 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain Of Thought Compression: A Theoritical Analysis
Jan 29, 2026Chain-of-Thought (CoT) has unlocked advanced reasoning abilities of Large Language Models (LLMs) with intermediate steps, yet incurs prohibitive computational costs due to generation of extra tokens. Recent studies empirically show that compressing reasoning steps into latent states, or implicit CoT compression, offers a token-efficient alternative. However, the mechanism behind CoT compression remains unclear. In this paper, we provide the first theoretical analysis of the difficulty of learning to internalize intermediate reasoning steps. By introducing Order-r Interaction, we prove that the learning signal for high-order logical dependencies exponentially decays to solve irreducible problem, where skipping intermediate steps inevitably leads to high-order interaction barriers. To empirically validate this, we introduce NatBool-DAG, a challenging benchmark designed to enforce irreducible logical reasoning and eliminate semantic shortcuts. Guided by our theoretical findings, we propose ALiCoT (Aligned Implicit CoT), a novel framework that overcomes the signal decay by aligning latent token distributions with intermediate reasoning states. Experimental results demonstrate that ALiCoT successfully unlocks efficient reasoning: it achieves a 54.4x speedup while maintaining performance comparable to explicit CoT.
LogicScore: Fine-grained Logic Evaluation of Conciseness, Completeness, and Determinateness in Attributed Question Answering
Jan 22, 2026Current evaluation methods for Attributed Question Answering (AQA) suffer from \textit{attribution myopia}: they emphasize verification of isolated statements and their attributions but overlook the global logical integrity of long-form answers. Consequently, Large Language Models (LLMs) often produce factually grounded yet logically incoherent responses with elusive deductive gaps. To mitigate this limitation, we present \textsc{LogicScore}, a unified evaluation framework that shifts the paradigm from local assessment to global reasoning scrutiny. Grounded in Horn Rules, our approach integrates a backward verification mechanism to systematically evaluate three key reasoning dimensions: \textit{Completeness} (logically sound deduction), \textit{Conciseness} (non-redundancy), and \textit{Determinateness} (consistent answer entailment). Extensive experiments across three multi-hop QA datasets (HotpotQA, MusiQue, and 2WikiMultiHopQA) and over 20 LLMs (including GPT-5, Gemini-3-Pro, LLaMA3, and task-specific tuned models) reveal a critical capability gap: leading models often achieve high attribution scores (e.g., 92.85\% precision for Gemini-3 Pro) but struggle with global reasoning quality (e.g., 35.11\% Conciseness for Gemini-3 Pro). Our work establishes a robust standard for logical evaluation, highlighting the need to prioritize reasoning coherence alongside factual grounding in LLM development. Codes are available at: https://github.com/zhichaoyan11/LogicScore.
\textsc{LogicScore}: Fine-grained Logic Evaluation of Conciseness, Completeness, and Determinateness in Attributed Question Answering
Jan 21, 2026Current evaluation methods for Attributed Question Answering (AQA) suffer from \textit{attribution myopia}: they emphasize verification of isolated statements and their attributions but overlook the global logical integrity of long-form answers. Consequently, Large Language Models (LLMs) often produce factually grounded yet logically incoherent responses with elusive deductive gaps. To mitigate this limitation, we present \textsc{LogicScore}, a unified evaluation framework that shifts the paradigm from local assessment to global reasoning scrutiny. Grounded in Horn Rules, our approach integrates a backward verification mechanism to systematically evaluate three key reasoning dimensions: \textit{Completeness} (logically sound deduction), \textit{Conciseness} (non-redundancy), and \textit{Determinateness} (consistent answer entailment). Extensive experiments across three multi-hop QA datasets (HotpotQA, MusiQue, and 2WikiMultiHopQA) and over 20 LLMs (including GPT-5, Gemini-3-Pro, LLaMA3, and task-specific tuned models) reveal a critical capability gap: leading models often achieve high attribution scores (e.g., 92.85\% precision for Gemini-3 Pro) but struggle with global reasoning quality (e.g., 35.11\% Conciseness for Gemini-3 Pro). Our work establishes a robust standard for logical evaluation, highlighting the need to prioritize reasoning coherence alongside factual grounding in LLM development. Codes are available at: https://github.com/zhichaoyan11/LogicScore.
Illusions of Confidence? Diagnosing LLM Truthfulness via Neighborhood Consistency
Jan 09, 2026As Large Language Models (LLMs) are increasingly deployed in real-world settings, correctness alone is insufficient. Reliable deployment requires maintaining truthful beliefs under contextual perturbations. Existing evaluations largely rely on point-wise confidence like Self-Consistency, which can mask brittle belief. We show that even facts answered with perfect self-consistency can rapidly collapse under mild contextual interference. To address this gap, we propose Neighbor-Consistency Belief (NCB), a structural measure of belief robustness that evaluates response coherence across a conceptual neighborhood. To validate the efficiency of NCB, we introduce a new cognitive stress-testing protocol that probes outputs stability under contextual interference. Experiments across multiple LLMs show that the performance of high-NCB data is relatively more resistant to interference. Finally, we present Structure-Aware Training (SAT), which optimizes context-invariant belief structure and reduces long-tail knowledge brittleness by approximately 30%. Code will be available at https://github.com/zjunlp/belief.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
Uncovering and Mitigating Transient Blindness in Multimodal Model Editing
Nov 17, 2025Multimodal Model Editing (MMED) aims to correct erroneous knowledge in multimodal models. Existing evaluation methods, adapted from textual model editing, overstate success by relying on low-similarity or random inputs, obscure overfitting. We propose a comprehensive locality evaluation framework, covering three key dimensions: random-image locality, no-image locality, and consistent-image locality, operationalized through seven distinct data types, enabling a detailed and structured analysis of multimodal edits. We introduce De-VQA, a dynamic evaluation for visual question answering, uncovering a phenomenon we term transient blindness, overfitting to edit-similar text while ignoring visuals. Token analysis shows edits disproportionately affect textual tokens. We propose locality-aware adversarial losses to balance cross-modal representations. Empirical results demonstrate that our approach consistently outperforms existing baselines, reducing transient blindness and improving locality by 17% on average.
Plan Then Retrieve: Reinforcement Learning-Guided Complex Reasoning over Knowledge Graphs
Oct 23, 2025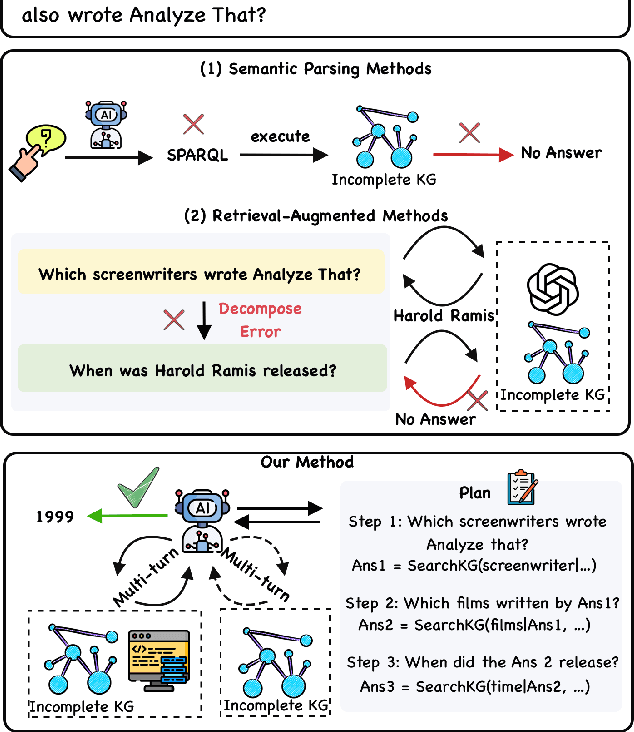

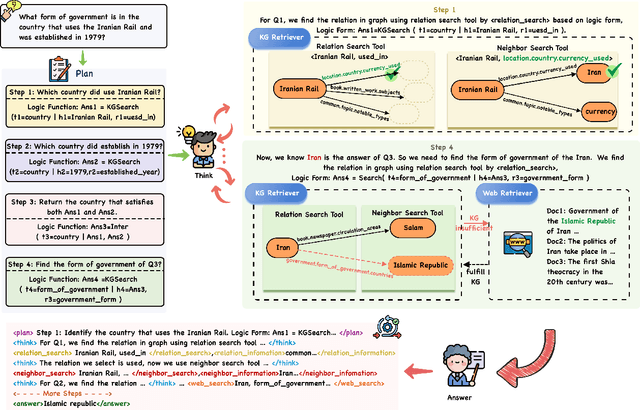
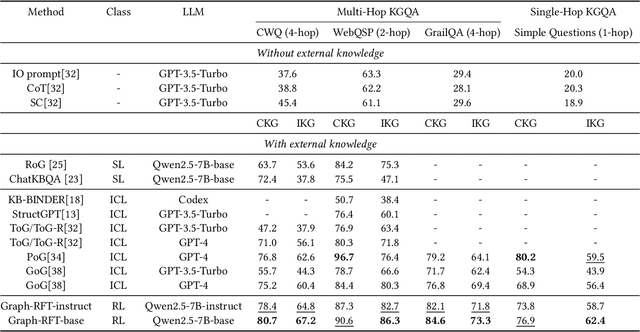
Knowledge Graph Question Answering aims to answer natural language questions by reasoning over structured knowledge graphs. While large language models have advanced KGQA through their strong reasoning capabilities, existing methods continue to struggle to fully exploit both the rich knowledge encoded in KGs and the reasoning capabilities of LLMs, particularly in complex scenarios. They often assume complete KG coverage and lack mechanisms to judge when external information is needed, and their reasoning remains locally myopic, failing to maintain coherent multi-step planning, leading to reasoning failures even when relevant knowledge exists. We propose Graph-RFT, a novel two-stage reinforcement fine-tuning KGQA framework with a 'plan-KGsearch-and-Websearch-during-think' paradigm, that enables LLMs to perform autonomous planning and adaptive retrieval scheduling across KG and web sources under incomplete knowledge conditions. Graph-RFT introduces a chain-of-thought fine-tuning method with a customized plan-retrieval dataset activates structured reasoning and resolves the GRPO cold-start problem. It then introduces a novel plan-retrieval guided reinforcement learning process integrates explicit planning and retrieval actions with a multi-reward design, enabling coverage-aware retrieval scheduling. It employs a Cartesian-inspired planning module to decompose complex questions into ordered subquestions, and logical expression to guide tool invocation for globally consistent multi-step reasoning. This reasoning retrieval process is optimized with a multi-reward combining outcome and retrieval specific signals, enabling the model to learn when and how to combine KG and web retrieval effectively.
From Sufficiency to Reflection: Reinforcement-Guided Thinking Quality in Retrieval-Augmented Reasoning for LLMs
Jul 30, 2025Reinforcement learning-based retrieval-augmented generation (RAG) methods enhance the reasoning abilities of large language models (LLMs). However, most rely only on final-answer rewards, overlooking intermediate reasoning quality. This paper analyzes existing RAG reasoning models and identifies three main failure patterns: (1) information insufficiency, meaning the model fails to retrieve adequate support; (2) faulty reasoning, where logical or content-level flaws appear despite sufficient information; and (3) answer-reasoning inconsistency, where a valid reasoning chain leads to a mismatched final answer. We propose TIRESRAG-R1, a novel framework using a think-retrieve-reflect process and a multi-dimensional reward system to improve reasoning and stability. TIRESRAG-R1 introduces: (1) a sufficiency reward to encourage thorough retrieval; (2) a reasoning quality reward to assess the rationality and accuracy of the reasoning chain; and (3) a reflection reward to detect and revise errors. It also employs a difficulty-aware reweighting strategy and training sample filtering to boost performance on complex tasks. Experiments on four multi-hop QA datasets show that TIRESRAG-R1 outperforms prior RAG methods and generalizes well to single-hop tasks. The code and data are available at: https://github.com/probe2/TIRESRAG-R1.
Millions of $\text{GeAR}$-s: Extending GraphRAG to Millions of Documents
Jul 23, 2025Recent studies have explored graph-based approaches to retrieval-augmented generation, leveraging structured or semi-structured information -- such as entities and their relations extracted from documents -- to enhance retrieval. However, these methods are typically designed to address specific tasks, such as multi-hop question answering and query-focused summarisation, and therefore, there is limited evidence of their general applicability across broader datasets. In this paper, we aim to adapt a state-of-the-art graph-based RAG solution: $\text{GeAR}$ and explore its performance and limitations on the SIGIR 2025 LiveRAG Challenge.
Bridging the Long-Term Gap: A Memory-Active Policy for Multi-Session Task-Oriented Dialogue
May 26, 2025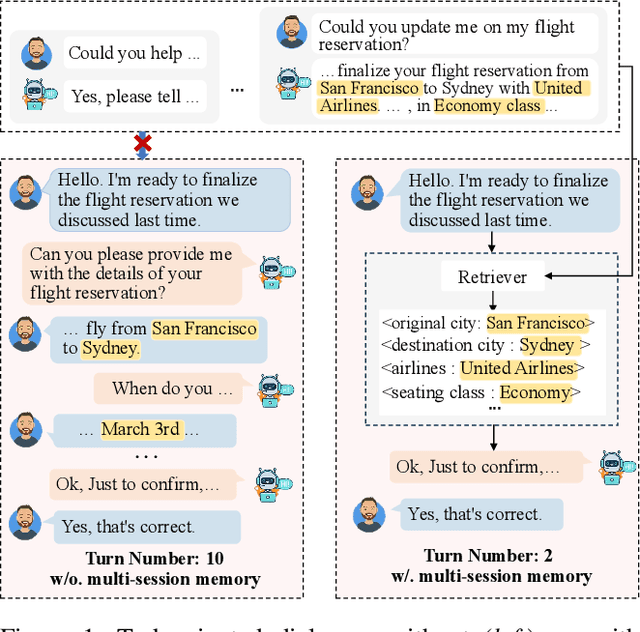
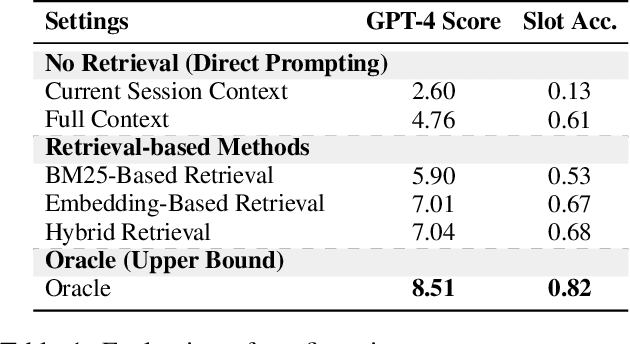
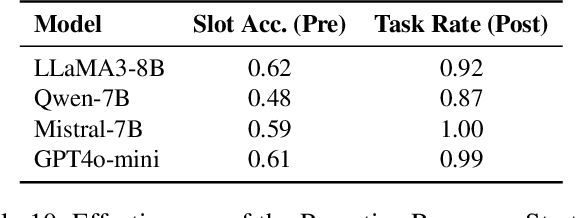
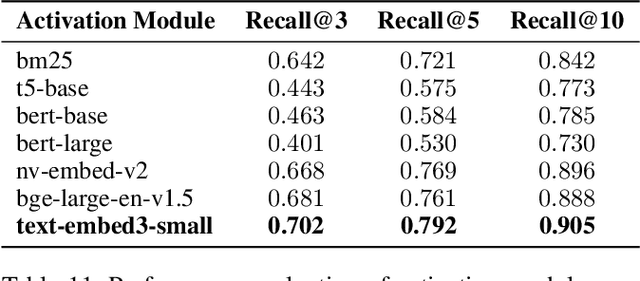
Existing Task-Oriented Dialogue (TOD) systems primarily focus on single-session dialogues, limiting their effectiveness in long-term memory augmentation. To address this challenge, we introduce a MS-TOD dataset, the first multi-session TOD dataset designed to retain long-term memory across sessions, enabling fewer turns and more efficient task completion. This defines a new benchmark task for evaluating long-term memory in multi-session TOD. Based on this new dataset, we propose a Memory-Active Policy (MAP) that improves multi-session dialogue efficiency through a two-stage approach. 1) Memory-Guided Dialogue Planning retrieves intent-aligned history, identifies key QA units via a memory judger, refines them by removing redundant questions, and generates responses based on the reconstructed memory. 2) Proactive Response Strategy detects and correct errors or omissions, ensuring efficient and accurate task completion. We evaluate MAP on MS-TOD dataset, focusing on response quality and effectiveness of the proactive strategy. Experiments on MS-TOD demonstrate that MAP significantly improves task success and turn efficiency in multi-session scenarios, while maintaining competitive performance on conventional single-session tasks.