 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMFormer: Empowering Self-supervised Stereo Matching via Foundation Models and Data Augmentation
Apr 11, 2026Recent self-supervised stereo matching methods have made significant progress. They typically rely on the photometric consistency assumption, which presumes corresponding points across views share the same appearance. However, this assumption could be compromised by real-world disturbances, resulting in invalid supervisory signals and a significant accuracy gap compared to supervised methods. To address this issue, we propose SMFormer, a framework integrating more reliable self-supervision guided by the Vision Foundation Model (VFM) and data augmentation. We first incorporate the VFM with the Feature Pyramid Network (FPN), providing a discriminative and robust feature representation against disturbance in various scenarios. We then devise an effective data augmentation mechanism that ensures robustness to various transformations. The data augmentation mechanism explicitly enforces consistency between learned features and those influenced by illumination variations. Additionally, it regularizes the output consistency between disparity predictions of strong augmented samples and those generated from standard samples. Experiments on multiple mainstream benchmarks demonstrate that our SMFormer achieves state-of-the-art (SOTA) performance among self-supervised methods and even competes on par with supervised ones. Remarkably, in the challenging Booster benchmark, SMFormer even outperforms some SOTA supervised methods, such as CFNet.
Fine-Grained Motion Compression and Selective Temporal Fusion for Neural B-Frame Video Coding
Jun 09, 2025With the remarkable progress in neural P-frame video coding, neural B-frame coding has recently emerged as a critical research direction. However, most existing neural B-frame codecs directly adopt P-frame coding tools without adequately addressing the unique challenges of B-frame compression, leading to suboptimal performance. To bridge this gap, we propose novel enhancements for motion compression and temporal fusion for neural B-frame coding. First, we design a fine-grained motion compression method. This method incorporates an interactive dual-branch motion auto-encoder with per-branch adaptive quantization steps, which enables fine-grained compression of bi-directional motion vectors while accommodating their asymmetric bitrate allocation and reconstruction quality requirements. Furthermore, this method involves an interactive motion entropy model that exploits correlations between bi-directional motion latent representations by interactively leveraging partitioned latent segments as directional priors. Second, we propose a selective temporal fusion method that predicts bi-directional fusion weights to achieve discriminative utilization of bi-directional multi-scale temporal contexts with varying qualities. Additionally, this method introduces a hyperprior-based implicit alignment mechanism for contextual entropy modeling. By treating the hyperprior as a surrogate for the contextual latent representation, this mechanism implicitly mitigates the misalignment in the fused bi-directional temporal priors. Extensive experiments demonstrate that our proposed codec outperforms state-of-the-art neural B-frame codecs and achieves comparable or even superior compression performance to the H.266/VVC reference software under random-access configurations.
SIMAC: A Semantic-Driven Integrated Multimodal Sensing And Communication Framework
Mar 11, 2025Traditional single-modality sensing faces limitations in accuracy and capability, and its decoupled implementation with communication systems increases latency in bandwidth-constrained environments. Additionally, single-task-oriented sensing systems fail to address users' diverse demands. To overcome these challenges, we propose a semantic-driven integrated multimodal sensing and communication (SIMAC) framework. This framework leverages a joint source-channel coding architecture to achieve simultaneous sensing decoding and transmission of sensing results. Specifically, SIMAC first introduces a multimodal semantic fusion (MSF) network, which employs two extractors to extract semantic information from radar signals and images, respectively. MSF then applies cross-attention mechanisms to fuse these unimodal features and generate multimodal semantic representations. Secondly, we present a large language model (LLM)-based semantic encoder (LSE), where relevant communication parameters and multimodal semantics are mapped into a unified latent space and input to the LLM, enabling channel-adaptive semantic encoding. Thirdly, a task-oriented sensing semantic decoder (SSD) is proposed, in which different decoded heads are designed according to the specific needs of tasks. Simultaneously, a multi-task learning strategy is introduced to train the SIMAC framework, achieving diverse sensing services. Finally, experimental simulations demonstrate that the proposed framework achieves diverse sensing services and higher accuracy.
Adaptive Subarray Segmentation: A New Paradigm of Spatial Non-Stationary Near-Field Channel Estimation for XL-MIMO Systems
Mar 06, 2025



To tackle the complexities of spatial non-stationary (SnS) effects and spherical wave propagation in near-field channel estimation (CE) for extremely large-scale multiple-input multiple-output (XL-MIMO) systems, this paper introduces an innovative SnS near-field CE framework grounded in adaptive subarray partitioning. Conventional methods relying on equal subarray partitioning often lead to suboptimal divisions, undermining CE precision. To overcome this, we propose an adaptive subarray segmentation approach. First, we develop a spherical-wave channel model customized for line-of-sight (LoS) XL-MIMO systems to capture SnS traits. Next, we define and evaluate the adverse effects of over-segmentation and under-segmentation on CE efficacy. To counter these issues, we introduce a novel dynamic hybrid beamforming-assisted power-based subarray segmentation paradigm (DHBF-PSSP), which merges cost-effective power measurements with a DHBF structure, enabling joint subarray partitioning and decoupling. A robust partitioning algorithm, termed power-adaptive subarray segmentation (PASS), exploits statistical features of power profiles, while the DHBF utilizes subarray segmentation-based group time block code (SS-GTBC) to enable efficient subarray decoupling with limited radio frequency (RF) chain resources. Additionally, by utilizing angular-domain block sparsity and inter-subcarrier structured sparsity, we propose a subarray segmentation-based assorted block sparse Bayesian learning algorithm under the multiple measurement vectors framework (SS-ABSBL-MMV), employing discrete Fourier transform (DFT) codebooks to lower complexity. Extensive simulation results validate the exceptional performance of the proposed framework over its counterparts.
From Dense to Sparse: Event Response for Enhanced Residential Load Forecasting
Jan 08, 2025


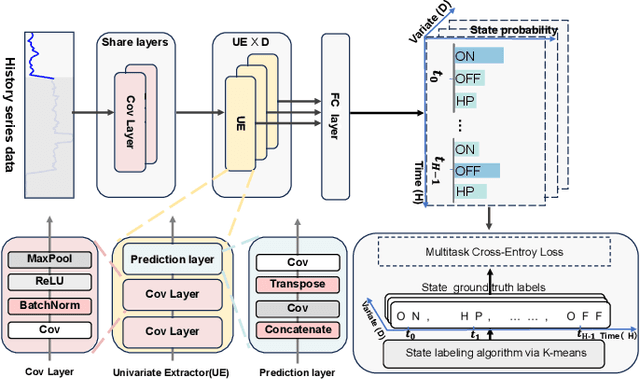
Residential load forecasting (RLF) is crucial for resource scheduling in power systems. Most existing methods utilize all given load records (dense data) to indiscriminately extract the dependencies between historical and future time series. However, there exist important regular patterns residing in the event-related associations among different appliances (sparse knowledge), which have yet been ignored. In this paper, we propose an Event-Response Knowledge Guided approach (ERKG) for RLF by incorporating the estimation of electricity usage events for different appliances, mining event-related sparse knowledge from the load series. With ERKG, the event-response estimation enables portraying the electricity consumption behaviors of residents, revealing regular variations in appliance operational states. To be specific, ERKG consists of knowledge extraction and guidance: i) a forecasting model is designed for the electricity usage events by estimating appliance operational states, aiming to extract the event-related sparse knowledge; ii) a novel knowledge-guided mechanism is established by fusing such state estimates of the appliance events into the RLF model, which can give particular focuses on the patterns of users' electricity consumption behaviors. Notably, ERKG can flexibly serve as a plug-in module to boost the capability of existing forecasting models by leveraging event response. In numerical experiments, extensive comparisons and ablation studies have verified the effectiveness of our ERKG, e.g., over 8% MAE can be reduced on the tested state-of-the-art forecasting models.
Joint Source-Channel Optimization for UAV Video Coding and Transmission
Aug 13, 2024
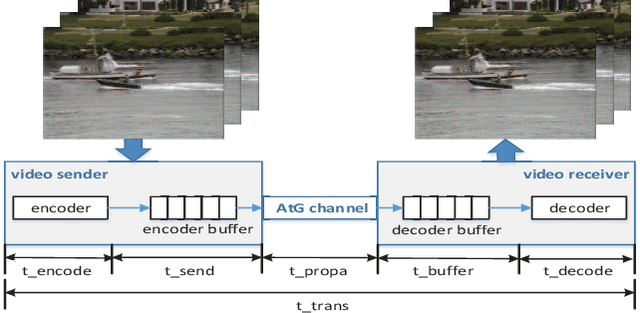
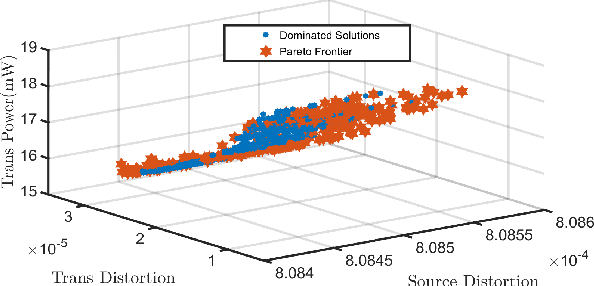
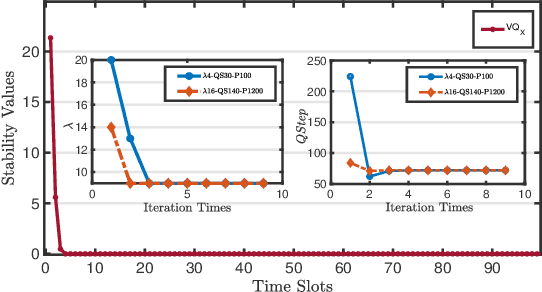
This paper is concerned with unmanned aerial vehicle (UAV) video coding and transmission in scenarios such as emergency rescue and environmental monitoring. Unlike existing methods of modeling video source coding and channel transmission separately, we investigate the joint source-channel optimization issue for video coding and transmission. Particularly, we design eight-dimensional delay-power-rate-distortion models in terms of source coding and channel transmission and characterize the correlation between video coding and transmission, with which a joint source-channel optimization problem is formulated. Its objective is to minimize end-to-end distortion and UAV power consumption by optimizing fine-grained parameters related to UAV video coding and transmission. This problem is confirmed to be a challenging sequential-decision and non-convex optimization problem. We therefore decompose it into a family of repeated optimization problems by Lyapunov optimization and design an approximate convex optimization scheme with provable performance guarantees to tackle these problems. Based on the theoretical transformation, we propose a Lyapunov repeated iteration (LyaRI) algorithm. Extensive experiments are conducted to comprehensively evaluate the performance of LyaRI. Experimental results indicate that compared to its counterparts, LyaRI is robust to initial settings of encoding parameters, and the variance of its achieved encoding bitrate is reduced by 47.74%.
Towards Optimal Customized Architecture for Heterogeneous Federated Learning with Contrastive Cloud-Edge Model Decoupling
Mar 04, 2024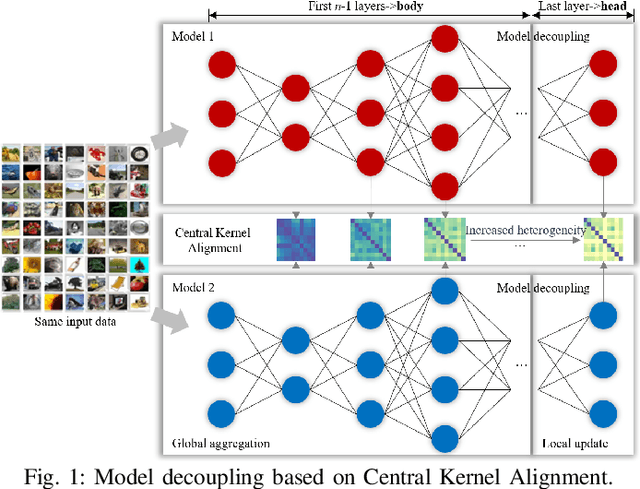
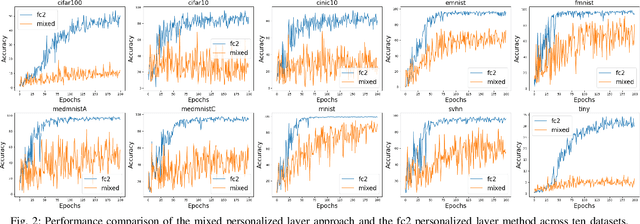
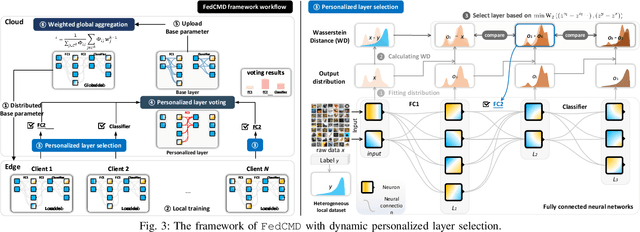
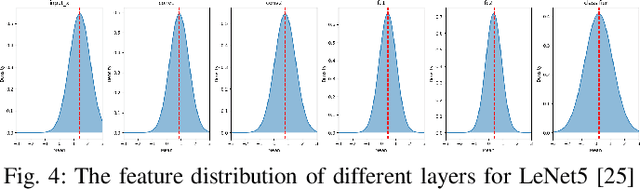
Federated learning, as a promising distributed learning paradigm, enables collaborative training of a global model across multiple network edge clients without the need for central data collecting. However, the heterogeneity of edge data distribution drags the model towards the local minima, which can be distant from the global optimum. Such heterogeneity often leads to slow convergence and substantial communication overhead. To address these issues, we propose a novel federated learning framework called FedCMD, a model decoupling tailored to the Cloud-edge supported federated learning that separates deep neural networks into a body for capturing shared representations in Cloud and a personalized head for migrating data heterogeneity. Our motivation is that, by the deep investigation of the performance of selecting different neural network layers as the personalized head, we found rigidly assigning the last layer as the personalized head in current studies is not always optimal. Instead, it is necessary to dynamically select the personalized layer that maximizes the training performance by taking the representation difference between neighbor layers into account. To find the optimal personalized layer, we utilize the low-dimensional representation of each layer to contrast feature distribution transfer and introduce a Wasserstein-based layer selection method, aimed at identifying the best-match layer for personalization. Additionally, a weighted global aggregation algorithm is proposed based on the selected personalized layer for the practical application of FedCMD. Extensive experiments on ten benchmarks demonstrate the efficiency and superior performance of our solution compared with nine state-of-the-art solutions. All code and results are available at https://github.com/elegy112138/FedCMD.
QoE-Driven Video Transmission: Energy-Efficient Multi-UAV Network Optimization
Jul 23, 2023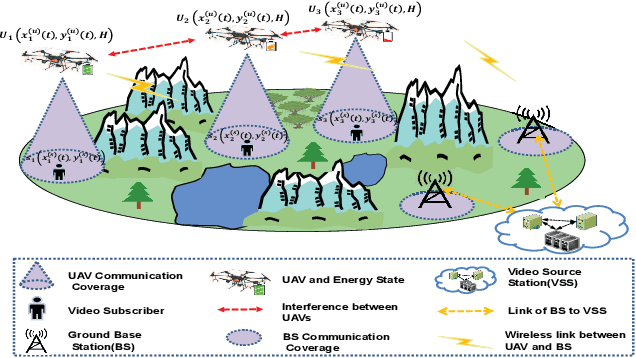
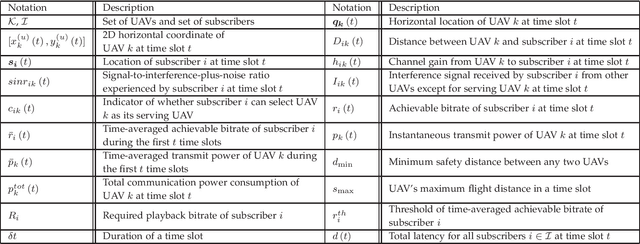
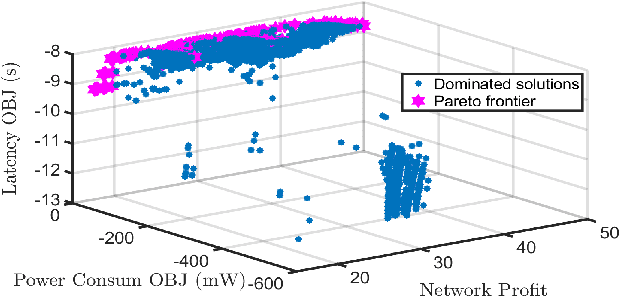
This paper is concerned with the issue of improving video subscribers' quality of experience (QoE) by deploying a multi-unmanned aerial vehicle (UAV) network. Different from existing works, we characterize subscribers' QoE by video bitrates, latency, and frame freezing and propose to improve their QoE by energy-efficiently and dynamically optimizing the multi-UAV network in terms of serving UAV selection, UAV trajectory, and UAV transmit power. The dynamic multi-UAV network optimization problem is formulated as a challenging sequential-decision problem with the goal of maximizing subscribers' QoE while minimizing the total network power consumption, subject to some physical resource constraints. We propose a novel network optimization algorithm to solve this challenging problem, in which a Lyapunov technique is first explored to decompose the sequential-decision problem into several repeatedly optimized sub-problems to avoid the curse of dimensionality. To solve the sub-problems, iterative and approximate optimization mechanisms with provable performance guarantees are then developed. Finally, we design extensive simulations to verify the effectiveness of the proposed algorithm. Simulation results show that the proposed algorithm can effectively improve the QoE of subscribers and is 66.75\% more energy-efficient than benchmarks.
Cross-modal Orthogonal High-rank Augmentation for RGB-Event Transformer-trackers
Jul 09, 2023This paper addresses the problem of cross-modal object tracking from RGB videos and event data. Rather than constructing a complex cross-modal fusion network, we explore the great potential of a pre-trained vision Transformer (ViT). Particularly, we delicately investigate plug-and-play training augmentations that encourage the ViT to bridge the vast distribution gap between the two modalities, enabling comprehensive cross-modal information interaction and thus enhancing its ability. Specifically, we propose a mask modeling strategy that randomly masks a specific modality of some tokens to enforce the interaction between tokens from different modalities interacting proactively. To mitigate network oscillations resulting from the masking strategy and further amplify its positive effect, we then theoretically propose an orthogonal high-rank loss to regularize the attention matrix. Extensive experiments demonstrate that our plug-and-play training augmentation techniques can significantly boost state-of-the-art one-stream and twostream trackers to a large extent in terms of both tracking precision and success rate. Our new perspective and findings will potentially bring insights to the field of leveraging powerful pre-trained ViTs to model cross-modal data. The code will be publicly available.
Networking of Internet of UAVs: Challenges and Intelligent Approaches
Nov 13, 2021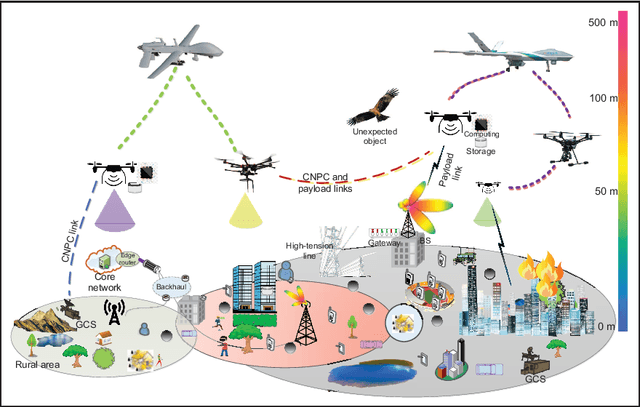
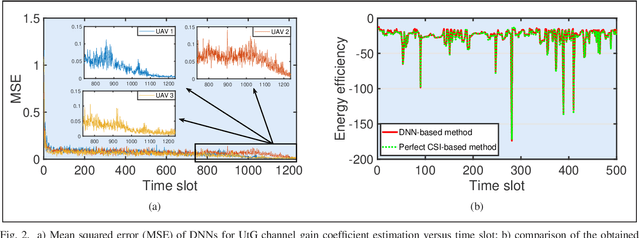
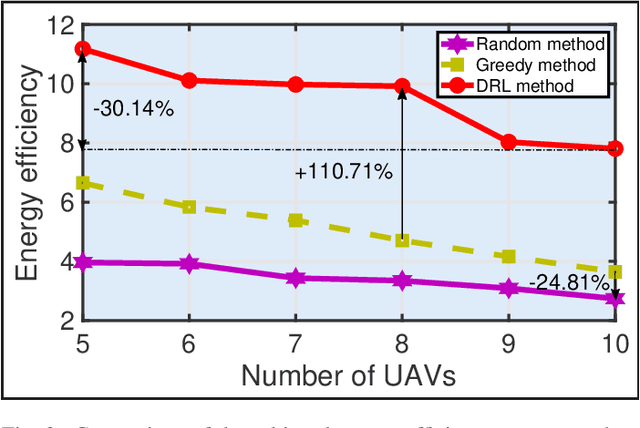
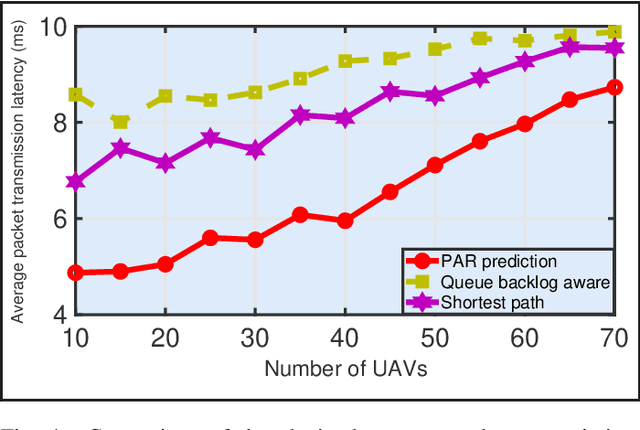
Internet of unmanned aerial vehicle (I-UAV) networks promise to accomplish sensing and transmission tasks quickly, robustly, and cost-efficiently via effective cooperation among UAVs. To achieve the promising benefits, the crucial I-UAV networking issue should be tackled. This article argues that I-UAV networking can be classified into three categories, quality-of-service (QoS) driven networking, quality-of-experience (QoE) driven networking, and situation aware networking. Each category of networking poses emerging challenges which have severe effects on the safe and efficient accomplishment of I-UAV missions. This article elaborately analyzes these challenges and expounds on the corresponding intelligent approaches to tackle the I-UAV networking issue. Besides, considering the uplifting effect of extending the scalability of I-UAV networks through cooperating with high altitude platforms (HAPs), this article gives an overview of the integrated HAP and I-UAV networks and presents the corresponding networking challenges and intelligent approaches.