 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Approach to Improving Fairness in K-means Clustering
May 29, 2025The popular K-means clustering algorithm potentially suffers from a major weakness for further analysis or interpretation. Some cluster may have disproportionately more (or fewer) points from one of the subpopulations in terms of some sensitive variable, e.g., gender or race. Such a fairness issue may cause bias and unexpected social consequences. This work attempts to improve the fairness of K-means clustering with a two-stage optimization formulation--clustering first and then adjust cluster membership of a small subset of selected data points. Two computationally efficient algorithms are proposed in identifying those data points that are expensive for fairness, with one focusing on nearest data points outside of a cluster and the other on highly 'mixed' data points. Experiments on benchmark datasets show substantial improvement on fairness with a minimal impact to clustering quality. The proposed algorithms can be easily extended to a broad class of clustering algorithms or fairness metrics.
A Deep Neural Network Based Approach to Building Budget-Constrained Models for Big Data Analysis
Feb 23, 2023



Deep learning approaches require collection of data on many different input features or variables for accurate model training and prediction. Since data collection on input features could be costly, it is crucial to reduce the cost by selecting a subset of features and developing a budget-constrained model (BCM). In this paper, we introduce an approach to eliminating less important features for big data analysis using Deep Neural Networks (DNNs). Once a DNN model has been developed, we identify the weak links and weak neurons, and remove some input features to bring the model cost within a given budget. The experimental results show our approach is feasible and supports user selection of a suitable BCM within a given budget.
Cost-sensitive Selection of Variables by Ensemble of Model Sequences
Jan 02, 2019
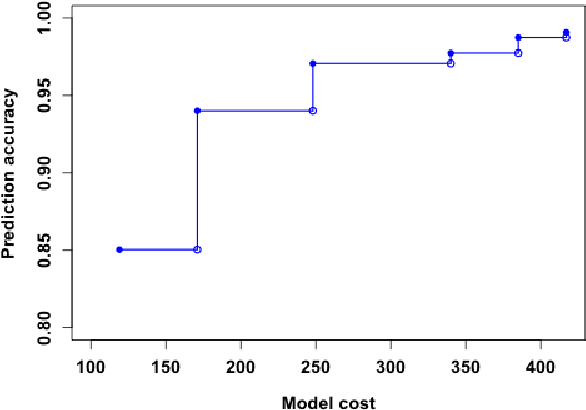
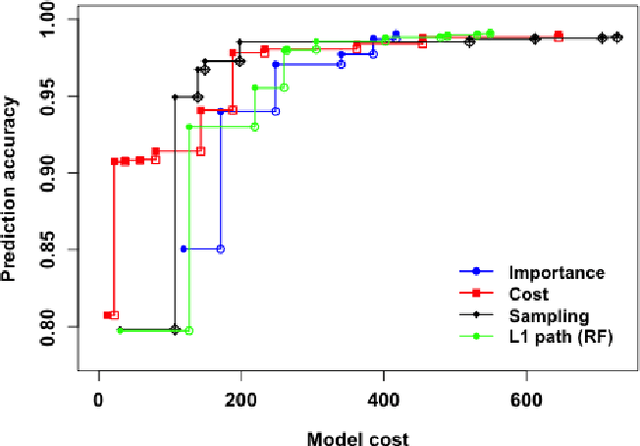
Many applications require the collection of data on different variables or measurements over many system performance metrics. We term those broadly as measures or variables. Often data collection along each measure incurs a cost, thus it is desirable to consider the cost of measures in modeling. This is a fairly new class of problems in the area of cost-sensitive learning. A few attempts have been made to incorporate costs in combining and selecting measures. However, existing studies either do not strictly enforce a budget constraint, or are not the `most' cost effective. With a focus on classification problem, we propose a computationally efficient approach that could find a near optimal model under a given budget by exploring the most `promising' part of the solution space. Instead of outputting a single model, we produce a model schedule---a list of models, sorted by model costs and expected predictive accuracy. This could be used to choose the model with the best predictive accuracy under a given budget, or to trade off between the budget and the predictive accuracy. Experiments on some benchmark datasets show that our approach compares favorably to competing methods.