 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Heart's Pathways: ECG Representation Learning from a Cardiac Conduction Perspective
Dec 30, 2025The multi-lead electrocardiogram (ECG) stands as a cornerstone of cardiac diagnosis. Recent strides in electrocardiogram self-supervised learning (eSSL) have brightened prospects for enhancing representation learning without relying on high-quality annotations. Yet earlier eSSL methods suffer a key limitation: they focus on consistent patterns across leads and beats, overlooking the inherent differences in heartbeats rooted in cardiac conduction processes, while subtle but significant variations carry unique physiological signatures. Moreover, representation learning for ECG analysis should align with ECG diagnostic guidelines, which progress from individual heartbeats to single leads and ultimately to lead combinations. This sequential logic, however, is often neglected when applying pre-trained models to downstream tasks. To address these gaps, we propose CLEAR-HUG, a two-stage framework designed to capture subtle variations in cardiac conduction across leads while adhering to ECG diagnostic guidelines. In the first stage, we introduce an eSSL model termed Conduction-LEAd Reconstructor (CLEAR), which captures both specific variations and general commonalities across heartbeats. Treating each heartbeat as a distinct entity, CLEAR employs a simple yet effective sparse attention mechanism to reconstruct signals without interference from other heartbeats. In the second stage, we implement a Hierarchical lead-Unified Group head (HUG) for disease diagnosis, mirroring clinical workflow. Experimental results across six tasks show a 6.84% improvement, validating the effectiveness of CLEAR-HUG. This highlights its ability to enhance representations of cardiac conduction and align patterns with expert diagnostic guidelines.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval
Mar 07, 2022
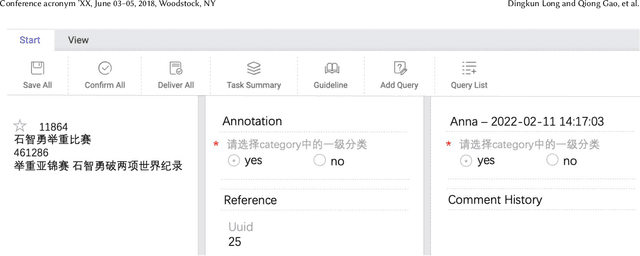
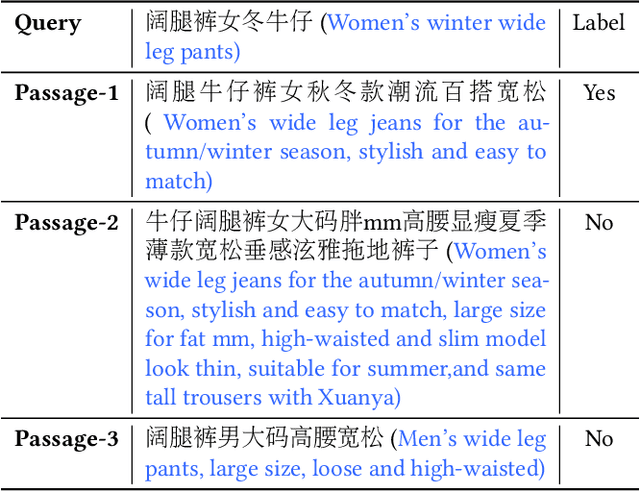
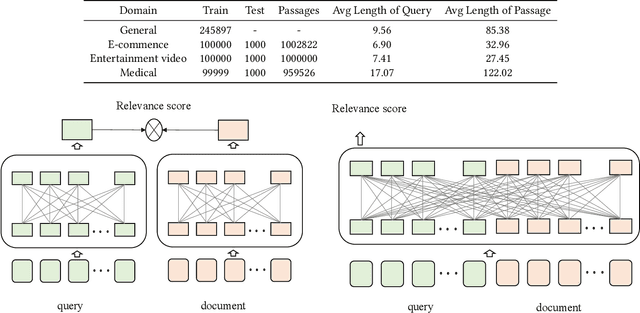
Passage retrieval is a fundamental task in information retrieval (IR) research, which has drawn much attention recently. In English field, the availability of large-scale annotated dataset (e.g, MS MARCO) and the emergence of deep pre-trained language models (e.g, BERT) have resulted in a substantial improvement of existing passage retrieval systems. However, in Chinese field, especially for specific domain, passage retrieval systems are still immature due to quality-annotated dataset being limited by scale. Therefore, in this paper, we present a novel multi-domain Chinese dataset for passage retrieval (Multi-CPR). The dataset is collected from three different domains, including E-commerce, Entertainment video and Medical. Each dataset contains millions of passages and a certain amount of human annotated query-passage related pairs. We implement various representative passage retrieval methods as baselines. We find that the performance of retrieval models trained on dataset from general domain will inevitably decrease on specific domain. Nevertheless, passage retrieval system built on in-domain annotated dataset can achieve significant improvement, which indeed demonstrates the necessity of domain labeled data for further optimization. We hope the release of the Multi-CPR dataset could benchmark Chinese passage retrieval task in specific domain and also make advances for future studies.
Single-shot Compressed 3D Imaging by Exploiting Random Scattering and Astigmatism
May 21, 2021
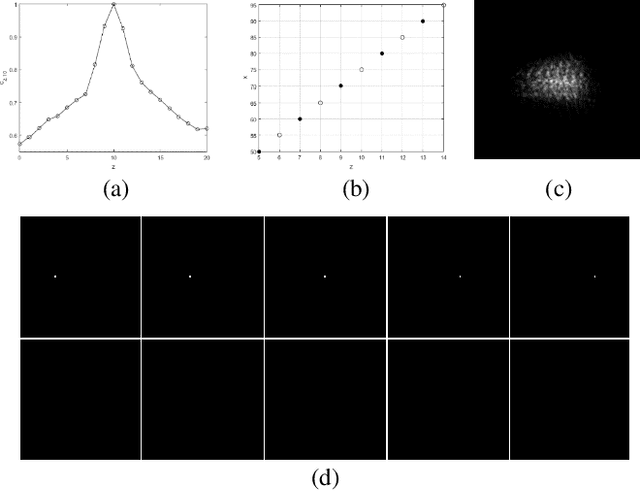


Based on point spread function (PSF) engineering and astigmatism due to a pair of cylindrical lenses, a novel compressed imaging mechanism is proposed to achieve single-shot incoherent 3D imaging. The speckle-like PSF of the imaging system is sensitive to axial shift, which makes it feasible to reconstruct a 3D image by solving an optimization problem with sparsity constraint. With the experimentally calibrated PSFs, the proposed method is demonstrated by a synthetic 3D point object and real 3D object, and the images in different axial slices can be reconstructed faithfully. Moreover, 3D multispectral compressed imaging is explored with the same system, and the result is rather satisfactory with a synthetic point object. Because of the inherent compatibility between the compression in spectral and axial dimensions, the proposed mechanism has the potential to be a unified framework for multi-dimensional compressed imaging.
Applying MDL to Learning Best Model Granularity
May 23, 2000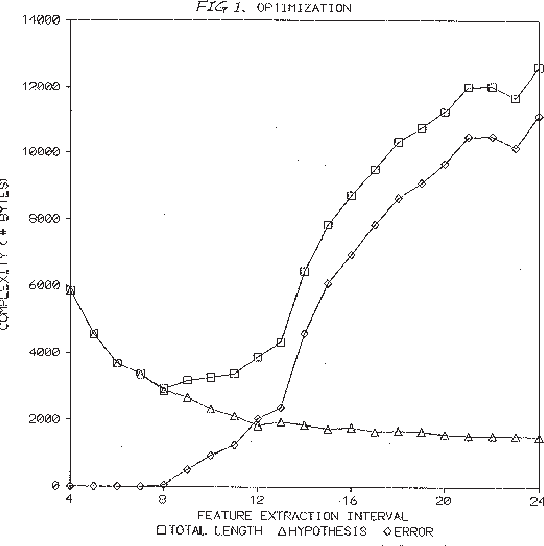
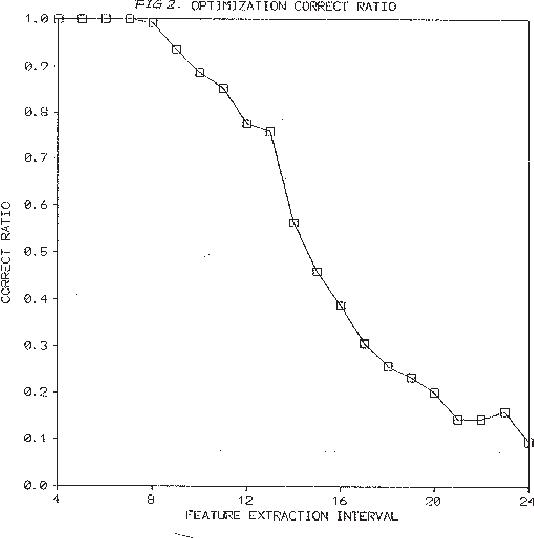
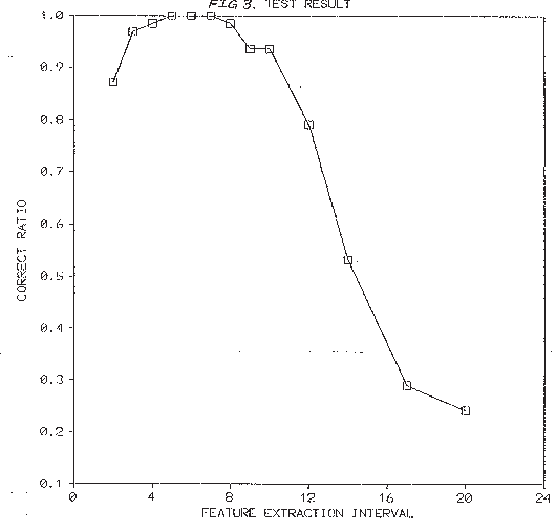
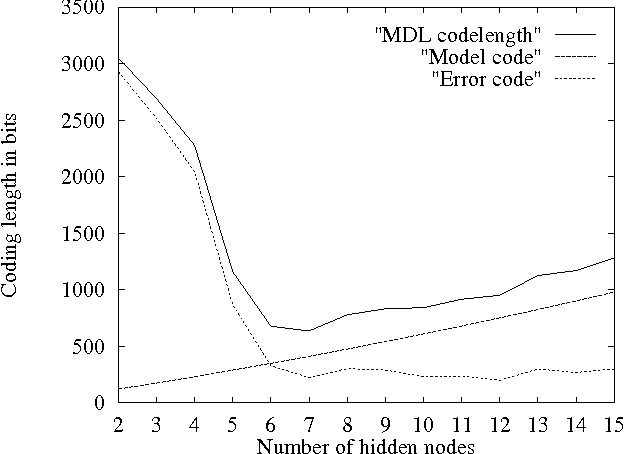
The Minimum Description Length (MDL) principle is solidly based on a provably ideal method of inference using Kolmogorov complexity. We test how the theory behaves in practice on a general problem in model selection: that of learning the best model granularity. The performance of a model depends critically on the granularity, for example the choice of precision of the parameters. Too high precision generally involves modeling of accidental noise and too low precision may lead to confusion of models that should be distinguished. This precision is often determined ad hoc. In MDL the best model is the one that most compresses a two-part code of the data set: this embodies ``Occam's Razor.'' In two quite different experimental settings the theoretical value determined using MDL coincides with the best value found experimentally. In the first experiment the task is to recognize isolated handwritten characters in one subject's handwriting, irrespective of size and orientation. Based on a new modification of elastic matching, using multiple prototypes per character, the optimal prediction rate is predicted for the learned parameter (length of sampling interval) considered most likely by MDL, which is shown to coincide with the best value found experimentally. In the second experiment the task is to model a robot arm with two degrees of freedom using a three layer feed-forward neural network where we need to determine the number of nodes in the hidden layer giving best modeling performance. The optimal model (the one that extrapolizes best on unseen examples) is predicted for the number of nodes in the hidden layer considered most likely by MDL, which again is found to coincide with the best value found experimentally.