 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDoc-RL: Coarse-to-Fine Visual RAG with Hierarchical Actions and Dense Rewards
Apr 16, 2026Retrieval-Augmented Generation (RAG) extends Large Vision-Language Models (LVLMs) with external visual knowledge. However, existing visual RAG systems typically rely on generic retrieval signals that overlook the fine-grained visual semantics essential for complex reasoning. To address this limitation, we propose UniDoc-RL, a unified reinforcement learning framework in which an LVLM agent jointly performs retrieval, reranking, active visual perception, and reasoning. UniDoc-RL formulates visual information acquisition as a sequential decision-making problem with a hierarchical action space. Specifically, it progressively refines visual evidence from coarse-grained document retrieval to fine-grained image selection and active region cropping, allowing the model to suppress irrelevant content and attend to information-dense regions. For effective end-to-end training, we introduce a dense multi-reward scheme that provides task-aware supervision for each action. Based on Group Relative Policy Optimization (GRPO), UniDoc-RL aligns agent behavior with multiple objectives without relying on a separate value network. To support this training paradigm, we curate a comprehensive dataset of high-quality reasoning trajectories with fine-grained action annotations. Experiments on three benchmarks demonstrate that UniDoc-RL consistently surpasses state-of-the-art baselines, yielding up to 17.7% gains over prior RL-based methods.
DanQing: An Up-to-Date Large-Scale Chinese Vision-Language Pre-training Dataset
Jan 15, 2026Vision-Language Pre-training (VLP) models demonstrate strong performance across various downstream tasks by learning from large-scale image-text pairs through contrastive pretraining. The release of extensive English image-text datasets (e.g., COYO-700M and LAION-400M) has enabled widespread adoption of models such as CLIP and SigLIP in tasks including cross-modal retrieval and image captioning. However, the advancement of Chinese vision-language pretraining has substantially lagged behind, due to the scarcity of high-quality Chinese image-text data. To address this gap, we develop a comprehensive pipeline for constructing a high-quality Chinese cross-modal dataset. As a result, we propose DanQing, which contains 100 million image-text pairs collected from Common Crawl. Different from existing datasets, DanQing is curated through a more rigorous selection process, yielding superior data quality. Moreover, DanQing is primarily built from 2024-2025 web data, enabling models to better capture evolving semantic trends and thus offering greater practical utility. We compare DanQing with existing datasets by continual pre-training of the SigLIP2 model. Experimental results show that DanQing consistently achieves superior performance across a range of Chinese downstream tasks, including zero-shot classification, cross-modal retrieval, and LMM-based evaluations. To facilitate further research in Chinese vision-language pre-training, we will open-source the DanQing dataset under the Creative Common CC-BY 4.0 license.
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
Apr 24, 2025The Contrastive Language-Image Pre-training (CLIP) framework has become a widely used approach for multimodal representation learning, particularly in image-text retrieval and clustering. However, its efficacy is constrained by three key limitations: (1) text token truncation, (2) isolated image-text encoding, and (3) deficient compositionality due to bag-of-words behavior. While recent Multimodal Large Language Models (MLLMs) have demonstrated significant advances in generalized vision-language understanding, their potential for learning transferable multimodal representations remains underexplored.In this work, we present UniME (Universal Multimodal Embedding), a novel two-stage framework that leverages MLLMs to learn discriminative representations for diverse downstream tasks. In the first stage, we perform textual discriminative knowledge distillation from a powerful LLM-based teacher model to enhance the embedding capability of the MLLM\'s language component. In the second stage, we introduce hard negative enhanced instruction tuning to further advance discriminative representation learning. Specifically, we initially mitigate false negative contamination and then sample multiple hard negatives per instance within each batch, forcing the model to focus on challenging samples. This approach not only improves discriminative power but also enhances instruction-following ability in downstream tasks. We conduct extensive experiments on the MMEB benchmark and multiple retrieval tasks, including short and long caption retrieval and compositional retrieval. Results demonstrate that UniME achieves consistent performance improvement across all tasks, exhibiting superior discriminative and compositional capabilities.
RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
Feb 18, 2025
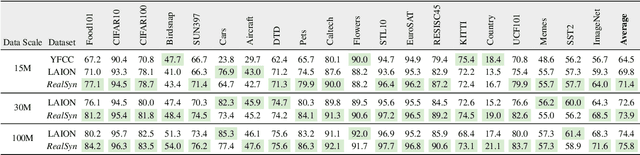


After pre-training on extensive image-text pairs, Contrastive Language-Image Pre-training (CLIP) demonstrates promising performance on a wide variety of benchmarks. However, a substantial volume of non-paired data, such as multimodal interleaved documents, remains underutilized for vision-language representation learning. To fully leverage these unpaired documents, we initially establish a Real-World Data Extraction pipeline to extract high-quality images and texts. Then we design a hierarchical retrieval method to efficiently associate each image with multiple semantically relevant realistic texts. To further enhance fine-grained visual information, we propose an image semantic augmented generation module for synthetic text production. Furthermore, we employ a semantic balance sampling strategy to improve dataset diversity, enabling better learning of long-tail concepts. Based on these innovations, we construct RealSyn, a dataset combining realistic and synthetic texts, available in three scales: 15M, 30M, and 100M. Extensive experiments demonstrate that RealSyn effectively advances vision-language representation learning and exhibits strong scalability. Models pre-trained on RealSyn achieve state-of-the-art performance on multiple downstream tasks. To facilitate future research, the RealSyn dataset and pre-trained model weights are released at https://github.com/deepglint/RealSyn.
ORID: Organ-Regional Information Driven Framework for Radiology Report Generation
Nov 20, 2024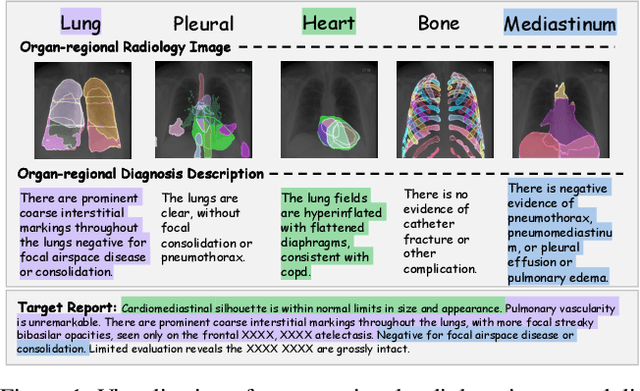
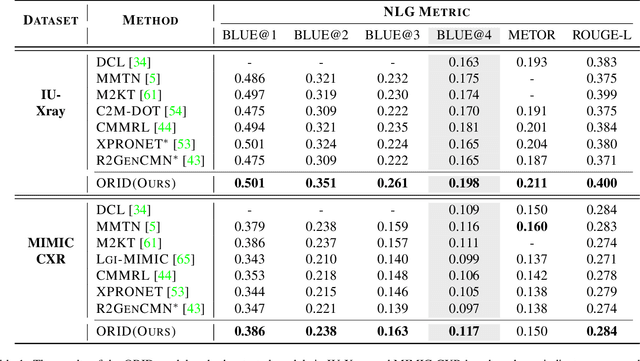
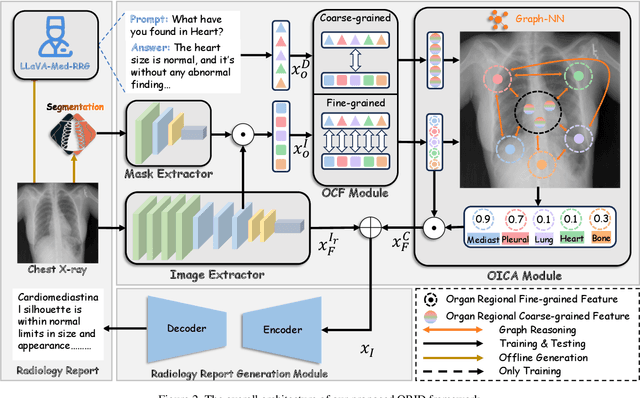
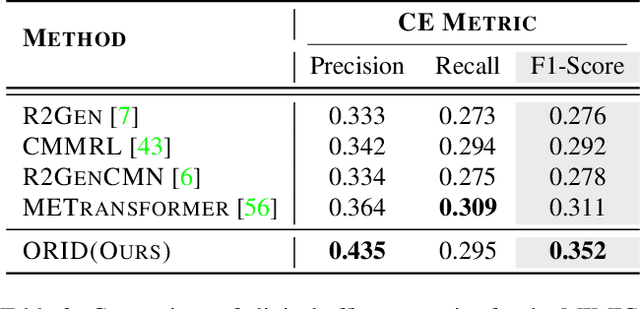
The objective of Radiology Report Generation (RRG) is to automatically generate coherent textual analyses of diseases based on radiological images, thereby alleviating the workload of radiologists. Current AI-based methods for RRG primarily focus on modifications to the encoder-decoder model architecture. To advance these approaches, this paper introduces an Organ-Regional Information Driven (ORID) framework which can effectively integrate multi-modal information and reduce the influence of noise from unrelated organs. Specifically, based on the LLaVA-Med, we first construct an RRG-related instruction dataset to improve organ-regional diagnosis description ability and get the LLaVA-Med-RRG. After that, we propose an organ-based cross-modal fusion module to effectively combine the information from the organ-regional diagnosis description and radiology image. To further reduce the influence of noise from unrelated organs on the radiology report generation, we introduce an organ importance coefficient analysis module, which leverages Graph Neural Network (GNN) to examine the interconnections of the cross-modal information of each organ region. Extensive experiments an1d comparisons with state-of-the-art methods across various evaluation metrics demonstrate the superior performance of our proposed method.
Croc: Pretraining Large Multimodal Models with Cross-Modal Comprehension
Oct 18, 2024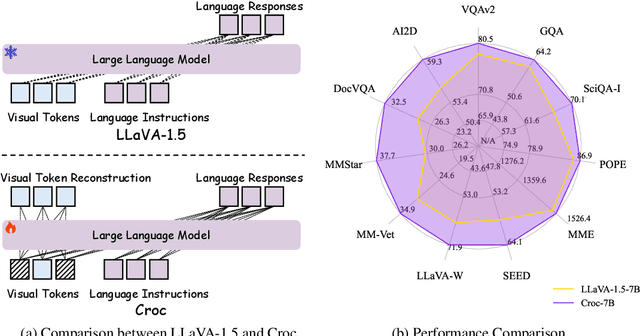
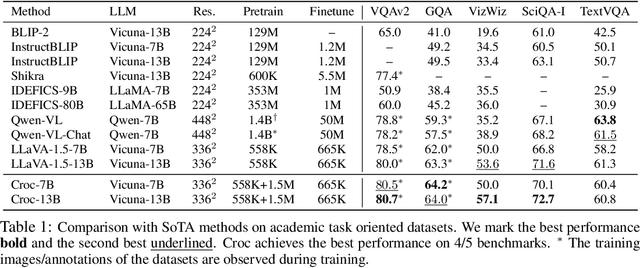
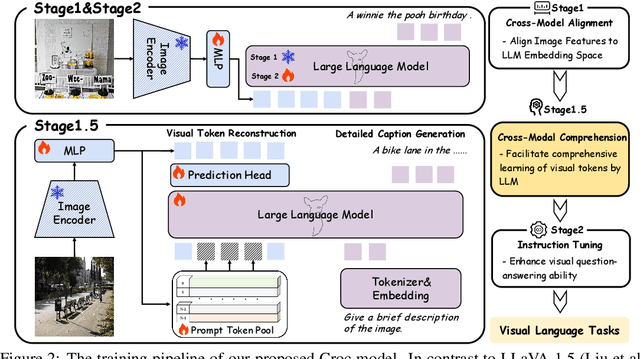
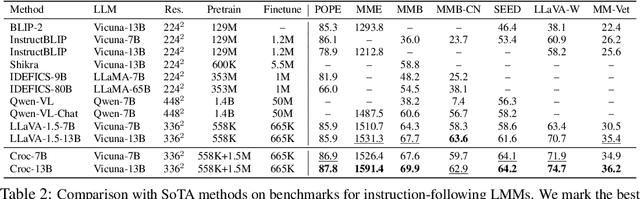
Recent advances in Large Language Models (LLMs) have catalyzed the development of Large Multimodal Models (LMMs). However, existing research primarily focuses on tuning language and image instructions, ignoring the critical pretraining phase where models learn to process textual and visual modalities jointly. In this paper, we propose a new pretraining paradigm for LMMs to enhance the visual comprehension capabilities of LLMs by introducing a novel cross-modal comprehension stage. Specifically, we design a dynamically learnable prompt token pool and employ the Hungarian algorithm to replace part of the original visual tokens with the most relevant prompt tokens. Then, we conceptualize visual tokens as analogous to a "foreign language" for the LLMs and propose a mixed attention mechanism with bidirectional visual attention and unidirectional textual attention to comprehensively enhance the understanding of visual tokens. Meanwhile, we integrate a detailed caption generation task, leveraging rich descriptions to further facilitate LLMs in understanding visual semantic information. After pretraining on 1.5 million publicly accessible data, we present a new foundation model called Croc. Experimental results demonstrate that Croc achieves new state-of-the-art performance on massive vision-language benchmarks. To support reproducibility and facilitate further research, we release the training code and pre-trained model weights at https://github.com/deepglint/Croc.
CLIP-CID: Efficient CLIP Distillation via Cluster-Instance Discrimination
Aug 18, 2024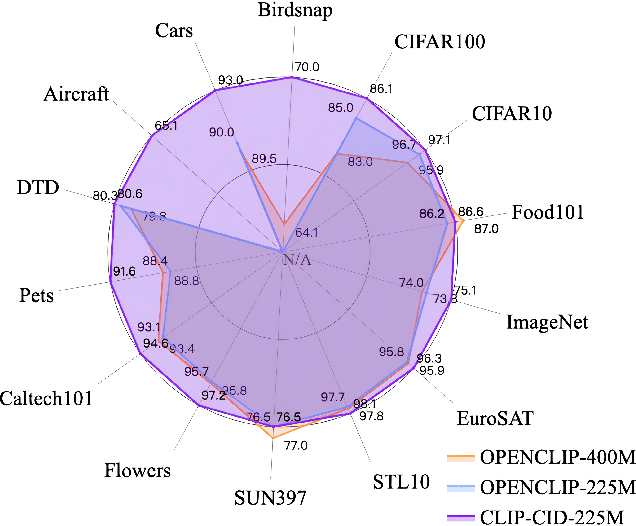
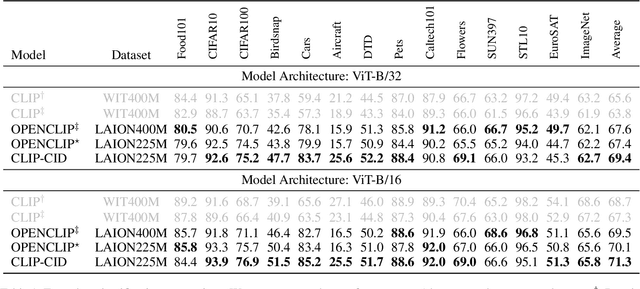
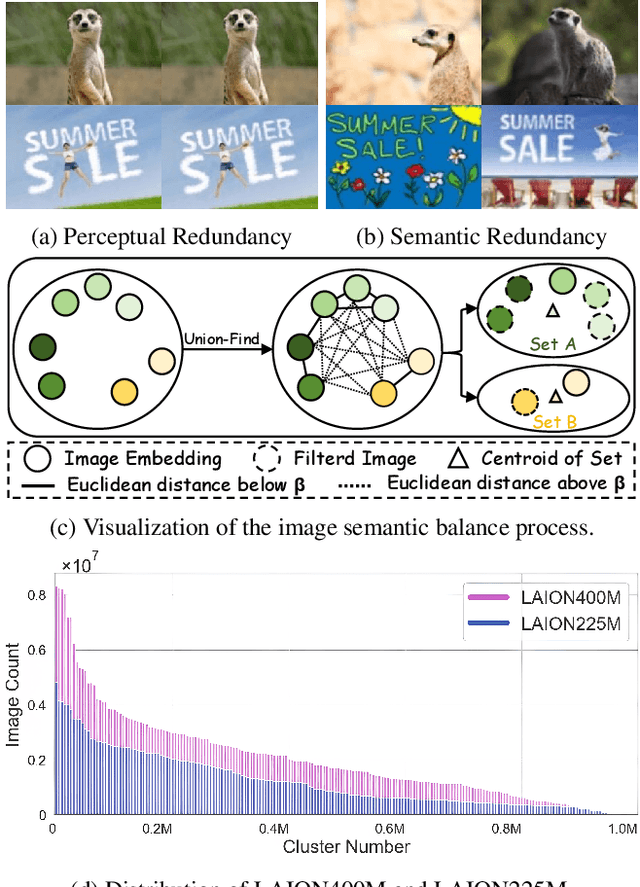
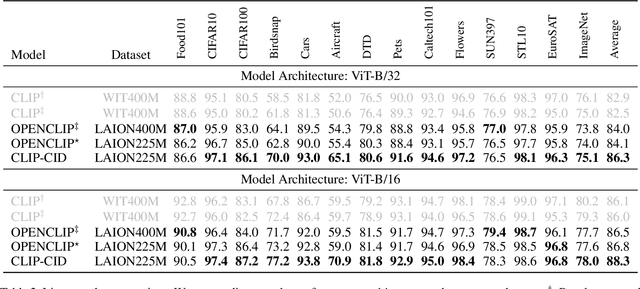
Contrastive Language-Image Pre-training (CLIP) has achieved excellent performance over a wide range of tasks. However, the effectiveness of CLIP heavily relies on a substantial corpus of pre-training data, resulting in notable consumption of computational resources. Although knowledge distillation has been widely applied in single modality models, how to efficiently expand knowledge distillation to vision-language foundation models with extensive data remains relatively unexplored. In this paper, we introduce CLIP-CID, a novel distillation mechanism that effectively transfers knowledge from a large vision-language foundation model to a smaller model. We initially propose a simple but efficient image semantic balance method to reduce transfer learning bias and improve distillation efficiency. This method filters out 43.7% of image-text pairs from the LAION400M while maintaining superior performance. After that, we leverage cluster-instance discrimination to facilitate knowledge transfer from the teacher model to the student model, thereby empowering the student model to acquire a holistic semantic comprehension of the pre-training data. Experimental results demonstrate that CLIP-CID achieves state-of-the-art performance on various downstream tasks including linear probe and zero-shot classification.
RWKV-CLIP: A Robust Vision-Language Representation Learner
Jun 11, 2024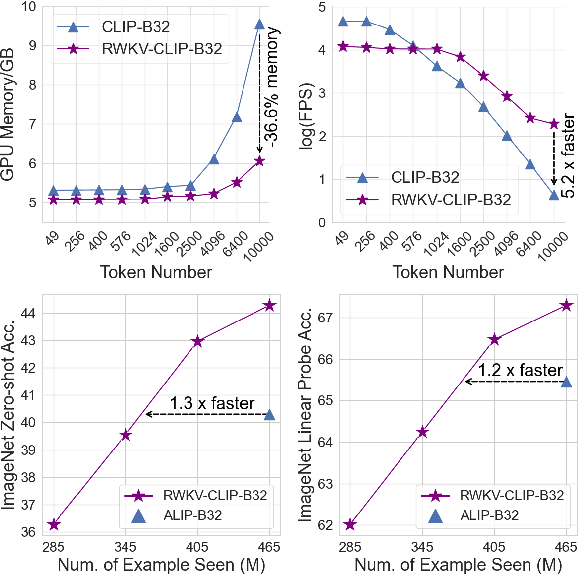
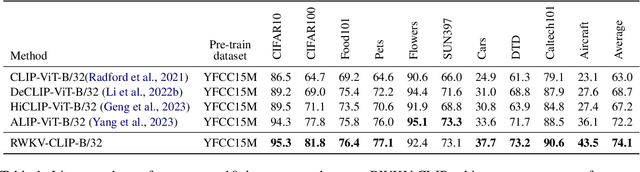
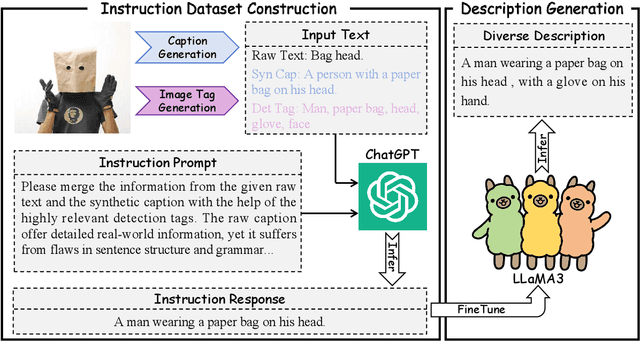
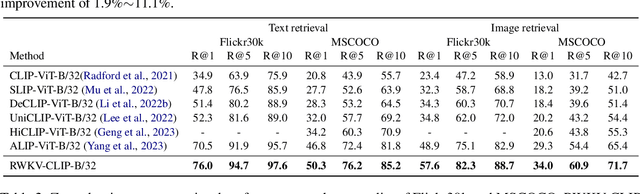
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
LaPA: Latent Prompt Assist Model For Medical Visual Question Answering
Apr 19, 2024Medical visual question answering (Med-VQA) aims to automate the prediction of correct answers for medical images and questions, thereby assisting physicians in reducing repetitive tasks and alleviating their workload. Existing approaches primarily focus on pre-training models using additional and comprehensive datasets, followed by fine-tuning to enhance performance in downstream tasks. However, there is also significant value in exploring existing models to extract clinically relevant information. In this paper, we propose the Latent Prompt Assist model (LaPA) for medical visual question answering. Firstly, we design a latent prompt generation module to generate the latent prompt with the constraint of the target answer. Subsequently, we propose a multi-modal fusion block with latent prompt fusion module that utilizes the latent prompt to extract clinical-relevant information from uni-modal and multi-modal features. Additionally, we introduce a prior knowledge fusion module to integrate the relationship between diseases and organs with the clinical-relevant information. Finally, we combine the final integrated information with image-language cross-modal information to predict the final answers. Experimental results on three publicly available Med-VQA datasets demonstrate that LaPA outperforms the state-of-the-art model ARL, achieving improvements of 1.83%, 0.63%, and 1.80% on VQA-RAD, SLAKE, and VQA-2019, respectively. The code is publicly available at https://github.com/GaryGuTC/LaPA_model.
Towards Optimal Customized Architecture for Heterogeneous Federated Learning with Contrastive Cloud-Edge Model Decoupling
Mar 04, 2024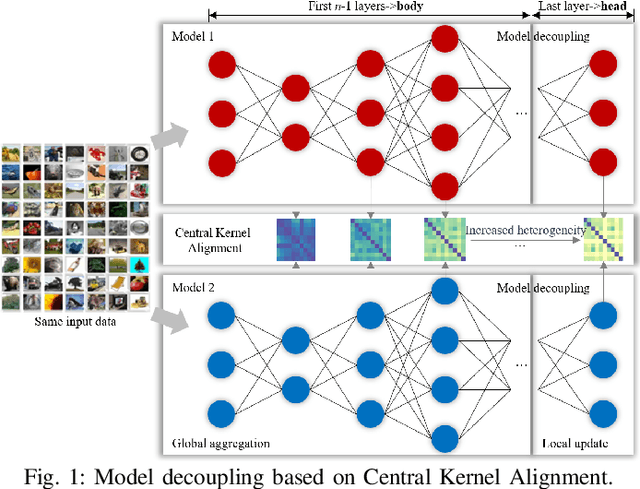
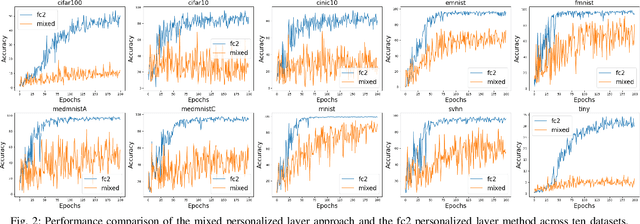
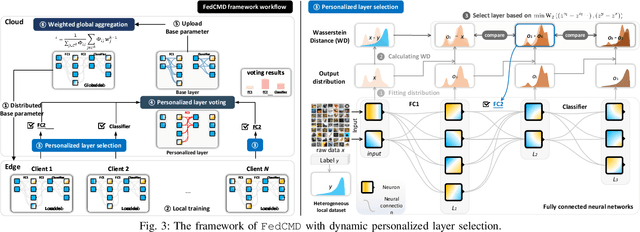
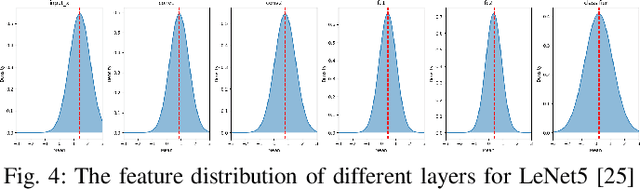
Federated learning, as a promising distributed learning paradigm, enables collaborative training of a global model across multiple network edge clients without the need for central data collecting. However, the heterogeneity of edge data distribution drags the model towards the local minima, which can be distant from the global optimum. Such heterogeneity often leads to slow convergence and substantial communication overhead. To address these issues, we propose a novel federated learning framework called FedCMD, a model decoupling tailored to the Cloud-edge supported federated learning that separates deep neural networks into a body for capturing shared representations in Cloud and a personalized head for migrating data heterogeneity. Our motivation is that, by the deep investigation of the performance of selecting different neural network layers as the personalized head, we found rigidly assigning the last layer as the personalized head in current studies is not always optimal. Instead, it is necessary to dynamically select the personalized layer that maximizes the training performance by taking the representation difference between neighbor layers into account. To find the optimal personalized layer, we utilize the low-dimensional representation of each layer to contrast feature distribution transfer and introduce a Wasserstein-based layer selection method, aimed at identifying the best-match layer for personalization. Additionally, a weighted global aggregation algorithm is proposed based on the selected personalized layer for the practical application of FedCMD. Extensive experiments on ten benchmarks demonstrate the efficiency and superior performance of our solution compared with nine state-of-the-art solutions. All code and results are available at https://github.com/elegy112138/FedCMD.