandas} API to construct a unified knowledge representation for alignment with LLM pre-training. It employs an LLM to generate textual reasoning steps and executable Python code for each question. Demonstrations are drawn from a memory of training examples that cover various SKR tasks, facilitating knowledge transfer. Extensive experiments on four benchmarks involving three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified frameworks and competes effectively with task-specific methods.
KnowLogic: A Benchmark for Commonsense Reasoning via Knowledge-Driven Data Synthesis
Mar 08, 2025Current evaluations of commonsense reasoning in LLMs are hindered by the scarcity of natural language corpora with structured annotations for reasoning tasks. To address this, we introduce KnowLogic, a benchmark generated through a knowledge-driven synthetic data strategy. KnowLogic integrates diverse commonsense knowledge, plausible scenarios, and various types of logical reasoning. One of the key advantages of KnowLogic is its adjustable difficulty levels, allowing for flexible control over question complexity. It also includes fine-grained labels for in-depth evaluation of LLMs' reasoning abilities across multiple dimensions. Our benchmark consists of 3,000 bilingual (Chinese and English) questions across various domains, and presents significant challenges for current LLMs, with the highest-performing model achieving only 69.57\%. Our analysis highlights common errors, such as misunderstandings of low-frequency commonsense, logical inconsistencies, and overthinking. This approach, along with our benchmark, provides a valuable tool for assessing and enhancing LLMs' commonsense reasoning capabilities and can be applied to a wide range of knowledge domains.
Harnessing Diverse Perspectives: A Multi-Agent Framework for Enhanced Error Detection in Knowledge Graphs
Jan 27, 2025



Knowledge graphs are widely used in industrial applications, making error detection crucial for ensuring the reliability of downstream applications. Existing error detection methods often fail to effectively leverage fine-grained subgraph information and rely solely on fixed graph structures, while also lacking transparency in their decision-making processes, which results in suboptimal detection performance. In this paper, we propose a novel Multi-Agent framework for Knowledge Graph Error Detection (MAKGED) that utilizes multiple large language models (LLMs) in a collaborative setting. By concatenating fine-grained, bidirectional subgraph embeddings with LLM-based query embeddings during training, our framework integrates these representations to produce four specialized agents. These agents utilize subgraph information from different dimensions to engage in multi-round discussions, thereby improving error detection accuracy and ensuring a transparent decision-making process. Extensive experiments on FB15K and WN18RR demonstrate that MAKGED outperforms state-of-the-art methods, enhancing the accuracy and robustness of KG evaluation. For specific industrial scenarios, our framework can facilitate the training of specialized agents using domain-specific knowledge graphs for error detection, which highlights the potential industrial application value of our framework. Our code and datasets are available at https://github.com/kse-ElEvEn/MAKGED.
MINTQA: A Multi-Hop Question Answering Benchmark for Evaluating LLMs on New and Tail Knowledge
Dec 22, 2024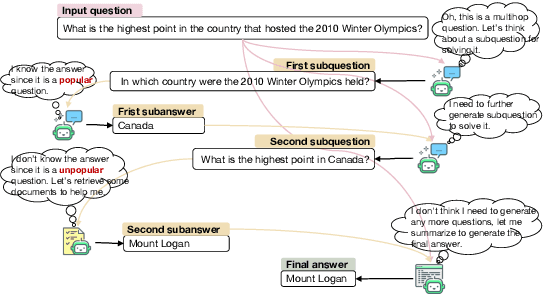
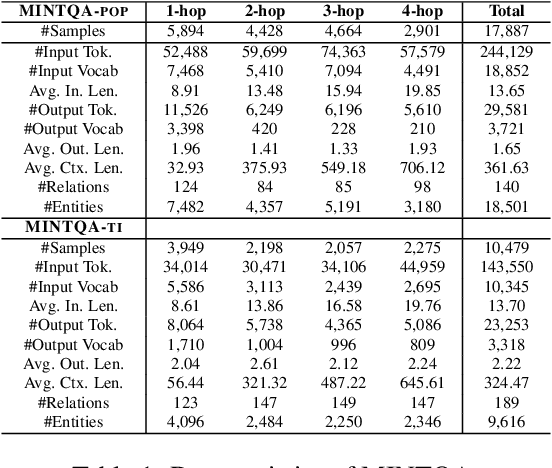
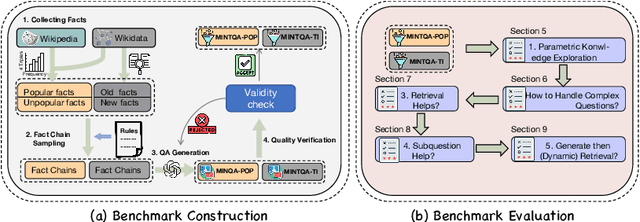
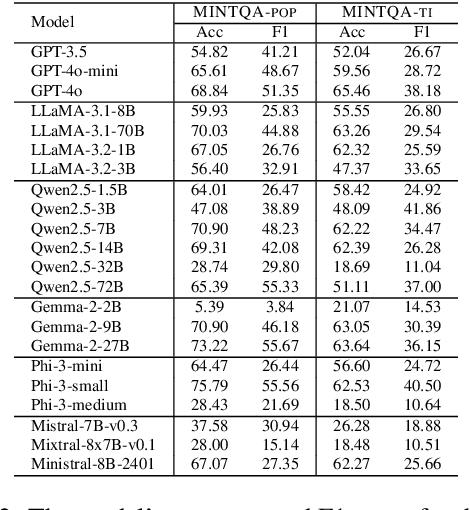
Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks but face significant challenges with complex, knowledge-intensive multi-hop queries, particularly those involving new or long-tail knowledge. Existing benchmarks often fail to fully address these challenges. To bridge this gap, we introduce MINTQA (Multi-hop Question Answering on New and Tail Knowledge), a comprehensive benchmark to evaluate LLMs' capabilities in multi-hop reasoning across four critical dimensions: question handling strategy, sub-question generation, retrieval-augmented generation, and iterative or dynamic decomposition and retrieval. MINTQA comprises 10,479 question-answer pairs for evaluating new knowledge and 17,887 pairs for assessing long-tail knowledge, with each question equipped with corresponding sub-questions and answers. Our systematic evaluation of 22 state-of-the-art LLMs on MINTQA reveals significant limitations in their ability to handle complex knowledge base queries, particularly in handling new or unpopular knowledge. Our findings highlight critical challenges and offer insights for advancing multi-hop reasoning capabilities. The MINTQA benchmark is available at https://github.com/probe2/multi-hop/.
CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
Sep 29, 2024



Recent studies have explored the use of Large Language Models (LLMs) with Retrieval Augmented Generation (RAG) for Knowledge Graph Question Answering (KGQA). They typically require rewriting retrieved subgraphs into natural language formats comprehensible to LLMs. However, when tackling complex questions, the knowledge rewritten by existing methods may include irrelevant information, omit crucial details, or fail to align with the question's semantics. To address them, we propose a novel rewriting method CoTKR, Chain-of-Thought Enhanced Knowledge Rewriting, for generating reasoning traces and corresponding knowledge in an interleaved manner, thereby mitigating the limitations of single-step knowledge rewriting. Additionally, to bridge the preference gap between the knowledge rewriter and the question answering (QA) model, we propose a training strategy PAQAF, Preference Alignment from Question Answering Feedback, for leveraging feedback from the QA model to further optimize the knowledge rewriter. We conduct experiments using various LLMs across several KGQA benchmarks. Experimental results demonstrate that, compared with previous knowledge rewriting methods, CoTKR generates the most beneficial knowledge representation for QA models, which significantly improves the performance of LLMs in KGQA.