 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025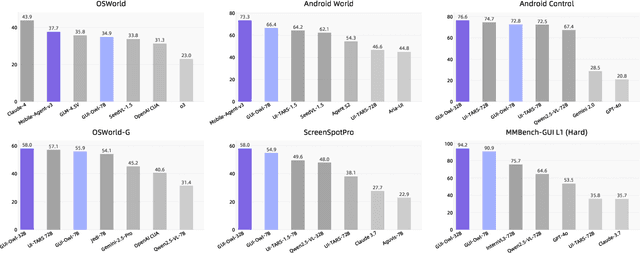
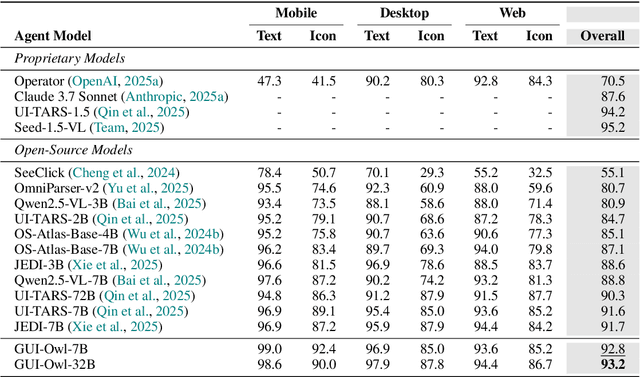
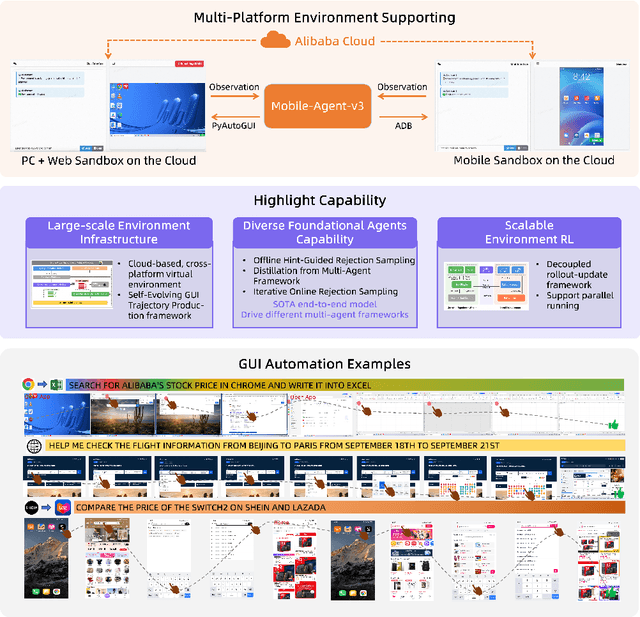
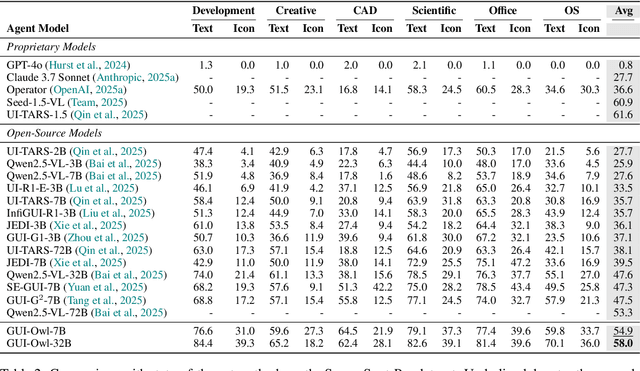
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
Jun 05, 2025In recent years, Multimodal Large Language Models (MLLMs) have been extensively utilized for multimodal reasoning tasks, including Graphical User Interface (GUI) automation. Unlike general offline multimodal tasks, GUI automation is executed in online interactive environments, necessitating step-by-step decision-making based on real-time status of the environment. This task has a lower tolerance for decision-making errors at each step, as any mistakes may cumulatively disrupt the process and potentially lead to irreversible outcomes like deletions or payments. To address these issues, we introduce a pre-operative critic mechanism that provides effective feedback prior to the actual execution, by reasoning about the potential outcome and correctness of actions. Specifically, we propose a Suggestion-aware Gradient Relative Policy Optimization (S-GRPO) strategy to construct our pre-operative critic model GUI-Critic-R1, incorporating a novel suggestion reward to enhance the reliability of the model's feedback. Furthermore, we develop a reasoning-bootstrapping based data collection pipeline to create a GUI-Critic-Train and a GUI-Critic-Test, filling existing gaps in GUI critic data. Static experiments on the GUI-Critic-Test across both mobile and web domains reveal that our GUI-Critic-R1 offers significant advantages in critic accuracy compared to current MLLMs. Dynamic evaluation on GUI automation benchmark further highlights the effectiveness and superiority of our model, as evidenced by improved success rates and operational efficiency.
AdaMMS: Model Merging for Heterogeneous Multimodal Large Language Models with Unsupervised Coefficient Optimization
Mar 31, 2025Recently, model merging methods have demonstrated powerful strengths in combining abilities on various tasks from multiple Large Language Models (LLMs). While previous model merging methods mainly focus on merging homogeneous models with identical architecture, they meet challenges when dealing with Multimodal Large Language Models (MLLMs) with inherent heterogeneous property, including differences in model architecture and the asymmetry in the parameter space. In this work, we propose AdaMMS, a novel model merging method tailored for heterogeneous MLLMs. Our method tackles the challenges in three steps: mapping, merging and searching. Specifically, we first design mapping function between models to apply model merging on MLLMs with different architecture. Then we apply linear interpolation on model weights to actively adapt the asymmetry in the heterogeneous MLLMs. Finally in the hyper-parameter searching step, we propose an unsupervised hyper-parameter selection method for model merging. As the first model merging method capable of merging heterogeneous MLLMs without labeled data, extensive experiments on various model combinations demonstrated that AdaMMS outperforms previous model merging methods on various vision-language benchmarks.
Qwen2.5-VL Technical Report
Feb 19, 2025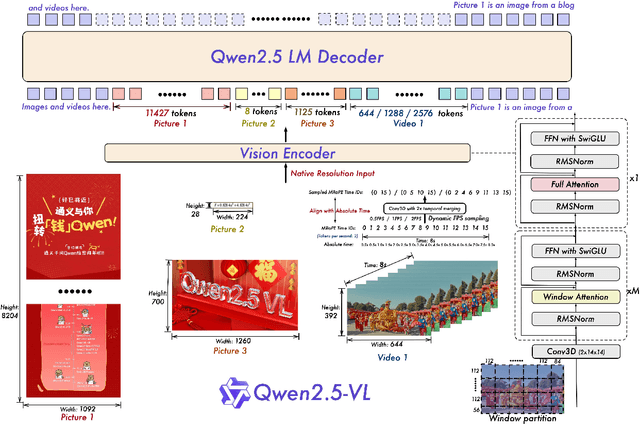
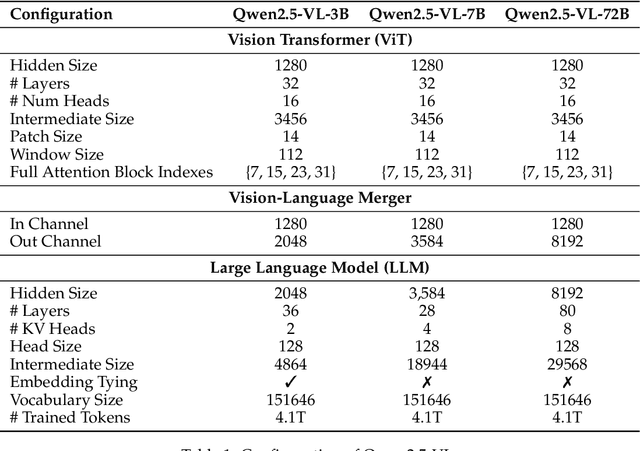
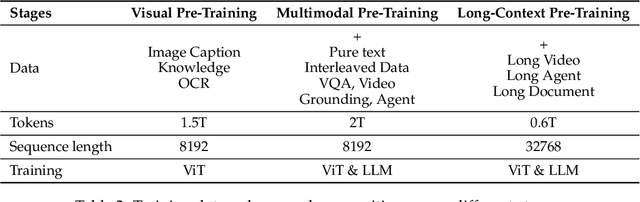
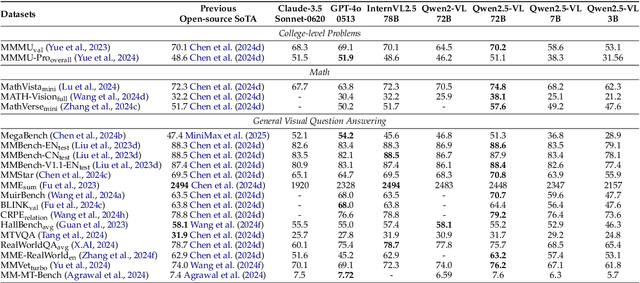
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
Sep 05, 2024



Multimodel Large Language Models(MLLMs) have achieved promising OCR-free Document Understanding performance by increasing the supported resolution of document images. However, this comes at the cost of generating thousands of visual tokens for a single document image, leading to excessive GPU memory and slower inference times, particularly in multi-page document comprehension. In this work, to address these challenges, we propose a High-resolution DocCompressor module to compress each high-resolution document image into 324 tokens, guided by low-resolution global visual features. With this compression module, to strengthen multi-page document comprehension ability and balance both token efficiency and question-answering performance, we develop the DocOwl2 under a three-stage training framework: Single-image Pretraining, Multi-image Continue-pretraining, and Multi-task Finetuning. DocOwl2 sets a new state-of-the-art across multi-page document understanding benchmarks and reduces first token latency by more than 50%, demonstrating advanced capabilities in multi-page questioning answering, explanation with evidence pages, and cross-page structure understanding. Additionally, compared to single-image MLLMs trained on similar data, our DocOwl2 achieves comparable single-page understanding performance with less than 20% of the visual tokens. Our codes, models, and data are publicly available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl2.
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Aug 09, 2024



Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in executing instructions for a variety of single-image tasks. Despite this progress, significant challenges remain in modeling long image sequences. In this work, we introduce the versatile multi-modal large language model, mPLUG-Owl3, which enhances the capability for long image-sequence understanding in scenarios that incorporate retrieved image-text knowledge, interleaved image-text, and lengthy videos. Specifically, we propose novel hyper attention blocks to efficiently integrate vision and language into a common language-guided semantic space, thereby facilitating the processing of extended multi-image scenarios. Extensive experimental results suggest that mPLUG-Owl3 achieves state-of-the-art performance among models with a similar size on single-image, multi-image, and video benchmarks. Moreover, we propose a challenging long visual sequence evaluation named Distractor Resistance to assess the ability of models to maintain focus amidst distractions. Finally, with the proposed architecture, mPLUG-Owl3 demonstrates outstanding performance on ultra-long visual sequence inputs. We hope that mPLUG-Owl3 can contribute to the development of more efficient and powerful multimodal large language models.
mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
Mar 19, 2024



Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal Large Language Models (MLLMs) for Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks. Our codes, models, and datasets are publicly available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5.
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Jan 29, 2024Mobile device agent based on Multimodal Large Language Models (MLLM) is becoming a popular application. In this paper, we introduce Mobile-Agent, an autonomous multi-modal mobile device agent. Mobile-Agent first leverages visual perception tools to accurately identify and locate both the visual and textual elements within the app's front-end interface. Based on the perceived vision context, it then autonomously plans and decomposes the complex operation task, and navigates the mobile Apps through operations step by step. Different from previous solutions that rely on XML files of Apps or mobile system metadata, Mobile-Agent allows for greater adaptability across diverse mobile operating environments in a vision-centric way, thereby eliminating the necessity for system-specific customizations. To assess the performance of Mobile-Agent, we introduced Mobile-Eval, a benchmark for evaluating mobile device operations. Based on Mobile-Eval, we conducted a comprehensive evaluation of Mobile-Agent. The experimental results indicate that Mobile-Agent achieved remarkable accuracy and completion rates. Even with challenging instructions, such as multi-app operations, Mobile-Agent can still complete the requirements. Code and model will be open-sourced at https://github.com/X-PLUG/MobileAgent.
mPLUG-PaperOwl: Scientific Diagram Analysis with the Multimodal Large Language Model
Nov 30, 2023



Recently, the strong text creation ability of Large Language Models(LLMs) has given rise to many tools for assisting paper reading or even writing. However, the weak diagram analysis abilities of LLMs or Multimodal LLMs greatly limit their application scenarios, especially for scientific academic paper writing. In this work, towards a more versatile copilot for academic paper writing, we mainly focus on strengthening the multi-modal diagram analysis ability of Multimodal LLMs. By parsing Latex source files of high-quality papers, we carefully build a multi-modal diagram understanding dataset M-Paper. By aligning diagrams in the paper with related paragraphs, we construct professional diagram analysis samples for training and evaluation. M-Paper is the first dataset to support joint comprehension of multiple scientific diagrams, including figures and tables in the format of images or Latex codes. Besides, to better align the copilot with the user's intention, we introduce the `outline' as the control signal, which could be directly given by the user or revised based on auto-generated ones. Comprehensive experiments with a state-of-the-art Mumtimodal LLM demonstrate that training on our dataset shows stronger scientific diagram understanding performance, including diagram captioning, diagram analysis, and outline recommendation. The dataset, code, and model are available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/PaperOwl.
mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
Nov 09, 2023Multi-modal Large Language Models (MLLMs) have demonstrated impressive instruction abilities across various open-ended tasks. However, previous methods primarily focus on enhancing multi-modal capabilities. In this work, we introduce a versatile multi-modal large language model, mPLUG-Owl2, which effectively leverages modality collaboration to improve performance in both text and multi-modal tasks. mPLUG-Owl2 utilizes a modularized network design, with the language decoder acting as a universal interface for managing different modalities. Specifically, mPLUG-Owl2 incorporates shared functional modules to facilitate modality collaboration and introduces a modality-adaptive module that preserves modality-specific features. Extensive experiments reveal that mPLUG-Owl2 is capable of generalizing both text tasks and multi-modal tasks and achieving state-of-the-art performances with a single generic model. Notably, mPLUG-Owl2 is the first MLLM model that demonstrates the modality collaboration phenomenon in both pure-text and multi-modal scenarios, setting a pioneering path in the development of future multi-modal foundation models.