 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Approach to Improving Fairness in K-means Clustering
May 29, 2025The popular K-means clustering algorithm potentially suffers from a major weakness for further analysis or interpretation. Some cluster may have disproportionately more (or fewer) points from one of the subpopulations in terms of some sensitive variable, e.g., gender or race. Such a fairness issue may cause bias and unexpected social consequences. This work attempts to improve the fairness of K-means clustering with a two-stage optimization formulation--clustering first and then adjust cluster membership of a small subset of selected data points. Two computationally efficient algorithms are proposed in identifying those data points that are expensive for fairness, with one focusing on nearest data points outside of a cluster and the other on highly 'mixed' data points. Experiments on benchmark datasets show substantial improvement on fairness with a minimal impact to clustering quality. The proposed algorithms can be easily extended to a broad class of clustering algorithms or fairness metrics.
Less is More: Making Smaller Language Models Competent Subgraph Retrievers for Multi-hop KGQA
Oct 08, 2024Retrieval-Augmented Generation (RAG) is widely used to inject external non-parametric knowledge into large language models (LLMs). Recent works suggest that Knowledge Graphs (KGs) contain valuable external knowledge for LLMs. Retrieving information from KGs differs from extracting it from document sets. Most existing approaches seek to directly retrieve relevant subgraphs, thereby eliminating the need for extensive SPARQL annotations, traditionally required by semantic parsing methods. In this paper, we model the subgraph retrieval task as a conditional generation task handled by small language models. Specifically, we define a subgraph identifier as a sequence of relations, each represented as a special token stored in the language models. Our base generative subgraph retrieval model, consisting of only 220M parameters, achieves competitive retrieval performance compared to state-of-the-art models relying on 7B parameters, demonstrating that small language models are capable of performing the subgraph retrieval task. Furthermore, our largest 3B model, when plugged with an LLM reader, sets new SOTA end-to-end performance on both the WebQSP and CWQ benchmarks. Our model and data will be made available online: https://github.com/hwy9855/GSR.
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
May 10, 2024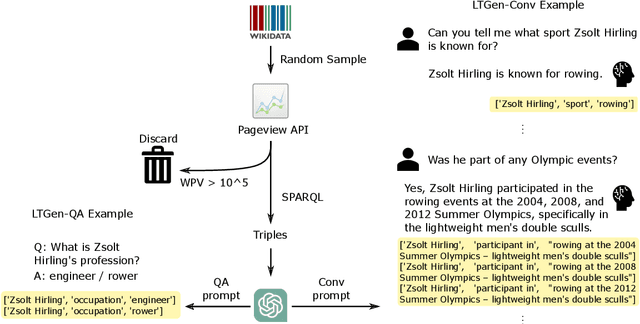
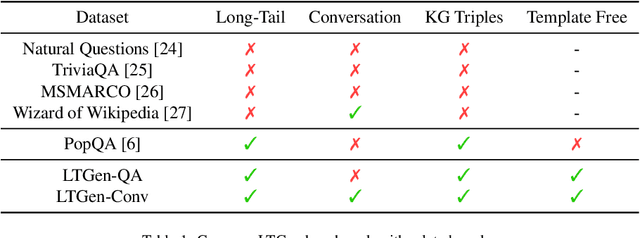
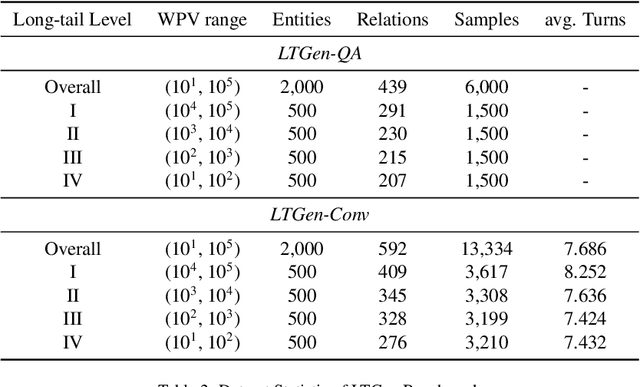
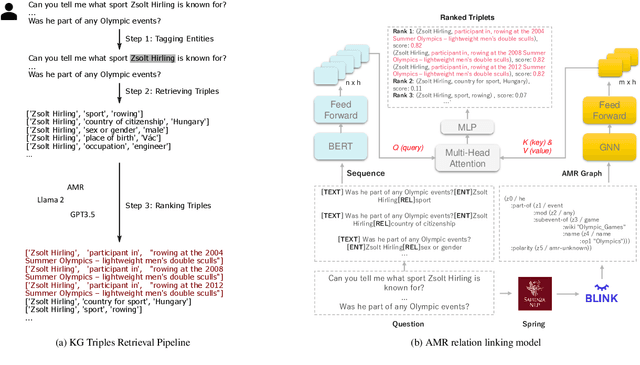
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.