 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINTQA: A Multi-Hop Question Answering Benchmark for Evaluating LLMs on New and Tail Knowledge
Paper and Code
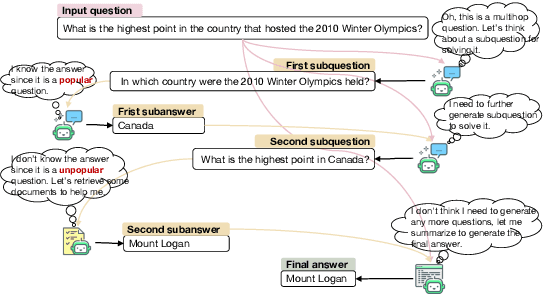
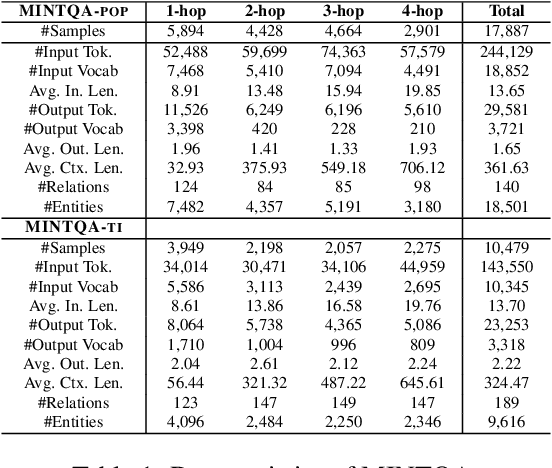
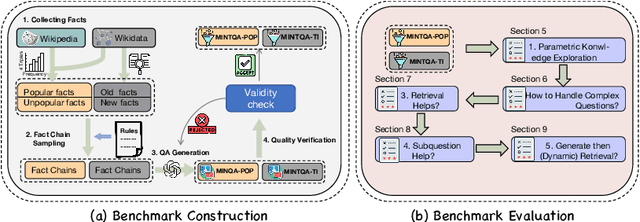
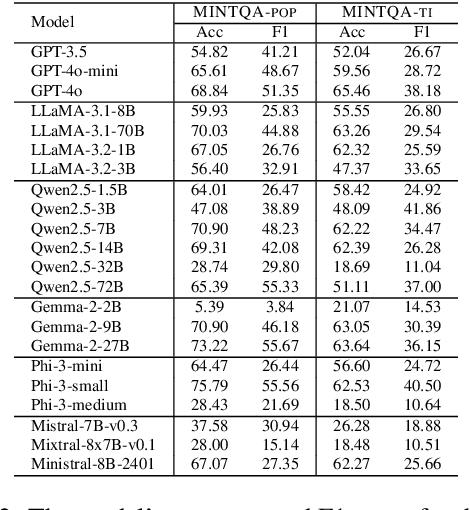
Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks but face significant challenges with complex, knowledge-intensive multi-hop queries, particularly those involving new or long-tail knowledge. Existing benchmarks often fail to fully address these challenges. To bridge this gap, we introduce MINTQA (Multi-hop Question Answering on New and Tail Knowledge), a comprehensive benchmark to evaluate LLMs' capabilities in multi-hop reasoning across four critical dimensions: question handling strategy, sub-question generation, retrieval-augmented generation, and iterative or dynamic decomposition and retrieval. MINTQA comprises 10,479 question-answer pairs for evaluating new knowledge and 17,887 pairs for assessing long-tail knowledge, with each question equipped with corresponding sub-questions and answers. Our systematic evaluation of 22 state-of-the-art LLMs on MINTQA reveals significant limitations in their ability to handle complex knowledge base queries, particularly in handling new or unpopular knowledge. Our findings highlight critical challenges and offer insights for advancing multi-hop reasoning capabilities. The MINTQA benchmark is available at https://github.com/probe2/multi-hop/.