 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSearch-SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Alignment
Feb 19, 2025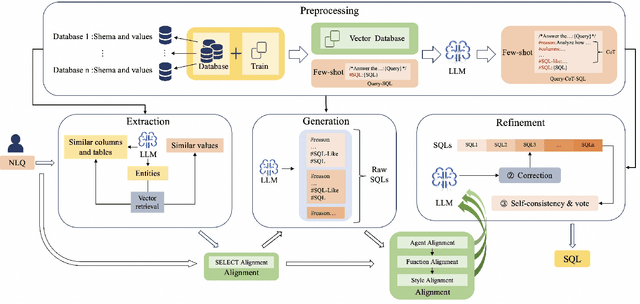
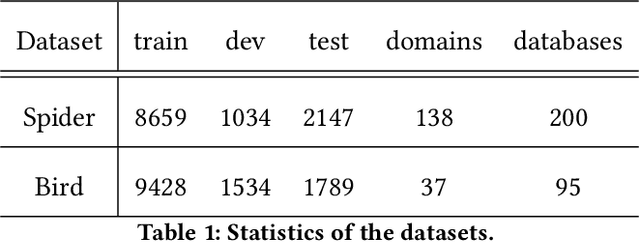
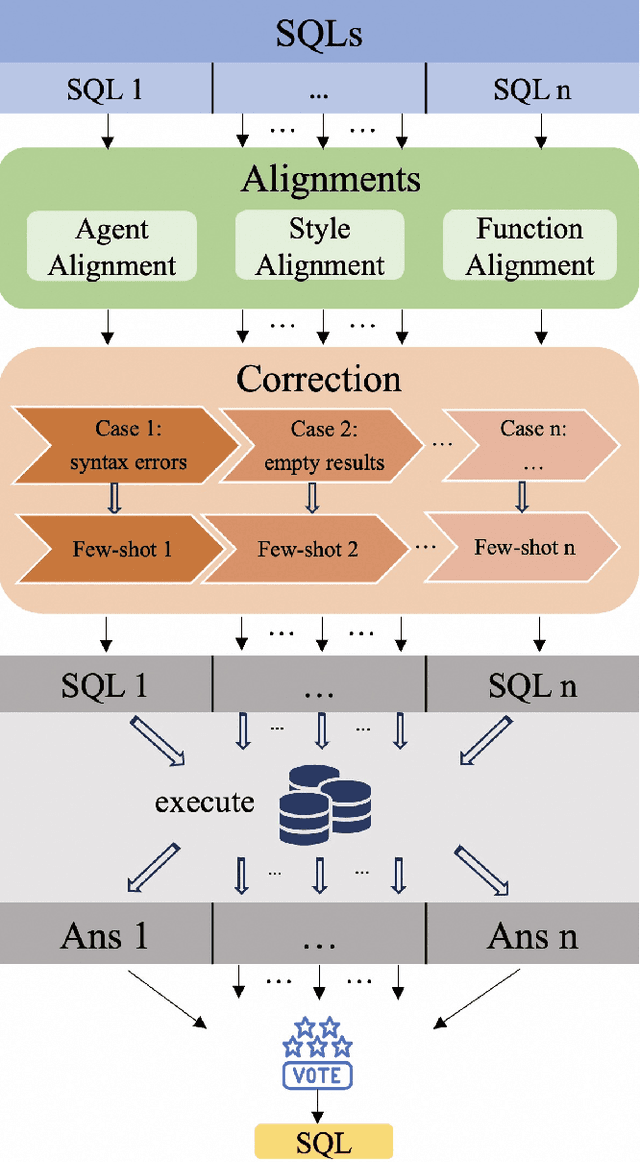
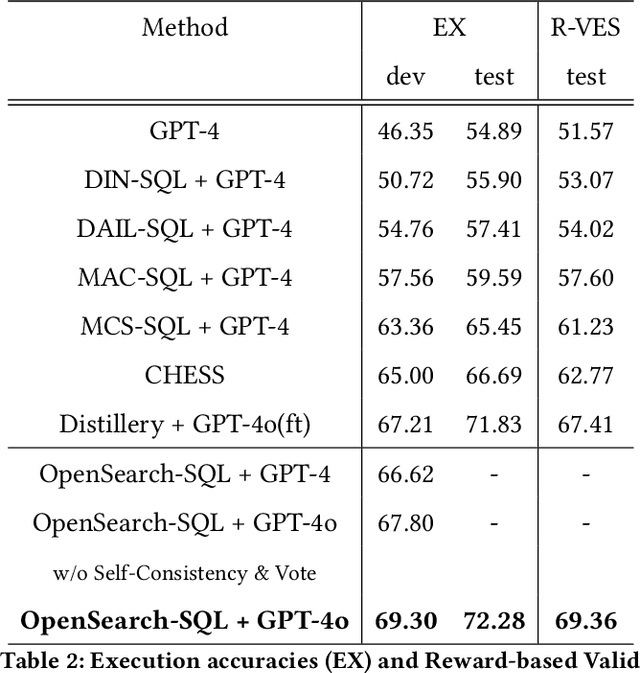
Although multi-agent collaborative Large Language Models (LLMs) have achieved significant breakthroughs in the Text-to-SQL task, their performance is still constrained by various factors. These factors include the incompleteness of the framework, failure to follow instructions, and model hallucination problems. To address these problems, we propose OpenSearch-SQL, which divides the Text-to-SQL task into four main modules: Preprocessing, Extraction, Generation, and Refinement, along with an Alignment module based on a consistency alignment mechanism. This architecture aligns the inputs and outputs of agents through the Alignment module, reducing failures in instruction following and hallucination. Additionally, we designed an intermediate language called SQL-Like and optimized the structured CoT based on SQL-Like. Meanwhile, we developed a dynamic few-shot strategy in the form of self-taught Query-CoT-SQL. These methods have significantly improved the performance of LLMs in the Text-to-SQL task. In terms of model selection, we directly applied the base LLMs without any post-training, thereby simplifying the task chain and enhancing the framework's portability. Experimental results show that OpenSearch-SQL achieves an execution accuracy(EX) of 69.3% on the BIRD development set, 72.28% on the test set, and a reward-based validity efficiency score (R-VES) of 69.36%, with all three metrics ranking first at the time of submission. These results demonstrate the comprehensive advantages of the proposed method in both effectiveness and efficiency.
Unity is Power: Semi-Asynchronous Collaborative Training of Large-Scale Models with Structured Pruning in Resource-Limited Clients
Oct 11, 2024



In this work, we study to release the potential of massive heterogeneous weak computing power to collaboratively train large-scale models on dispersed datasets. In order to improve both efficiency and accuracy in resource-adaptive collaborative learning, we take the first step to consider the \textit{unstructured pruning}, \textit{varying submodel architectures}, \textit{knowledge loss}, and \textit{straggler} challenges simultaneously. We propose a novel semi-asynchronous collaborative training framework, namely ${Co\text{-}S}^2{P}$, with data distribution-aware structured pruning and cross-block knowledge transfer mechanism to address the above concerns. Furthermore, we provide theoretical proof that ${Co\text{-}S}^2{P}$ can achieve asymptotic optimal convergence rate of $O(1/\sqrt{N^*EQ})$. Finally, we conduct extensive experiments on a real-world hardware testbed, in which 16 heterogeneous Jetson devices can be united to train large-scale models with parameters up to 0.11 billion. The experimental results demonstrate that $Co\text{-}S^2P$ improves accuracy by up to 8.8\% and resource utilization by up to 1.2$\times$ compared to state-of-the-art methods, while reducing memory consumption by approximately 22\% and training time by about 24\% on all resource-limited devices.
Hybrid Retrieval and Multi-stage Text Ranking Solution at TREC 2022 Deep Learning Track
Aug 23, 2023



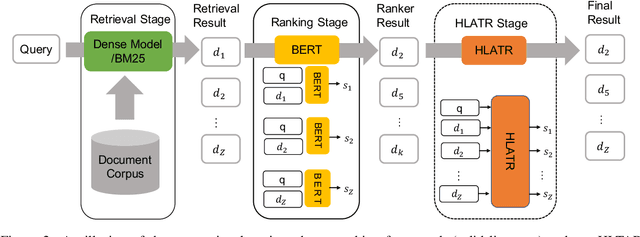
Large-scale text retrieval technology has been widely used in various practical business scenarios. This paper presents our systems for the TREC 2022 Deep Learning Track. We explain the hybrid text retrieval and multi-stage text ranking method adopted in our solution. The retrieval stage combined the two structures of traditional sparse retrieval and neural dense retrieval. In the ranking stage, in addition to the full interaction-based ranking model built on large pre-trained language model, we also proposes a lightweight sub-ranking module to further enhance the final text ranking performance. Evaluation results demonstrate the effectiveness of our proposed approach. Our models achieve the 1st and 4th rank on the test set of passage ranking and document ranking respectively.
Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks
Jun 07, 2023To promote the development of Vision-Language Pre-training (VLP) and multimodal Large Language Model (LLM) in the Chinese community, we firstly release the largest public Chinese high-quality video-language dataset named Youku-mPLUG, which is collected from Youku, a well-known Chinese video-sharing website, with strict criteria of safety, diversity, and quality. Youku-mPLUG contains 10 million Chinese video-text pairs filtered from 400 million raw videos across a wide range of 45 diverse categories for large-scale pre-training. In addition, to facilitate a comprehensive evaluation of video-language models, we carefully build the largest human-annotated Chinese benchmarks covering three popular video-language tasks of cross-modal retrieval, video captioning, and video category classification. Youku-mPLUG can enable researchers to conduct more in-depth multimodal research and develop better applications in the future. Furthermore, we release popular video-language pre-training models, ALPRO and mPLUG-2, and our proposed modularized decoder-only model mPLUG-video pre-trained on Youku-mPLUG. Experiments show that models pre-trained on Youku-mPLUG gain up to 23.1% improvement in video category classification. Besides, mPLUG-video achieves a new state-of-the-art result on these benchmarks with 80.5% top-1 accuracy in video category classification and 68.9 CIDEr score in video captioning, respectively. Finally, we scale up mPLUG-video based on the frozen Bloomz with only 1.7% trainable parameters as Chinese multimodal LLM, and demonstrate impressive instruction and video understanding ability. The zero-shot instruction understanding experiment indicates that pretraining with Youku-mPLUG can enhance the ability to comprehend overall and detailed visual semantics, recognize scene text, and leverage open-domain knowledge.
Retrieval Oriented Masking Pre-training Language Model for Dense Passage Retrieval
Oct 27, 2022Pre-trained language model (PTM) has been shown to yield powerful text representations for dense passage retrieval task. The Masked Language Modeling (MLM) is a major sub-task of the pre-training process. However, we found that the conventional random masking strategy tend to select a large number of tokens that have limited effect on the passage retrieval task (e,g. stop-words and punctuation). By noticing the term importance weight can provide valuable information for passage retrieval, we hereby propose alternative retrieval oriented masking (dubbed as ROM) strategy where more important tokens will have a higher probability of being masked out, to capture this straightforward yet essential information to facilitate the language model pre-training process. Notably, the proposed new token masking method will not change the architecture and learning objective of original PTM. Our experiments verify that the proposed ROM enables term importance information to help language model pre-training thus achieving better performance on multiple passage retrieval benchmarks.
HLATR: Enhance Multi-stage Text Retrieval with Hybrid List Aware Transformer Reranking
May 21, 2022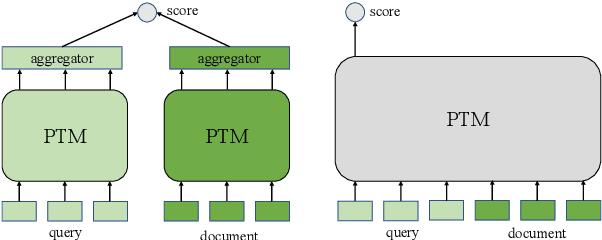
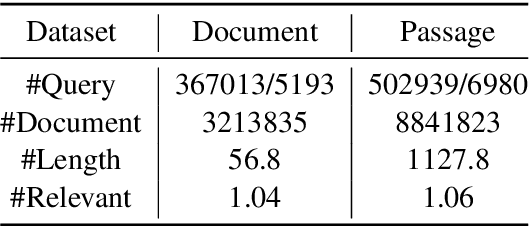
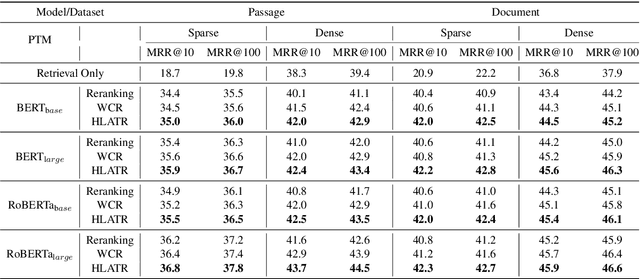
Deep pre-trained language models (e,g. BERT) are effective at large-scale text retrieval task. Existing text retrieval systems with state-of-the-art performance usually adopt a retrieve-then-reranking architecture due to the high computational cost of pre-trained language models and the large corpus size. Under such a multi-stage architecture, previous studies mainly focused on optimizing single stage of the framework thus improving the overall retrieval performance. However, how to directly couple multi-stage features for optimization has not been well studied. In this paper, we design Hybrid List Aware Transformer Reranking (HLATR) as a subsequent reranking module to incorporate both retrieval and reranking stage features. HLATR is lightweight and can be easily parallelized with existing text retrieval systems so that the reranking process can be performed in a single yet efficient processing. Empirical experiments on two large-scale text retrieval datasets show that HLATR can efficiently improve the ranking performance of existing multi-stage text retrieval methods.
Robust Self-Augmentation for Named Entity Recognition with Meta Reweighting
May 02, 2022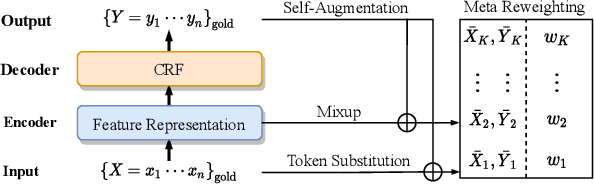
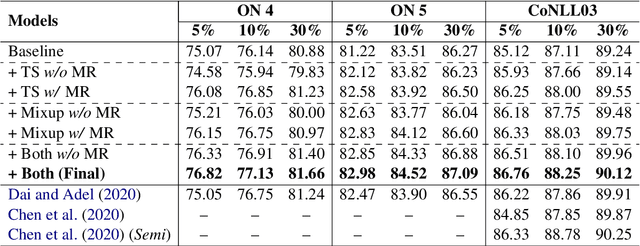
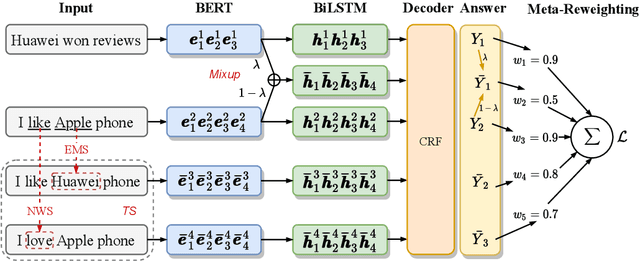
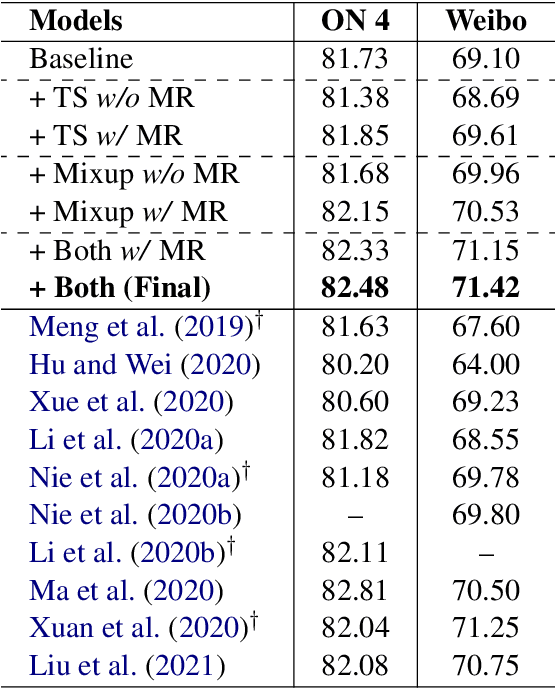
Self-augmentation has received increasing research interest recently to improve named entity recognition (NER) performance in low-resource scenarios. Token substitution and mixup are two feasible heterogeneous self-augmentation techniques for NER that can achieve effective performance with certain specialized efforts. Noticeably, self-augmentation may introduce potentially noisy augmented data. Prior research has mainly resorted to heuristic rule-based constraints to reduce the noise for specific self-augmentation methods individually. In this paper, we revisit these two typical self-augmentation methods for NER, and propose a unified meta-reweighting strategy for them to achieve a natural integration. Our method is easily extensible, imposing little effort on a specific self-augmentation method. Experiments on different Chinese and English NER benchmarks show that our token substitution and mixup method, as well as their integration, can achieve effective performance improvement. Based on the meta-reweighting mechanism, we can enhance the advantages of the self-augmentation techniques without much extra effort.
Identifying Chinese Opinion Expressions with Extremely-Noisy Crowdsourcing Annotations
Apr 22, 2022

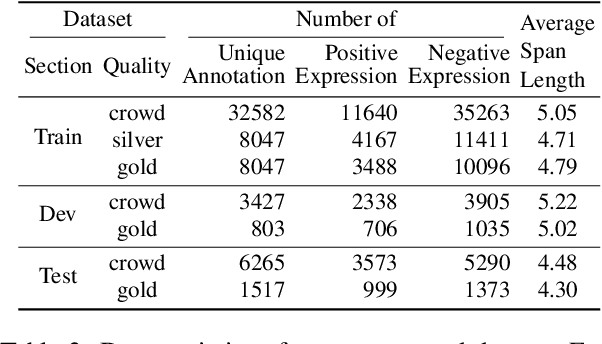
Recent works of opinion expression identification (OEI) rely heavily on the quality and scale of the manually-constructed training corpus, which could be extremely difficult to satisfy. Crowdsourcing is one practical solution for this problem, aiming to create a large-scale but quality-unguaranteed corpus. In this work, we investigate Chinese OEI with extremely-noisy crowdsourcing annotations, constructing a dataset at a very low cost. Following zhang et al. (2021), we train the annotator-adapter model by regarding all annotations as gold-standard in terms of crowd annotators, and test the model by using a synthetic expert, which is a mixture of all annotators. As this annotator-mixture for testing is never modeled explicitly in the training phase, we propose to generate synthetic training samples by a pertinent mixup strategy to make the training and testing highly consistent. The simulation experiments on our constructed dataset show that crowdsourcing is highly promising for OEI, and our proposed annotator-mixup can further enhance the crowdsourcing modeling.
Parallel Instance Query Network for Named Entity Recognition
Mar 20, 2022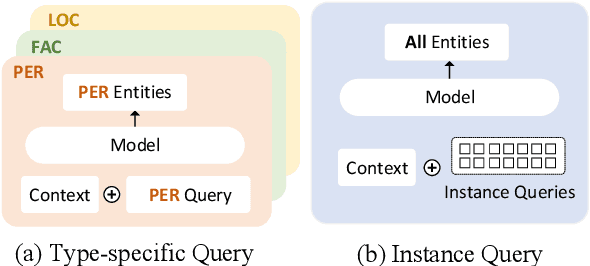
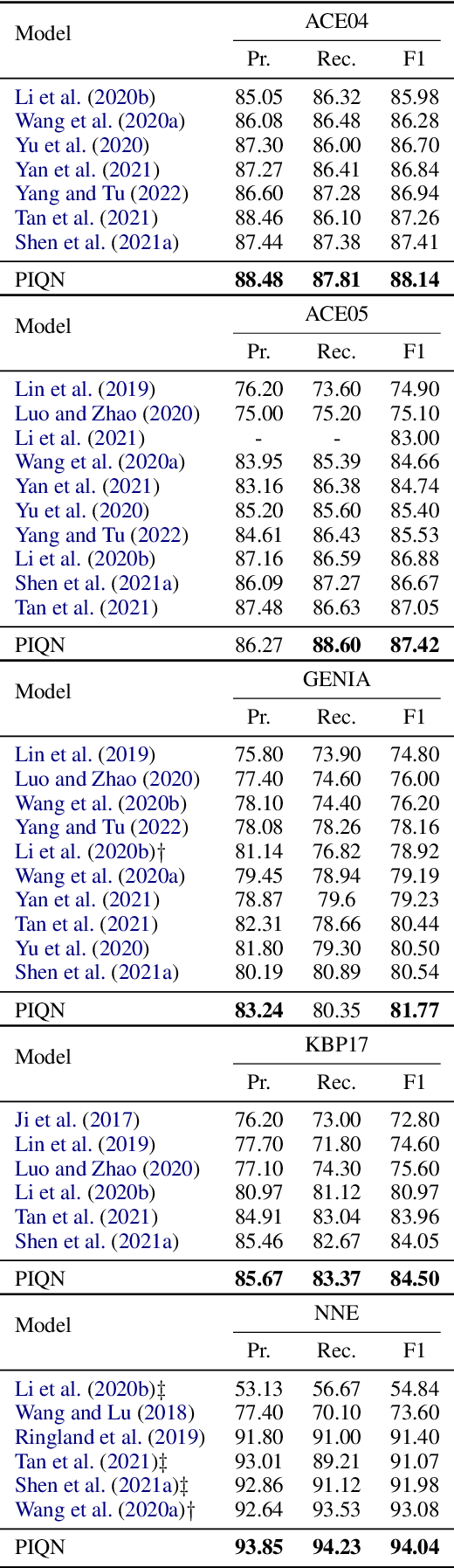
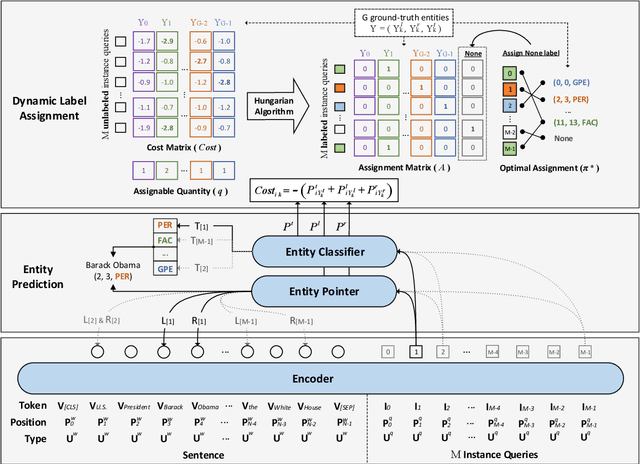
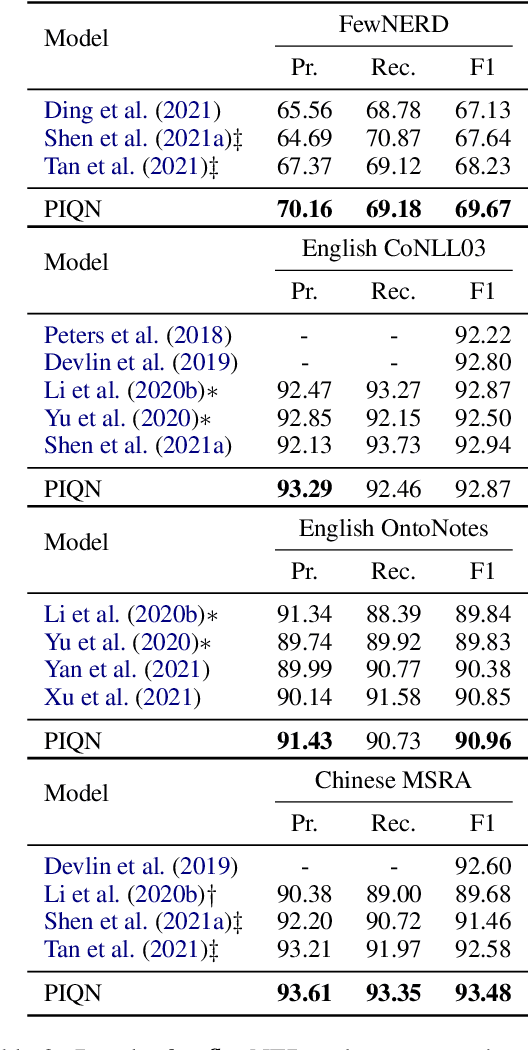
Named entity recognition (NER) is a fundamental task in natural language processing. Recent works treat named entity recognition as a reading comprehension task, constructing type-specific queries manually to extract entities. This paradigm suffers from three issues. First, type-specific queries can only extract one type of entities per inference, which is inefficient. Second, the extraction for different types of entities is isolated, ignoring the dependencies between them. Third, query construction relies on external knowledge and is difficult to apply to realistic scenarios with hundreds of entity types. To deal with them, we propose Parallel Instance Query Network (PIQN), which sets up global and learnable instance queries to extract entities from a sentence in a parallel manner. Each instance query predicts one entity, and by feeding all instance queries simultaneously, we can query all entities in parallel. Instead of being constructed from external knowledge, instance queries can learn their different query semantics during training. For training the model, we treat label assignment as a one-to-many Linear Assignment Problem (LAP) and dynamically assign gold entities to instance queries with minimal assignment cost. Experiments on both nested and flat NER datasets demonstrate that our proposed method outperforms previous state-of-the-art models.
Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval
Mar 07, 2022
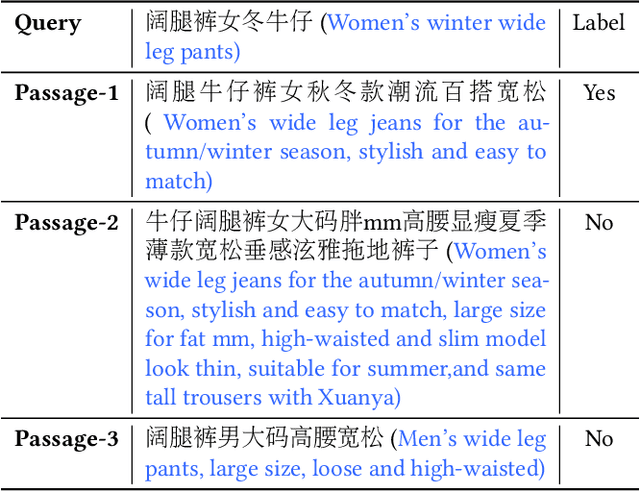
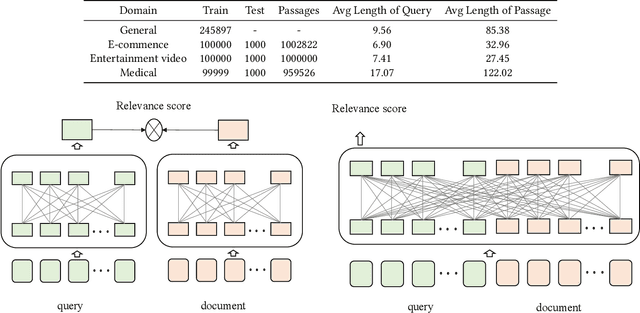
Passage retrieval is a fundamental task in information retrieval (IR) research, which has drawn much attention recently. In English field, the availability of large-scale annotated dataset (e.g, MS MARCO) and the emergence of deep pre-trained language models (e.g, BERT) have resulted in a substantial improvement of existing passage retrieval systems. However, in Chinese field, especially for specific domain, passage retrieval systems are still immature due to quality-annotated dataset being limited by scale. Therefore, in this paper, we present a novel multi-domain Chinese dataset for passage retrieval (Multi-CPR). The dataset is collected from three different domains, including E-commerce, Entertainment video and Medical. Each dataset contains millions of passages and a certain amount of human annotated query-passage related pairs. We implement various representative passage retrieval methods as baselines. We find that the performance of retrieval models trained on dataset from general domain will inevitably decrease on specific domain. Nevertheless, passage retrieval system built on in-domain annotated dataset can achieve significant improvement, which indeed demonstrates the necessity of domain labeled data for further optimization. We hope the release of the Multi-CPR dataset could benchmark Chinese passage retrieval task in specific domain and also make advances for future studies.