 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Defense Strategies for Multimodal Contrastive Learning: Efficient Fine-tuning Against Backdoor Attacks
Nov 17, 2025The advent of multimodal deep learning models, such as CLIP, has unlocked new frontiers in a wide range of applications, from image-text understanding to classification tasks. However, these models are not safe for adversarial attacks, particularly backdoor attacks, which can subtly manipulate model behavior. Moreover, existing defense methods typically involve training from scratch or fine-tuning using a large dataset without pinpointing the specific labels that are affected. In this study, we introduce an innovative strategy to enhance the robustness of multimodal contrastive learning models against such attacks. In particular, given a poisoned CLIP model, our approach can identify the backdoor trigger and pinpoint the victim samples and labels in an efficient manner. To that end, an image segmentation ``oracle'' is introduced as the supervisor for the output of the poisoned CLIP. We develop two algorithms to rectify the poisoned model: (1) differentiating between CLIP and Oracle's knowledge to identify potential triggers; (2) pinpointing affected labels and victim samples, and curating a compact fine-tuning dataset. With this knowledge, we are allowed to rectify the poisoned CLIP model to negate backdoor effects. Extensive experiments on visual recognition benchmarks demonstrate our strategy is effective in CLIP-based backdoor defense.
Toward Improving fNIRS Classification: A Study on Activation Functions in Deep Neural Architectures
Jul 15, 2025Activation functions are critical to the performance of deep neural networks, particularly in domains such as functional near-infrared spectroscopy (fNIRS), where nonlinearity, low signal-to-noise ratio (SNR), and signal variability poses significant challenges to model accuracy. However, the impact of activation functions on deep learning (DL) performance in the fNIRS domain remains underexplored and lacks systematic investigation in the current literature. This study evaluates a range of conventional and field-specific activation functions for fNIRS classification tasks using multiple deep learning architectures, including the domain-specific fNIRSNet, AbsoluteNet, MDNN, and shallowConvNet (as the baseline), all tested on a single dataset recorded during an auditory task. To ensure fair a comparison, all networks were trained and tested using standardized preprocessing and consistent training parameters. The results show that symmetrical activation functions such as Tanh and the Absolute value function Abs(x) can outperform commonly used functions like the Rectified Linear Unit (ReLU), depending on the architecture. Additionally, a focused analysis of the role of symmetry was conducted using a Modified Absolute Function (MAF), with results further supporting the effectiveness of symmetrical activation functions on performance gains. These findings underscore the importance of selecting proper activation functions that align with the signal characteristics of fNIRS data.
Cross-Block Fine-Grained Semantic Cascade for Skeleton-Based Sports Action Recognition
Apr 30, 2024Human action video recognition has recently attracted more attention in applications such as video security and sports posture correction. Popular solutions, including graph convolutional networks (GCNs) that model the human skeleton as a spatiotemporal graph, have proven very effective. GCNs-based methods with stacked blocks usually utilize top-layer semantics for classification/annotation purposes. Although the global features learned through the procedure are suitable for the general classification, they have difficulty capturing fine-grained action change across adjacent frames -- decisive factors in sports actions. In this paper, we propose a novel ``Cross-block Fine-grained Semantic Cascade (CFSC)'' module to overcome this challenge. In summary, the proposed CFSC progressively integrates shallow visual knowledge into high-level blocks to allow networks to focus on action details. In particular, the CFSC module utilizes the GCN feature maps produced at different levels, as well as aggregated features from proceeding levels to consolidate fine-grained features. In addition, a dedicated temporal convolution is applied at each level to learn short-term temporal features, which will be carried over from shallow to deep layers to maximize the leverage of low-level details. This cross-block feature aggregation methodology, capable of mitigating the loss of fine-grained information, has resulted in improved performance. Last, FD-7, a new action recognition dataset for fencing sports, was collected and will be made publicly available. Experimental results and empirical analysis on public benchmarks (FSD-10) and self-collected (FD-7) demonstrate the advantage of our CFSC module on learning discriminative patterns for action classification over others.
Sketch3D: Style-Consistent Guidance for Sketch-to-3D Generation
Apr 07, 2024Recently, image-to-3D approaches have achieved significant results with a natural image as input. However, it is not always possible to access these enriched color input samples in practical applications, where only sketches are available. Existing sketch-to-3D researches suffer from limitations in broad applications due to the challenges of lacking color information and multi-view content. To overcome them, this paper proposes a novel generation paradigm Sketch3D to generate realistic 3D assets with shape aligned with the input sketch and color matching the textual description. Concretely, Sketch3D first instantiates the given sketch in the reference image through the shape-preserving generation process. Second, the reference image is leveraged to deduce a coarse 3D Gaussian prior, and multi-view style-consistent guidance images are generated based on the renderings of the 3D Gaussians. Finally, three strategies are designed to optimize 3D Gaussians, i.e., structural optimization via a distribution transfer mechanism, color optimization with a straightforward MSE loss and sketch similarity optimization with a CLIP-based geometric similarity loss. Extensive visual comparisons and quantitative analysis illustrate the advantage of our Sketch3D in generating realistic 3D assets while preserving consistency with the input.
Few-shot Shape Recognition by Learning Deep Shape-aware Features
Dec 03, 2023Traditional shape descriptors have been gradually replaced by convolutional neural networks due to their superior performance in feature extraction and classification. The state-of-the-art methods recognize object shapes via image reconstruction or pixel classification. However , these methods are biased toward texture information and overlook the essential shape descriptions, thus, they fail to generalize to unseen shapes. We are the first to propose a fewshot shape descriptor (FSSD) to recognize object shapes given only one or a few samples. We employ an embedding module for FSSD to extract transformation-invariant shape features. Secondly, we develop a dual attention mechanism to decompose and reconstruct the shape features via learnable shape primitives. In this way, any shape can be formed through a finite set basis, and the learned representation model is highly interpretable and extendable to unseen shapes. Thirdly, we propose a decoding module to include the supervision of shape masks and edges and align the original and reconstructed shape features, enforcing the learned features to be more shape-aware. Lastly, all the proposed modules are assembled into a few-shot shape recognition scheme. Experiments on five datasets show that our FSSD significantly improves the shape classification compared to the state-of-the-art under the few-shot setting.
A Deep Neural Network Based Approach to Building Budget-Constrained Models for Big Data Analysis
Feb 23, 2023



Deep learning approaches require collection of data on many different input features or variables for accurate model training and prediction. Since data collection on input features could be costly, it is crucial to reduce the cost by selecting a subset of features and developing a budget-constrained model (BCM). In this paper, we introduce an approach to eliminating less important features for big data analysis using Deep Neural Networks (DNNs). Once a DNN model has been developed, we identify the weak links and weak neurons, and remove some input features to bring the model cost within a given budget. The experimental results show our approach is feasible and supports user selection of a suitable BCM within a given budget.
Unsupervised Visual Defect Detection with Score-Based Generative Model
Nov 29, 2022Anomaly Detection (AD), as a critical problem, has been widely discussed. In this paper, we specialize in one specific problem, Visual Defect Detection (VDD), in many industrial applications. And in practice, defect image samples are very rare and difficult to collect. Thus, we focus on the unsupervised visual defect detection and localization tasks and propose a novel framework based on the recent score-based generative models, which synthesize the real image by iterative denoising through stochastic differential equations (SDEs). Our work is inspired by the fact that with noise injected into the original image, the defects may be changed into normal cases in the denoising process (i.e., reconstruction). First, based on the assumption that the anomalous data lie in the low probability density region of the normal data distribution, we explain a common phenomenon that occurs when reconstruction-based approaches are applied to VDD: normal pixels also change during the reconstruction process. Second, due to the differences in normal pixels between the reconstructed and original images, a time-dependent gradient value (i.e., score) of normal data distribution is utilized as a metric, rather than reconstruction loss, to gauge the defects. Third, a novel $T$ scales approach is developed to dramatically reduce the required number of iterations, accelerating the inference process. These practices allow our model to generalize VDD in an unsupervised manner while maintaining reasonably good performance. We evaluate our method on several datasets to demonstrate its effectiveness.
The 5th Recognizing Families in the Wild Data Challenge: Predicting Kinship from Faces
Nov 26, 2021

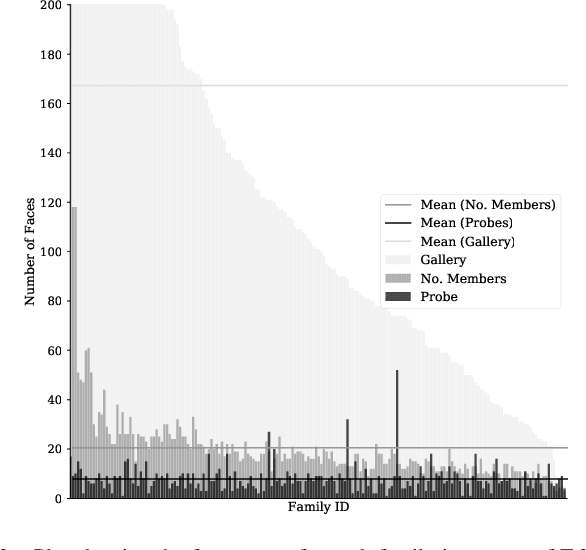

Recognizing Families In the Wild (RFIW), held as a data challenge in conjunction with the 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG), is a large-scale, multi-track visual kinship recognition evaluation. For the fifth edition of RFIW, we continue to attract scholars, bring together professionals, publish new work, and discuss prospects. In this paper, we summarize submissions for the three tasks of this year's RFIW: specifically, we review the results for kinship verification, tri-subject verification, and family member search and retrieval. We look at the RFIW problem, share current efforts, and make recommendations for promising future directions.
Single-shot Compressed 3D Imaging by Exploiting Random Scattering and Astigmatism
May 21, 2021
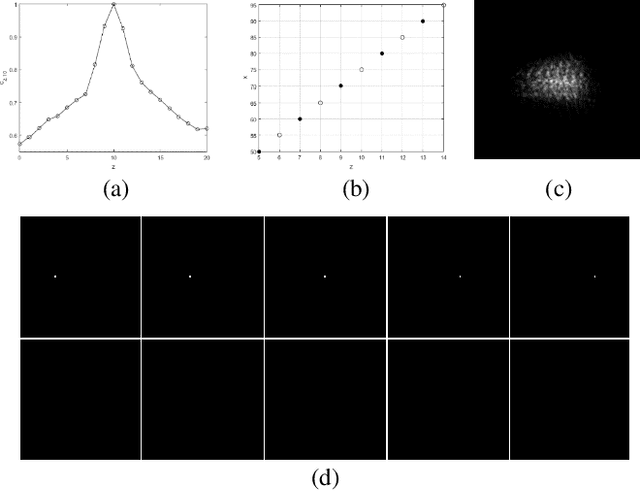


Based on point spread function (PSF) engineering and astigmatism due to a pair of cylindrical lenses, a novel compressed imaging mechanism is proposed to achieve single-shot incoherent 3D imaging. The speckle-like PSF of the imaging system is sensitive to axial shift, which makes it feasible to reconstruct a 3D image by solving an optimization problem with sparsity constraint. With the experimentally calibrated PSFs, the proposed method is demonstrated by a synthetic 3D point object and real 3D object, and the images in different axial slices can be reconstructed faithfully. Moreover, 3D multispectral compressed imaging is explored with the same system, and the result is rather satisfactory with a synthetic point object. Because of the inherent compatibility between the compression in spectral and axial dimensions, the proposed mechanism has the potential to be a unified framework for multi-dimensional compressed imaging.
Discriminative Cross-Domain Feature Learning for Partial Domain Adaptation
Aug 26, 2020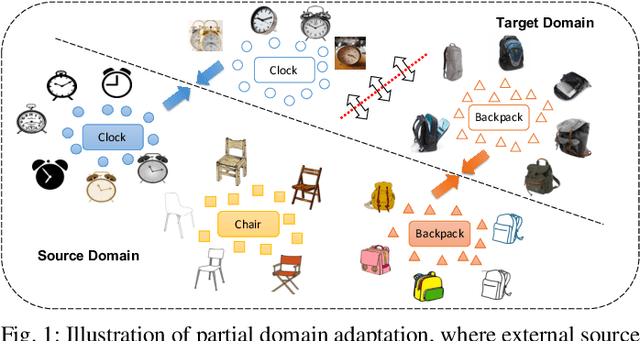

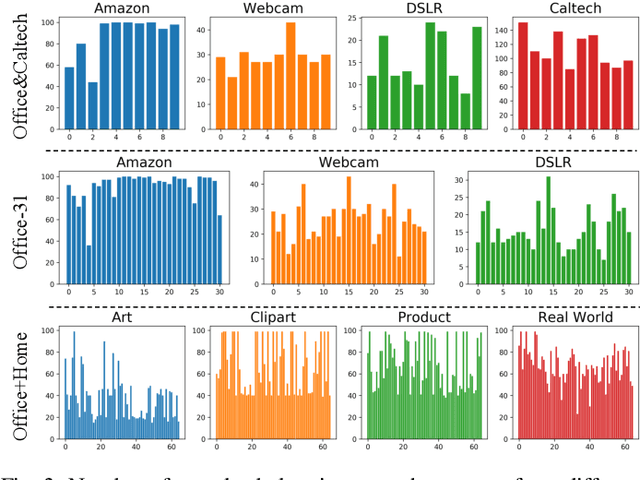
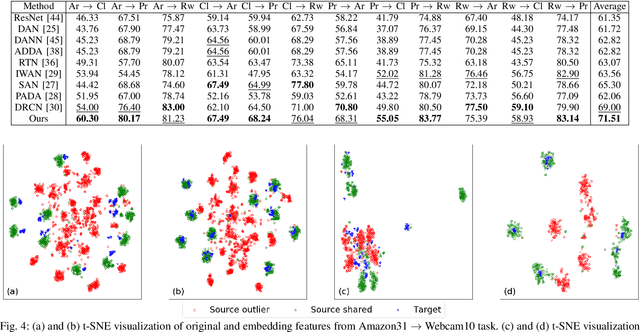
Partial domain adaptation aims to adapt knowledge from a larger and more diverse source domain to a smaller target domain with less number of classes, which has attracted appealing attention. Recent practice on domain adaptation manages to extract effective features by incorporating the pseudo labels for the target domain to better fight off the cross-domain distribution divergences. However, it is essential to align target data with only a small set of source data. In this paper, we develop a novel Discriminative Cross-Domain Feature Learning (DCDF) framework to iteratively optimize target labels with a cross-domain graph in a weighted scheme. Specifically, a weighted cross-domain center loss and weighted cross-domain graph propagation are proposed to couple unlabeled target data to related source samples for discriminative cross-domain feature learning, where irrelevant source centers will be ignored, to alleviate the marginal and conditional disparities simultaneously. Experimental evaluations on several popular benchmarks demonstrate the effectiveness of our proposed approach on facilitating the recognition for the unlabeled target domain, through comparing it to the state-of-the-art partial domain adaptation approaches.