 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient, Validation-Free Intrinsic Quality Estimation for Large-Scale Face Recognition Datasets
May 28, 2026We propose Intrinsic Quality (IQ), a validation-free metric designed to estimate the inherent potential of face recognition (FR) datasets to produce high-performance models without the need for full-scale training. IQ integrates two components: (i) a Neighbor-Consistency Score that quantifies local identity label agreement via nearest neighbors, and (ii) Global Representation Subspace Complexity (Effective Rank, ER), which captures the underlying embedding geometry and dataset diversity. IQ allows for rapid evaluation using lightweight proxy models or data subsets, facilitating dataset diagnosis and curation prior to resource-intensive full-scale training. We describe an experimental protocol tailored to clean, noisy, and mixed-quality FR datasets, and outline evaluation methodologies to validate IQ's predictive power for downstream performance.
UniDoc-RL: Coarse-to-Fine Visual RAG with Hierarchical Actions and Dense Rewards
Apr 16, 2026Retrieval-Augmented Generation (RAG) extends Large Vision-Language Models (LVLMs) with external visual knowledge. However, existing visual RAG systems typically rely on generic retrieval signals that overlook the fine-grained visual semantics essential for complex reasoning. To address this limitation, we propose UniDoc-RL, a unified reinforcement learning framework in which an LVLM agent jointly performs retrieval, reranking, active visual perception, and reasoning. UniDoc-RL formulates visual information acquisition as a sequential decision-making problem with a hierarchical action space. Specifically, it progressively refines visual evidence from coarse-grained document retrieval to fine-grained image selection and active region cropping, allowing the model to suppress irrelevant content and attend to information-dense regions. For effective end-to-end training, we introduce a dense multi-reward scheme that provides task-aware supervision for each action. Based on Group Relative Policy Optimization (GRPO), UniDoc-RL aligns agent behavior with multiple objectives without relying on a separate value network. To support this training paradigm, we curate a comprehensive dataset of high-quality reasoning trajectories with fine-grained action annotations. Experiments on three benchmarks demonstrate that UniDoc-RL consistently surpasses state-of-the-art baselines, yielding up to 17.7% gains over prior RL-based methods.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.
Croc: Pretraining Large Multimodal Models with Cross-Modal Comprehension
Oct 18, 2024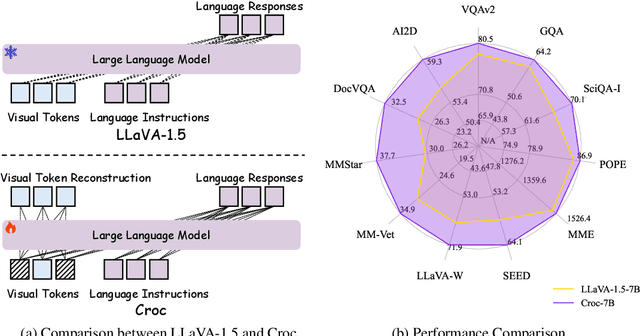
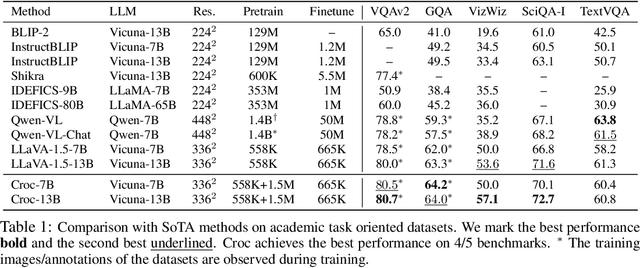
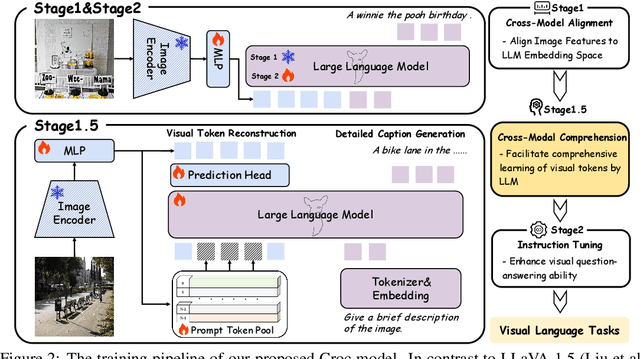
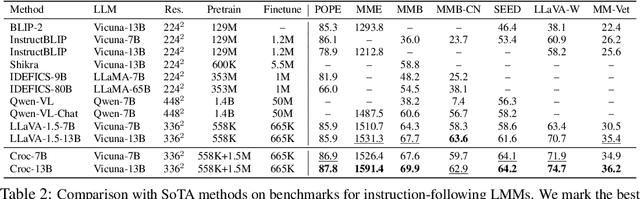
Recent advances in Large Language Models (LLMs) have catalyzed the development of Large Multimodal Models (LMMs). However, existing research primarily focuses on tuning language and image instructions, ignoring the critical pretraining phase where models learn to process textual and visual modalities jointly. In this paper, we propose a new pretraining paradigm for LMMs to enhance the visual comprehension capabilities of LLMs by introducing a novel cross-modal comprehension stage. Specifically, we design a dynamically learnable prompt token pool and employ the Hungarian algorithm to replace part of the original visual tokens with the most relevant prompt tokens. Then, we conceptualize visual tokens as analogous to a "foreign language" for the LLMs and propose a mixed attention mechanism with bidirectional visual attention and unidirectional textual attention to comprehensively enhance the understanding of visual tokens. Meanwhile, we integrate a detailed caption generation task, leveraging rich descriptions to further facilitate LLMs in understanding visual semantic information. After pretraining on 1.5 million publicly accessible data, we present a new foundation model called Croc. Experimental results demonstrate that Croc achieves new state-of-the-art performance on massive vision-language benchmarks. To support reproducibility and facilitate further research, we release the training code and pre-trained model weights at https://github.com/deepglint/Croc.
Plug-and-Play Grounding of Reasoning in Multimodal Large Language Models
Mar 28, 2024


The surge of Multimodal Large Language Models (MLLMs), given their prominent emergent capabilities in instruction following and reasoning, has greatly advanced the field of visual reasoning. However, constrained by their non-lossless image tokenization, most MLLMs fall short of comprehensively capturing details of text and objects, especially in high-resolution images. To address this, we propose P2G, a novel framework for plug-and-play grounding of reasoning in MLLMs. Specifically, P2G exploits the tool-usage potential of MLLMs to employ expert agents to achieve on-the-fly grounding to critical visual and textual objects of image, thus achieving deliberate reasoning via multimodal prompting. We further create P2GB, a benchmark aimed at assessing MLLMs' ability to understand inter-object relationships and text in challenging high-resolution images. Comprehensive experiments on visual reasoning tasks demonstrate the superiority of P2G. Noteworthy, P2G achieved comparable performance with GPT-4V on P2GB, with a 7B backbone. Our work highlights the potential of plug-and-play grounding of reasoning and opens up a promising alternative beyond model scaling.
IDAdapter: Learning Mixed Features for Tuning-Free Personalization of Text-to-Image Models
Mar 21, 2024Leveraging Stable Diffusion for the generation of personalized portraits has emerged as a powerful and noteworthy tool, enabling users to create high-fidelity, custom character avatars based on their specific prompts. However, existing personalization methods face challenges, including test-time fine-tuning, the requirement of multiple input images, low preservation of identity, and limited diversity in generated outcomes. To overcome these challenges, we introduce IDAdapter, a tuning-free approach that enhances the diversity and identity preservation in personalized image generation from a single face image. IDAdapter integrates a personalized concept into the generation process through a combination of textual and visual injections and a face identity loss. During the training phase, we incorporate mixed features from multiple reference images of a specific identity to enrich identity-related content details, guiding the model to generate images with more diverse styles, expressions, and angles compared to previous works. Extensive evaluations demonstrate the effectiveness of our method, achieving both diversity and identity fidelity in generated images.
EasyQuant: Post-training Quantization via Scale Optimization
Jun 30, 2020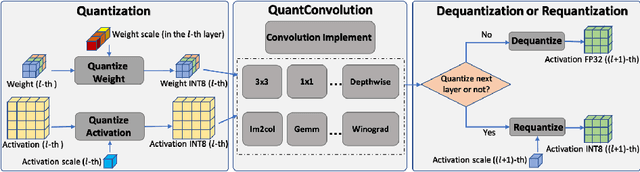
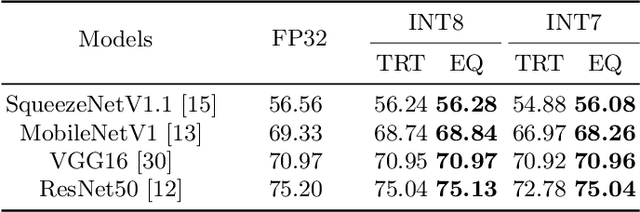
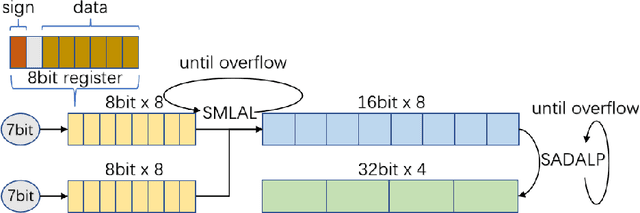
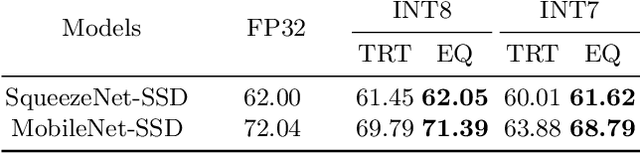
The 8 bits quantization has been widely applied to accelerate network inference in various deep learning applications. There are two kinds of quantization methods, training-based quantization and post-training quantization. Training-based approach suffers from a cumbersome training process, while post-training quantization may lead to unacceptable accuracy drop. In this paper, we present an efficient and simple post-training method via scale optimization, named EasyQuant (EQ),that could obtain comparable accuracy with the training-based method.Specifically, we first alternately optimize scales of weights and activations for all layers target at convolutional outputs to further obtain the high quantization precision. Then, we lower down bit width to INT7 both for weights and activations, and adopt INT16 intermediate storage and integer Winograd convolution implementation to accelerate inference.Experimental results on various computer vision tasks show that EQ outperforms the TensorRT method and can achieve near INT8 accuracy in 7 bits width post-training.