 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole-Playing Agents Driven by Large Language Models: Current Status, Challenges, and Future Trends
Jan 15, 2026In recent years, with the rapid advancement of large language models (LLMs), role-playing language agents (RPLAs) have emerged as a prominent research focus at the intersection of natural language processing (NLP) and human-computer interaction. This paper systematically reviews the current development and key technologies of RPLAs, delineating the technological evolution from early rule-based template paradigms, through the language style imitation stage, to the cognitive simulation stage centered on personality modeling and memory mechanisms. It summarizes the critical technical pathways supporting high-quality role-playing, including psychological scale-driven character modeling, memory-augmented prompting mechanisms, and motivation-situation-based behavioral decision control. At the data level, the paper further analyzes the methods and challenges of constructing role-specific corpora, focusing on data sources, copyright constraints, and structured annotation processes. In terms of evaluation, it collates multi-dimensional assessment frameworks and benchmark datasets covering role knowledge, personality fidelity, value alignment, and interactive hallucination, while commenting on the advantages and disadvantages of methods such as human evaluation, reward models, and LLM-based scoring. Finally, the paper outlines future development directions of role-playing agents, including personality evolution modeling, multi-agent collaborative narrative, multimodal immersive interaction, and integration with cognitive neuroscience, aiming to provide a systematic perspective and methodological insights for subsequent research.
CloseUpShot: Close-up Novel View Synthesis from Sparse-views via Point-conditioned Diffusion Model
Nov 17, 2025Reconstructing 3D scenes and synthesizing novel views from sparse input views is a highly challenging task. Recent advances in video diffusion models have demonstrated strong temporal reasoning capabilities, making them a promising tool for enhancing reconstruction quality under sparse-view settings. However, existing approaches are primarily designed for modest viewpoint variations, which struggle in capturing fine-grained details in close-up scenarios since input information is severely limited. In this paper, we present a diffusion-based framework, called CloseUpShot, for close-up novel view synthesis from sparse inputs via point-conditioned video diffusion. Specifically, we observe that pixel-warping conditioning suffers from severe sparsity and background leakage in close-up settings. To address this, we propose hierarchical warping and occlusion-aware noise suppression, enhancing the quality and completeness of the conditioning images for the video diffusion model. Furthermore, we introduce global structure guidance, which leverages a dense fused point cloud to provide consistent geometric context to the diffusion process, to compensate for the lack of globally consistent 3D constraints in sparse conditioning inputs. Extensive experiments on multiple datasets demonstrate that our method outperforms existing approaches, especially in close-up novel view synthesis, clearly validating the effectiveness of our design.
Transfer Learning in Vocal Education: Technical Evaluation of Limited Samples Describing Mezzo-soprano
Oct 30, 2024



Vocal education in the music field is difficult to quantify due to the individual differences in singers' voices and the different quantitative criteria of singing techniques. Deep learning has great potential to be applied in music education due to its efficiency to handle complex data and perform quantitative analysis. However, accurate evaluations with limited samples over rare vocal types, such as Mezzo-soprano, requires extensive well-annotated data support using deep learning models. In order to attain the objective, we perform transfer learning by employing deep learning models pre-trained on the ImageNet and Urbansound8k datasets for the improvement on the precision of vocal technique evaluation. Furthermore, we tackle the problem of the lack of samples by constructing a dedicated dataset, the Mezzo-soprano Vocal Set (MVS), for vocal technique assessment. Our experimental results indicate that transfer learning increases the overall accuracy (OAcc) of all models by an average of 8.3%, with the highest accuracy at 94.2%. We not only provide a novel approach to evaluating Mezzo-soprano vocal techniques but also introduce a new quantitative assessment method for music education.
Local map Construction Methods with SD map: A Novel Survey
Sep 04, 2024In recent years, significant academic advancements have been made in the field of autonomous vehicles, with Local maps emerging as a crucial component of autonomous driving technology. Local maps not only provide intricate details of road networks but also serve as fundamental inputs for critical tasks such as vehicle localization, navigation, and decision-making. Given the characteristics of SD map (Standard Definition Map), which include low cost, ease of acquisition, and high versatility, perception methods that integrate SD map as prior information have demonstrated significant potential in the field of Local map perception. The purpose of this paper is to provide researchers with a comprehensive overview and summary of the latest advancements in the integration of SD map as prior information for Local map perception methods. This review begins by introducing the task definition and general pipeline of local map perception methods that incorporate SD maps as prior information, along with relevant public datasets. And then it focuses on the representation and encoding methods of multi-source information, as well as the methods for fusing multi-source information. In response to this burgeoning trend, this article presents a comprehensive and meticulous overview of the diverse research efforts in this particular field. Finally, the article addresses pertinent issues and future challenges with the aim of guiding researchers in understanding the current trends and methodologies prevalent in the field.
Risk Occupancy: A New and Efficient Paradigm through Vehicle-Road-Cloud Collaboration
Aug 14, 2024



This study introduces the 4D Risk Occupancy within a vehicle-road-cloud architecture, integrating the road surface spatial, risk, and temporal dimensions, and endowing the algorithm with beyond-line-of-sight, all-angles, and efficient abilities. The algorithm simplifies risk modeling by focusing on directly observable information and key factors, drawing on the concept of Occupancy Grid Maps (OGM), and incorporating temporal prediction to effectively map current and future risk occupancy. Compared to conventional driving risk fields and grid occupancy maps, this algorithm can map global risks more efficiently, simply, and reliably. It can integrate future risk information, adapting to dynamic traffic environments. The 4D Risk Occupancy also unifies the expression of BEV detection and lane line detection results, enhancing the intuitiveness and unity of environmental perception. Using DAIR-V2X data, this paper validates the 4D Risk Occupancy algorithm and develops a local path planning model based on it. Qualitative experiments under various road conditions demonstrate the practicality and robustness of this local path planning model. Quantitative analysis shows that the path planning based on risk occupation significantly improves trajectory planning performance, increasing safety redundancy by 12.5% and reducing average deceleration by 5.41% at an initial braking speed of 8 m/s, thereby improving safety and comfort. This work provides a new global perception method and local path planning method through Vehicle-Road-Cloud architecture, offering a new perceptual paradigm for achieving safer and more efficient autonomous driving.
Plug-and-Play Grounding of Reasoning in Multimodal Large Language Models
Mar 28, 2024
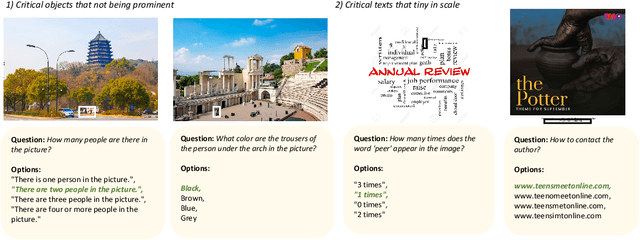


The surge of Multimodal Large Language Models (MLLMs), given their prominent emergent capabilities in instruction following and reasoning, has greatly advanced the field of visual reasoning. However, constrained by their non-lossless image tokenization, most MLLMs fall short of comprehensively capturing details of text and objects, especially in high-resolution images. To address this, we propose P2G, a novel framework for plug-and-play grounding of reasoning in MLLMs. Specifically, P2G exploits the tool-usage potential of MLLMs to employ expert agents to achieve on-the-fly grounding to critical visual and textual objects of image, thus achieving deliberate reasoning via multimodal prompting. We further create P2GB, a benchmark aimed at assessing MLLMs' ability to understand inter-object relationships and text in challenging high-resolution images. Comprehensive experiments on visual reasoning tasks demonstrate the superiority of P2G. Noteworthy, P2G achieved comparable performance with GPT-4V on P2GB, with a 7B backbone. Our work highlights the potential of plug-and-play grounding of reasoning and opens up a promising alternative beyond model scaling.
Aerial Lifting: Neural Urban Semantic and Building Instance Lifting from Aerial Imagery
Mar 18, 2024
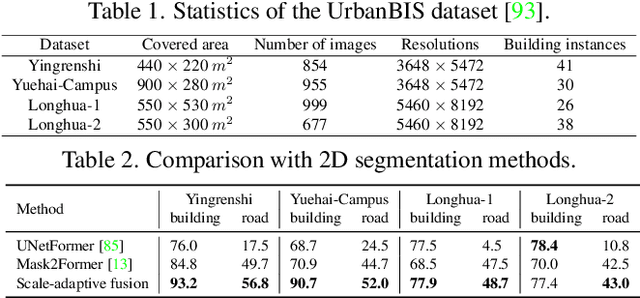


We present a neural radiance field method for urban-scale semantic and building-level instance segmentation from aerial images by lifting noisy 2D labels to 3D. This is a challenging problem due to two primary reasons. Firstly, objects in urban aerial images exhibit substantial variations in size, including buildings, cars, and roads, which pose a significant challenge for accurate 2D segmentation. Secondly, the 2D labels generated by existing segmentation methods suffer from the multi-view inconsistency problem, especially in the case of aerial images, where each image captures only a small portion of the entire scene. To overcome these limitations, we first introduce a scale-adaptive semantic label fusion strategy that enhances the segmentation of objects of varying sizes by combining labels predicted from different altitudes, harnessing the novel-view synthesis capabilities of NeRF. We then introduce a novel cross-view instance label grouping strategy based on the 3D scene representation to mitigate the multi-view inconsistency problem in the 2D instance labels. Furthermore, we exploit multi-view reconstructed depth priors to improve the geometric quality of the reconstructed radiance field, resulting in enhanced segmentation results. Experiments on multiple real-world urban-scale datasets demonstrate that our approach outperforms existing methods, highlighting its effectiveness.
Hallucination Augmented Contrastive Learning for Multimodal Large Language Model
Dec 13, 2023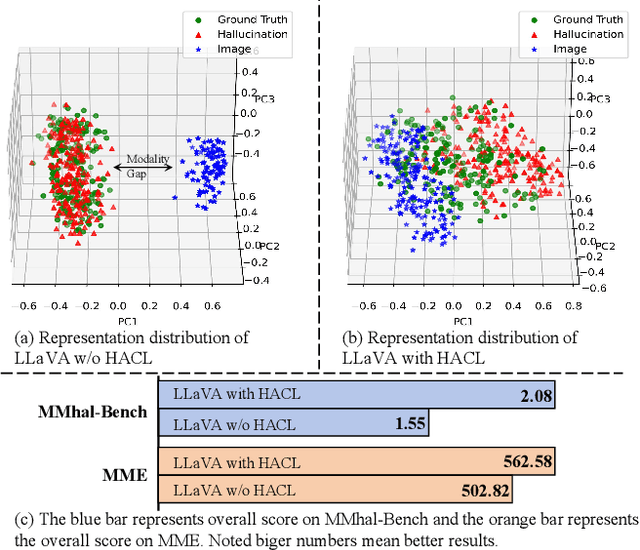
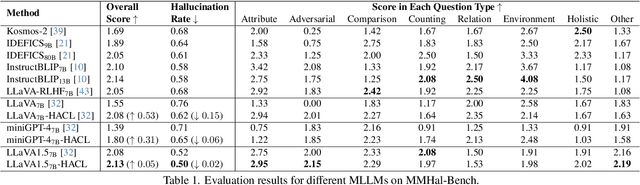
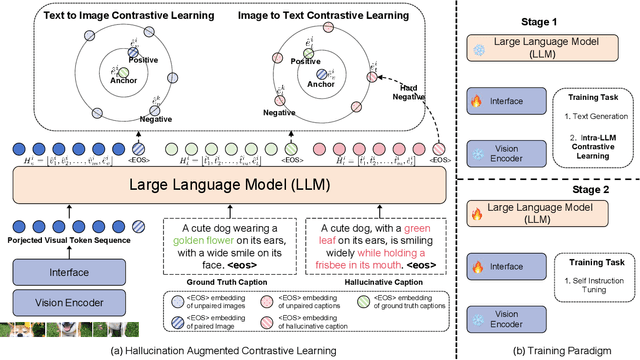
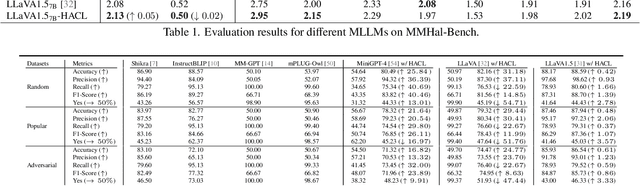
Multi-modal large language models (MLLMs) have been shown to efficiently integrate natural language with visual information to handle multi-modal tasks. However, MLLMs still face a fundamental limitation of hallucinations, where they tend to generate erroneous or fabricated information. In this paper, we address hallucinations in MLLMs from a novel perspective of representation learning. We first analyzed the representation distribution of textual and visual tokens in MLLM, revealing two important findings: 1) there is a significant gap between textual and visual representations, indicating unsatisfactory cross-modal representation alignment; 2) representations of texts that contain and do not contain hallucinations are entangled, making it challenging to distinguish them. These two observations inspire us with a simple yet effective method to mitigate hallucinations. Specifically, we introduce contrastive learning into MLLMs and use text with hallucination as hard negative examples, naturally bringing representations of non-hallucinative text and visual samples closer while pushing way representations of non-hallucinating and hallucinative text. We evaluate our method quantitatively and qualitatively, showing its effectiveness in reducing hallucination occurrences and improving performance across multiple benchmarks. On the MMhal-Bench benchmark, our method obtains a 34.66% /29.5% improvement over the baseline MiniGPT-4/LLaVA.