 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Hippocampus Networks for Efficient Long-Context Modeling
Oct 08, 2025Long-sequence modeling faces a fundamental trade-off between the efficiency of compressive fixed-size memory in RNN-like models and the fidelity of lossless growing memory in attention-based Transformers. Inspired by the Multi-Store Model in cognitive science, we introduce a memory framework of artificial neural networks. Our method maintains a sliding window of the Transformer's KV cache as lossless short-term memory, while a learnable module termed Artificial Hippocampus Network (AHN) recurrently compresses out-of-window information into a fixed-size compact long-term memory. To validate this framework, we instantiate AHNs using modern RNN-like architectures, including Mamba2, DeltaNet, and Gated DeltaNet. Extensive experiments on long-context benchmarks LV-Eval and InfiniteBench demonstrate that AHN-augmented models consistently outperform sliding window baselines and achieve performance comparable or even superior to full-attention models, while substantially reducing computational and memory requirements. For instance, augmenting the Qwen2.5-3B-Instruct with AHNs reduces inference FLOPs by 40.5% and memory cache by 74.0%, while improving its average score on LV-Eval (128k sequence length) from 4.41 to 5.88. Code is available at: https://github.com/ByteDance-Seed/AHN.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Painting with Words: Elevating Detailed Image Captioning with Benchmark and Alignment Learning
Mar 10, 2025



Image captioning has long been a pivotal task in visual understanding, with recent advancements in vision-language models (VLMs) significantly enhancing the ability to generate detailed image captions. However, the evaluation of detailed image captioning remains underexplored due to outdated evaluation metrics and coarse annotations. In this paper, we introduce DeCapBench along with a novel metric, DCScore, specifically designed for detailed captioning tasks. DCScore evaluates hallucinations and fine-grained comprehensiveness by deconstructing responses into the smallest self-sufficient units, termed primitive information units, and assessing them individually. Our evaluation shows that DCScore aligns more closely with human judgment than other rule-based or model-based metrics. Concurrently, DeCapBench exhibits a high correlation with VLM arena results on descriptive tasks, surpassing existing benchmarks for vision-language models. Additionally, we present an automatic fine-grained feedback collection method, FeedQuill, for preference optimization based on our advanced metric, showing robust generalization capabilities across auto-generated preference data. Extensive experiments on multiple VLMs demonstrate that our method not only significantly reduces hallucinations but also enhances performance across various benchmarks, achieving superior detail captioning performance while surpassing GPT-4o.
LLaVA-Critic: Learning to Evaluate Multimodal Models
Oct 03, 2024We introduce LLaVA-Critic, the first open-source large multimodal model (LMM) designed as a generalist evaluator to assess performance across a wide range of multimodal tasks. LLaVA-Critic is trained using a high-quality critic instruction-following dataset that incorporates diverse evaluation criteria and scenarios. Our experiments demonstrate the model's effectiveness in two key areas: (1) LMM-as-a-Judge, where LLaVA-Critic provides reliable evaluation scores, performing on par with or surpassing GPT models on multiple evaluation benchmarks; and (2) Preference Learning, where it generates reward signals for preference learning, enhancing model alignment capabilities. This work underscores the potential of open-source LMMs in self-critique and evaluation, setting the stage for future research into scalable, superhuman alignment feedback mechanisms for LMMs.
MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
Jul 05, 2024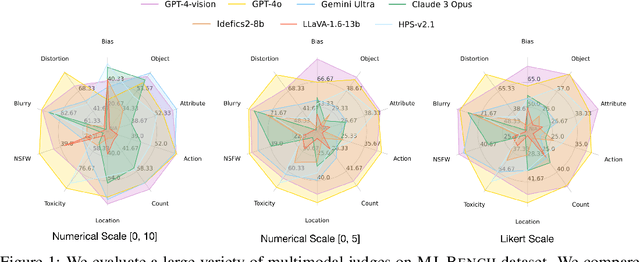
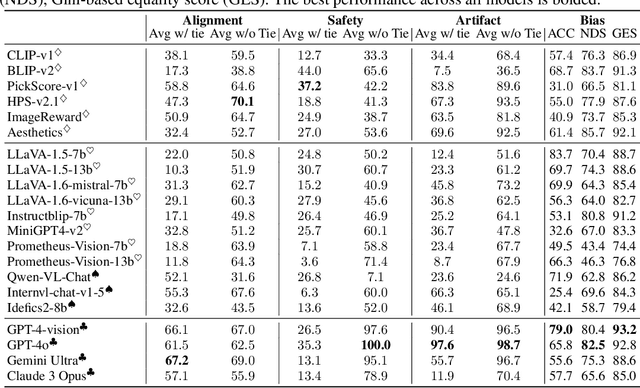

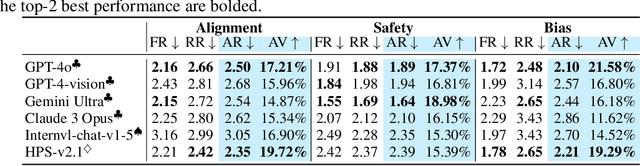
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes. To address this issue, we introduce MJ-Bench, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias. Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset. Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities. Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench. All data, code, models are available at https://huggingface.co/MJ-Bench.
Semantics-enhanced Cross-modal Masked Image Modeling for Vision-Language Pre-training
Mar 01, 2024In vision-language pre-training (VLP), masked image modeling (MIM) has recently been introduced for fine-grained cross-modal alignment. However, in most existing methods, the reconstruction targets for MIM lack high-level semantics, and text is not sufficiently involved in masked modeling. These two drawbacks limit the effect of MIM in facilitating cross-modal semantic alignment. In this work, we propose a semantics-enhanced cross-modal MIM framework (SemMIM) for vision-language representation learning. Specifically, to provide more semantically meaningful supervision for MIM, we propose a local semantics enhancing approach, which harvest high-level semantics from global image features via self-supervised agreement learning and transfer them to local patch encodings by sharing the encoding space. Moreover, to achieve deep involvement of text during the entire MIM process, we propose a text-guided masking strategy and devise an efficient way of injecting textual information in both masked modeling and reconstruction target acquisition. Experimental results validate that our method improves the effectiveness of the MIM task in facilitating cross-modal semantic alignment. Compared to previous VLP models with similar model size and data scale, our SemMIM model achieves state-of-the-art or competitive performance on multiple downstream vision-language tasks.
Unifying Latent and Lexicon Representations for Effective Video-Text Retrieval
Feb 26, 2024In video-text retrieval, most existing methods adopt the dual-encoder architecture for fast retrieval, which employs two individual encoders to extract global latent representations for videos and texts. However, they face challenges in capturing fine-grained semantic concepts. In this work, we propose the UNIFY framework, which learns lexicon representations to capture fine-grained semantics and combines the strengths of latent and lexicon representations for video-text retrieval. Specifically, we map videos and texts into a pre-defined lexicon space, where each dimension corresponds to a semantic concept. A two-stage semantics grounding approach is proposed to activate semantically relevant dimensions and suppress irrelevant dimensions. The learned lexicon representations can thus reflect fine-grained semantics of videos and texts. Furthermore, to leverage the complementarity between latent and lexicon representations, we propose a unified learning scheme to facilitate mutual learning via structure sharing and self-distillation. Experimental results show our UNIFY framework largely outperforms previous video-text retrieval methods, with 4.8% and 8.2% Recall@1 improvement on MSR-VTT and DiDeMo respectively.
TiMix: Text-aware Image Mixing for Effective Vision-Language Pre-training
Dec 14, 2023
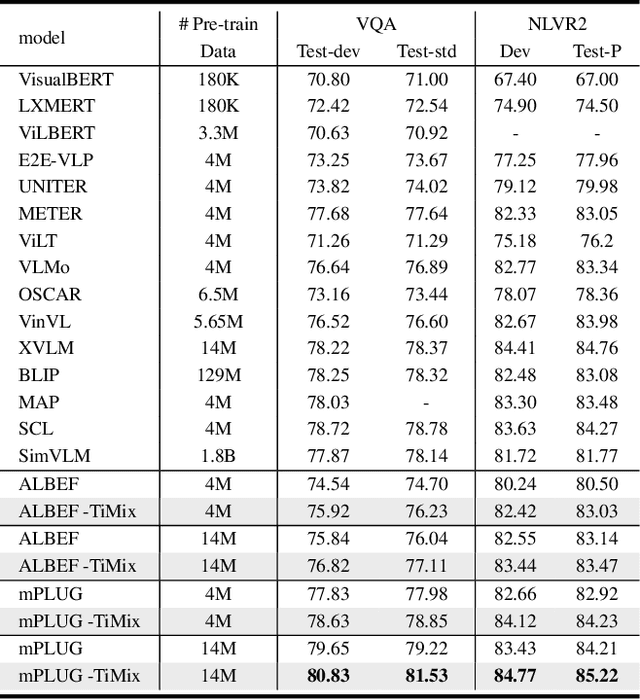

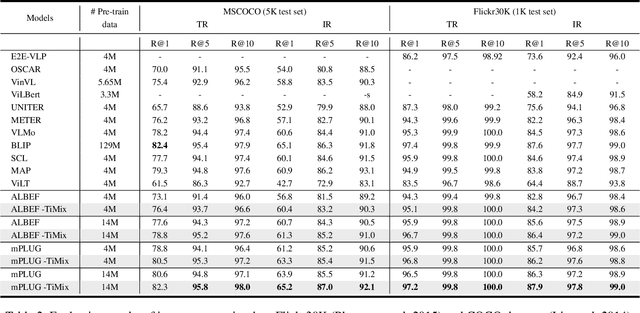
Self-supervised Multi-modal Contrastive Learning (SMCL) remarkably advances modern Vision-Language Pre-training (VLP) models by aligning visual and linguistic modalities. Due to noises in web-harvested text-image pairs, however, scaling up training data volume in SMCL presents considerable obstacles in terms of computational cost and data inefficiency. To improve data efficiency in VLP, we propose Text-aware Image Mixing (TiMix), which integrates mix-based data augmentation techniques into SMCL, yielding significant performance improvements without significantly increasing computational overhead. We provide a theoretical analysis of TiMixfrom a mutual information (MI) perspective, showing that mixed data samples for cross-modal contrastive learning implicitly serve as a regularizer for the contrastive loss. The experimental results demonstrate that TiMix exhibits a comparable performance on downstream tasks, even with a reduced amount of training data and shorter training time, when benchmarked against existing methods. This work empirically and theoretically demonstrates the potential of data mixing for data-efficient and computationally viable VLP, benefiting broader VLP model adoption in practical scenarios.
Hallucination Augmented Contrastive Learning for Multimodal Large Language Model
Dec 13, 2023Multi-modal large language models (MLLMs) have been shown to efficiently integrate natural language with visual information to handle multi-modal tasks. However, MLLMs still face a fundamental limitation of hallucinations, where they tend to generate erroneous or fabricated information. In this paper, we address hallucinations in MLLMs from a novel perspective of representation learning. We first analyzed the representation distribution of textual and visual tokens in MLLM, revealing two important findings: 1) there is a significant gap between textual and visual representations, indicating unsatisfactory cross-modal representation alignment; 2) representations of texts that contain and do not contain hallucinations are entangled, making it challenging to distinguish them. These two observations inspire us with a simple yet effective method to mitigate hallucinations. Specifically, we introduce contrastive learning into MLLMs and use text with hallucination as hard negative examples, naturally bringing representations of non-hallucinative text and visual samples closer while pushing way representations of non-hallucinating and hallucinative text. We evaluate our method quantitatively and qualitatively, showing its effectiveness in reducing hallucination occurrences and improving performance across multiple benchmarks. On the MMhal-Bench benchmark, our method obtains a 34.66% /29.5% improvement over the baseline MiniGPT-4/LLaVA.
mPLUG-PaperOwl: Scientific Diagram Analysis with the Multimodal Large Language Model
Nov 30, 2023



Recently, the strong text creation ability of Large Language Models(LLMs) has given rise to many tools for assisting paper reading or even writing. However, the weak diagram analysis abilities of LLMs or Multimodal LLMs greatly limit their application scenarios, especially for scientific academic paper writing. In this work, towards a more versatile copilot for academic paper writing, we mainly focus on strengthening the multi-modal diagram analysis ability of Multimodal LLMs. By parsing Latex source files of high-quality papers, we carefully build a multi-modal diagram understanding dataset M-Paper. By aligning diagrams in the paper with related paragraphs, we construct professional diagram analysis samples for training and evaluation. M-Paper is the first dataset to support joint comprehension of multiple scientific diagrams, including figures and tables in the format of images or Latex codes. Besides, to better align the copilot with the user's intention, we introduce the `outline' as the control signal, which could be directly given by the user or revised based on auto-generated ones. Comprehensive experiments with a state-of-the-art Mumtimodal LLM demonstrate that training on our dataset shows stronger scientific diagram understanding performance, including diagram captioning, diagram analysis, and outline recommendation. The dataset, code, and model are available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/PaperOwl.